Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
作者: Xiaowen Sun, Xufeng Zhao, Jae Hee Lee, Wenhao Lu, Matthias Kerzel, Stefan Wermter
分类: cs.AI, cs.CL, cs.RO
发布日期: 2024-06-14 (更新: 2024-10-16)
备注: ICANN24, Switzerland
🔗 代码/项目: GITHUB
💡 一句话要点
提出OSSA,利用预训练模型实现机器人对物体状态敏感的任务规划
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人任务规划 物体状态感知 大型语言模型 视觉-语言模型 预训练模型 多模态学习 神经机器人
📋 核心要点
- 现有机器人任务规划方法难以有效感知和利用物体状态信息,导致规划结果不够智能和灵活。
- OSSA利用预训练的LLM和VLM,使机器人能够理解物体状态并生成相应的任务规划,提升了规划的智能化水平。
- 实验结果表明,基于VLM的单体OSSA模型在物体状态敏感的任务规划中表现优于模块化模型,验证了方法的有效性。
📝 摘要(中文)
物体的状态反映了其当前的情况,对于机器人的任务规划和操作至关重要。然而,检测物体状态并为机器人生成状态敏感的规划仍然具有挑战性。最近,预训练的大型语言模型(LLMs)和视觉-语言模型(VLMs)在生成规划方面表现出了令人印象深刻的能力。但据我们所知,几乎没有研究探讨LLM或VLM是否也能生成物体状态敏感的规划。为了研究这个问题,我们引入了一个物体状态敏感代理(OSSA),这是一个由预训练神经网络驱动的任务规划代理。我们为OSSA提出了两种方法:(i)一个由预训练的视觉处理模块(密集字幕模型,DCM)和自然语言处理模型(LLM)组成的模块化模型,以及(ii)一个仅由VLM组成的单体模型。为了定量评估这两种方法的性能,我们使用了以清理桌面为任务的桌面场景。我们贡献了一个考虑物体状态的多模态基准数据集。我们的结果表明,这两种方法都可以用于物体状态敏感的任务,但单体方法优于模块化方法。OSSA的代码可在https://github.com/Xiao-wen-Sun/OSSA获取。
🔬 方法详解
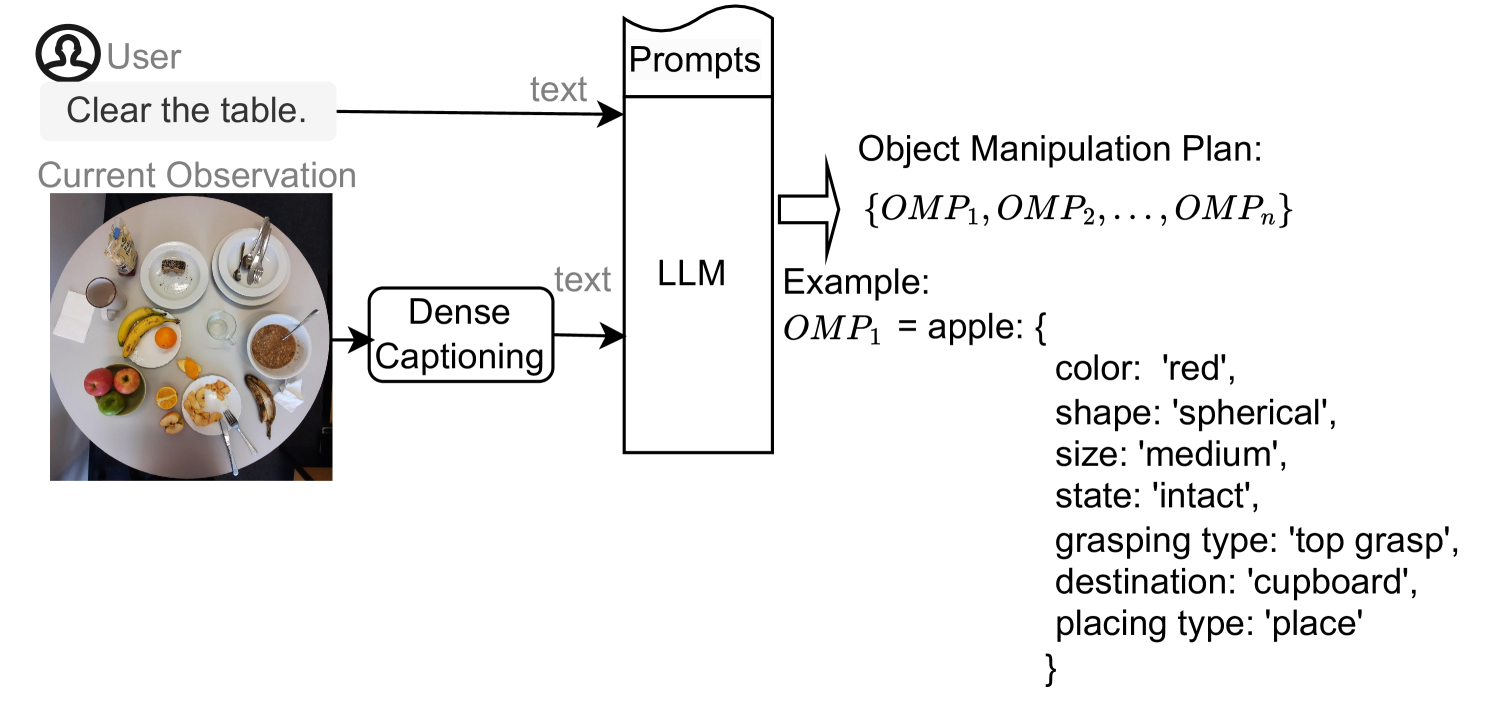
问题定义:论文旨在解决机器人任务规划中物体状态感知和利用不足的问题。现有方法通常忽略或简化物体状态,导致机器人无法根据物体状态的变化做出相应的规划调整。例如,机器人需要区分“空的”和“满的”杯子,才能决定是拿起杯子还是倒掉里面的东西。这种对物体状态的忽略限制了机器人在复杂环境中的适应性和智能水平。
核心思路:论文的核心思路是利用预训练的LLM和VLM,赋予机器人理解和推理物体状态的能力。通过将视觉信息(物体图像)和语言信息(任务描述)相结合,模型能够识别物体状态,并根据状态生成相应的任务规划。这种方法避免了手动设计规则或状态表示的复杂性,充分利用了预训练模型强大的知识和推理能力。
技术框架:OSSA包含两种实现方式:模块化模型和单体模型。模块化模型由DCM(Dense Captioning Model)和LLM组成,DCM负责生成图像的密集描述,LLM则根据图像描述和任务指令生成任务规划。单体模型则直接使用VLM,将图像和任务指令输入VLM,由VLM直接生成任务规划。两种模型都以端到端的方式进行训练或微调。
关键创新:论文的关键创新在于将预训练的LLM和VLM应用于物体状态敏感的任务规划。与传统方法相比,OSSA无需手动设计状态表示或规则,而是通过预训练模型自动学习物体状态和任务规划之间的关系。此外,论文还提出了一个多模态基准数据集,用于评估物体状态敏感的任务规划算法。
关键设计:DCM采用标准的密集字幕模型结构,用于生成图像的密集描述。LLM可以使用各种预训练的语言模型,如GPT-3或T5。VLM可以使用CLIP或类似的模型。损失函数通常采用交叉熵损失或类似的语言生成损失函数。数据集包含带有状态标注的桌面场景图像和相应的任务规划。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于VLM的单体OSSA模型在物体状态敏感的任务规划中表现优于模块化模型。具体而言,单体模型在准确性和效率方面都优于模块化模型,这表明VLM能够更好地整合视觉和语言信息,从而生成更有效的任务规划。此外,论文提出的多模态基准数据集为评估物体状态敏感的任务规划算法提供了一个有价值的平台。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂任务规划的场景,例如智能家居、仓储物流、医疗辅助等。通过赋予机器人感知和理解物体状态的能力,可以显著提高机器人的自主性和适应性,使其能够更好地完成各种任务。未来的研究方向包括探索更复杂的物体状态表示、更有效的模型训练方法以及更广泛的应用场景。
📄 摘要(原文)
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at https://github.com/Xiao-wen-Sun/OSSA