OSPC: Detecting Harmful Memes with Large Language Model as a Catalyst
作者: Jingtao Cao, Zheng Zhang, Hongru Wang, Bin Liang, Hao Wang, Kam-Fai Wong
分类: cs.AI, cs.CL, cs.CV
发布日期: 2024-06-14
💡 一句话要点
OSPC:利用大语言模型作为催化剂检测有害Meme
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 有害Meme检测 大语言模型 多模态学习 图像描述 光学字符识别
📋 核心要点
- 现有方法难以有效识别多语言、文化背景下Meme中隐藏的社会偏见和歧视。
- 该论文提出了一种结合图像描述、OCR和大语言模型的有害Meme检测方法,提升了对Meme内容理解的深度和广度。
- 实验结果表明,该方法在AUROC和准确率上显著优于现有基线模型,并在在线安全奖挑战赛中获得第一名。
📝 摘要(中文)
Meme在互联网上迅速传播个人观点和立场,但也带来了传播社会偏见和歧视的重大挑战。本研究提出了一种检测有害Meme的新方法,特别是在新加坡多元文化和多语言的背景下。我们的方法整合了图像描述、光学字符识别(OCR)和大语言模型(LLM)分析,以全面理解和分类有害Meme。利用BLIP模型进行图像描述,PP-OCR和TrOCR进行多语言文本识别,以及Qwen LLM进行细致的语言理解,我们的系统能够识别用英语、中文、马来语和泰米尔语创建的Meme中的有害内容。为了提高系统性能,我们利用GPT-4V标注的额外数据对我们的方法进行了微调,旨在将GPT-4V对有害Meme的理解能力提炼到我们的系统中。我们的框架在AI Singapore主办的在线安全奖挑战赛的公共排行榜上名列第一,AUROC为0.7749,准确率为0.7087,显著领先于其他团队。值得注意的是,我们的方法优于之前的基准,FLAVA的AUROC为0.5695,VisualBERT的AUROC为0.5561。
🔬 方法详解
问题定义:论文旨在解决有害Meme的自动检测问题,尤其是在多语言和多元文化背景下。现有方法在理解Meme的复杂语义和识别隐藏的偏见方面存在不足,难以有效应对不同语言和文化背景下的Meme内容。
核心思路:论文的核心思路是利用大语言模型(LLM)强大的语言理解能力,结合图像描述和OCR技术,全面分析Meme的图像和文本信息,从而更准确地识别有害内容。通过将多模态信息输入LLM,可以更好地捕捉Meme中的细微语义和潜在的社会偏见。
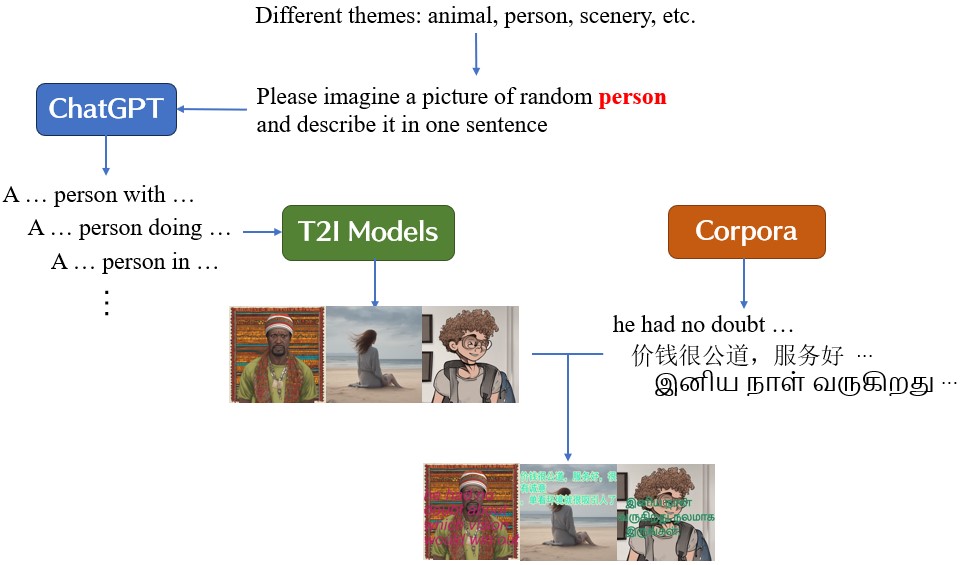
技术框架:该方法的技术框架主要包括三个阶段:1) 图像描述阶段,使用BLIP模型生成Meme图像的文本描述;2) 文本识别阶段,使用PP-OCR和TrOCR模型识别Meme中的文本内容,支持多种语言;3) 语言理解阶段,使用Qwen LLM对图像描述和识别出的文本进行分析,判断Meme是否包含有害内容。此外,还使用GPT-4V标注的数据对系统进行微调,以提升其对有害Meme的识别能力。
关键创新:该方法最重要的技术创新点在于将大语言模型应用于有害Meme检测,并结合图像描述和OCR技术,实现了对Meme内容的多模态理解。与传统的基于视觉特征或文本特征的方法相比,该方法能够更全面、更深入地理解Meme的语义,从而更准确地识别有害内容。此外,利用GPT-4V进行数据增强和模型微调也是一个创新点。
关键设计:在图像描述阶段,使用了预训练的BLIP模型,并根据具体任务进行了微调。在文本识别阶段,使用了PP-OCR和TrOCR模型,以支持多种语言的文本识别。在语言理解阶段,使用了Qwen LLM,并采用了合适的prompt工程来引导LLM进行有害内容判断。此外,还设计了合适的损失函数和训练策略,以优化模型的性能。
🖼️ 关键图片

📊 实验亮点
该方法在AI Singapore主办的在线安全奖挑战赛中取得了显著成果,AUROC达到0.7749,准确率达到0.7087,排名第一,显著优于其他参赛队伍。同时,该方法也超越了之前的基线模型,如FLAVA (AUROC 0.5695) 和 VisualBERT (AUROC 0.5561),证明了其在有害Meme检测方面的有效性。
🎯 应用场景
该研究成果可应用于在线社交平台的内容审核,自动识别和过滤有害Meme,从而减少社会偏见和歧视的传播。此外,该方法还可以应用于舆情分析、网络安全等领域,帮助识别和应对潜在的网络风险。未来,该技术有望进一步发展,应用于更广泛的多模态内容理解和安全领域。
📄 摘要(原文)
Memes, which rapidly disseminate personal opinions and positions across the internet, also pose significant challenges in propagating social bias and prejudice. This study presents a novel approach to detecting harmful memes, particularly within the multicultural and multilingual context of Singapore. Our methodology integrates image captioning, Optical Character Recognition (OCR), and Large Language Model (LLM) analysis to comprehensively understand and classify harmful memes. Utilizing the BLIP model for image captioning, PP-OCR and TrOCR for text recognition across multiple languages, and the Qwen LLM for nuanced language understanding, our system is capable of identifying harmful content in memes created in English, Chinese, Malay, and Tamil. To enhance the system's performance, we fine-tuned our approach by leveraging additional data labeled using GPT-4V, aiming to distill the understanding capability of GPT-4V for harmful memes to our system. Our framework achieves top-1 at the public leaderboard of the Online Safety Prize Challenge hosted by AI Singapore, with the AUROC as 0.7749 and accuracy as 0.7087, significantly ahead of the other teams. Notably, our approach outperforms previous benchmarks, with FLAVA achieving an AUROC of 0.5695 and VisualBERT an AUROC of 0.5561.