Hierarchical Compression of Text-Rich Graphs via Large Language Models
作者: Shichang Zhang, Da Zheng, Jiani Zhang, Qi Zhu, Xiang song, Soji Adeshina, Christos Faloutsos, George Karypis, Yizhou Sun
分类: cs.SI, cs.AI
发布日期: 2024-06-13
💡 一句话要点
提出HiCom,通过层级压缩文本信息,提升LLM在富文本图上的节点分类性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 富文本图 层级压缩 大型语言模型 节点分类 图神经网络
📋 核心要点
- 现有图神经网络难以有效处理富文本图节点上的丰富文本信息,而大型语言模型虽然擅长文本理解,但难以编码图结构且计算复杂度高。
- HiCom的核心思想是通过层级压缩,将节点邻域内的文本信息组织成层级结构,逐步压缩文本,从而降低LLM的计算负担并保留文本上下文信息。
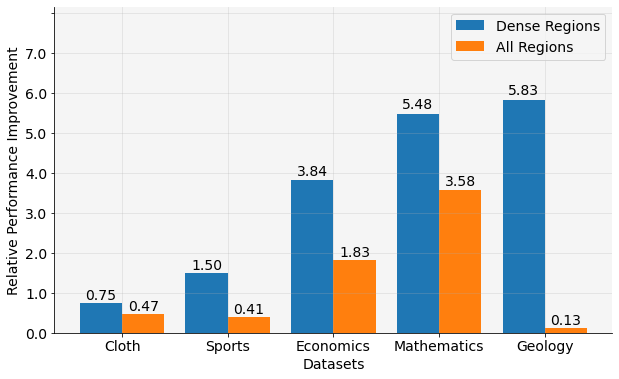
- 实验结果表明,HiCom在节点分类任务中优于GNN和LLM基线,尤其在图的密集区域的节点上表现突出,平均性能提升3.48%。
📝 摘要(中文)
本文提出了一种名为“层级压缩”(HiCom)的新方法,旨在将大型语言模型(LLM)的能力与富文本图的结构对齐。富文本图广泛存在于电子商务和学术图等数据挖掘场景中,其节点包含丰富的文本特征,并通过各种关系连接。HiCom通过将节点邻域内的文本信息组织成易于管理的层级结构,逐步压缩节点文本,从而结构化地处理文本。HiCom不仅保留了文本的上下文丰富性,还解决了LLM的计算挑战。实验结果表明,HiCom在电子商务和引文图上的节点分类任务中优于图神经网络(GNN)和LLM基线模型。HiCom在图的密集区域的节点上尤其有效,在五个数据集上平均性能提升3.48%,同时比LLM基线更高效。
🔬 方法详解
问题定义:论文旨在解决富文本图上的节点分类问题。现有方法,如图神经网络(GNNs),在处理图结构信息方面表现出色,但对节点上丰富的文本信息处理能力有限。直接使用大型语言模型(LLMs)处理节点文本虽然可以利用其强大的文本理解能力,但面临计算复杂度高,难以有效编码图结构的挑战。
核心思路:论文的核心思路是“层级压缩”(Hierarchical Compression)。通过将节点邻域内的文本信息组织成一个层级结构,然后逐层压缩文本信息,从而在降低计算复杂度的同时,保留关键的上下文信息。这样既能利用LLM的文本理解能力,又能使其适应图结构的特点。
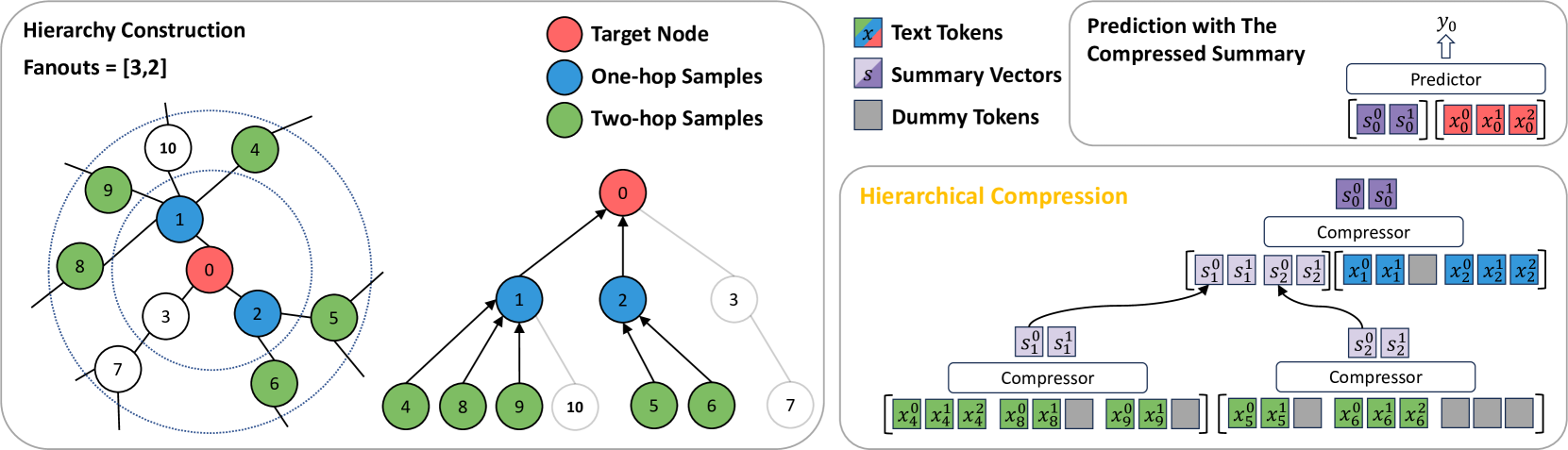
技术框架:HiCom的整体框架包含以下几个主要阶段:1) 邻域文本构建:为每个节点构建其邻域内的文本信息,形成一个文本集合。2) 层级结构构建:将邻域文本集合组织成一个层级结构,例如树状结构,其中叶子节点是原始文本,中间节点是其子节点的摘要。3) 层级压缩:从叶子节点开始,逐层向上使用LLM生成摘要,压缩文本信息。4) 节点表示学习:利用压缩后的文本信息和图结构信息,学习节点的表示向量。5) 节点分类:使用学习到的节点表示向量进行节点分类。
关键创新:HiCom的关键创新在于其层级压缩的思想。与直接使用LLM处理所有邻域文本相比,HiCom通过层级结构和逐步压缩,显著降低了计算复杂度,使得LLM能够应用于大规模富文本图。此外,层级结构也保留了文本的上下文信息,避免了信息丢失。
关键设计:在层级结构构建方面,可以使用不同的策略,例如基于图结构的聚类或基于文本相似度的聚类。在层级压缩方面,可以使用不同的LLM和摘要生成策略。论文中可能使用了特定的LLM模型和prompt工程来优化摘要质量。损失函数的设计可能包括节点分类的交叉熵损失,以及一些正则化项来约束节点表示的学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HiCom在五个数据集上,相较于GNN和LLM基线模型,在节点分类任务上取得了显著的性能提升。尤其是在图的密集区域的节点上,HiCom平均性能提升了3.48%,同时比LLM基线模型更高效。这些结果验证了HiCom在处理富文本图上的有效性和效率。
🎯 应用场景
HiCom在电子商务、学术研究、社交网络等领域具有广泛的应用前景。例如,在电商图中,可以利用HiCom对商品进行分类,推荐相似商品;在学术图中,可以对论文进行分类,发现研究热点;在社交网络中,可以对用户进行分类,推荐好友或兴趣小组。HiCom能够有效利用富文本信息,提升图机器学习模型的性能,为相关应用带来实际价值。
📄 摘要(原文)
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.