ResearchArena: Benchmarking Large Language Models' Ability to Collect and Organize Information as Research Agents
作者: Hao Kang, Chenyan Xiong
分类: cs.AI, cs.CL, cs.IR
发布日期: 2024-06-13 (更新: 2025-09-07)
🔗 代码/项目: GITHUB
💡 一句话要点
ResearchArena:评估大语言模型作为研究代理的信息收集与组织能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 学术调研 信息检索 知识组织 基准测试
📋 核心要点
- 现有大语言模型在特定领域分析任务(如学术调研)中表现不足,缺乏有效的信息收集和组织能力。
- ResearchArena基准通过模拟学术调研过程,分阶段评估LLM的信息发现、选择和组织能力,并提供思维导图构建的奖励任务。
- 初步实验表明,现有LLM在ResearchArena上的表现不如关键词检索方法,但DeepSeek-R1等模型展现出一定的零样本潜力。
📝 摘要(中文)
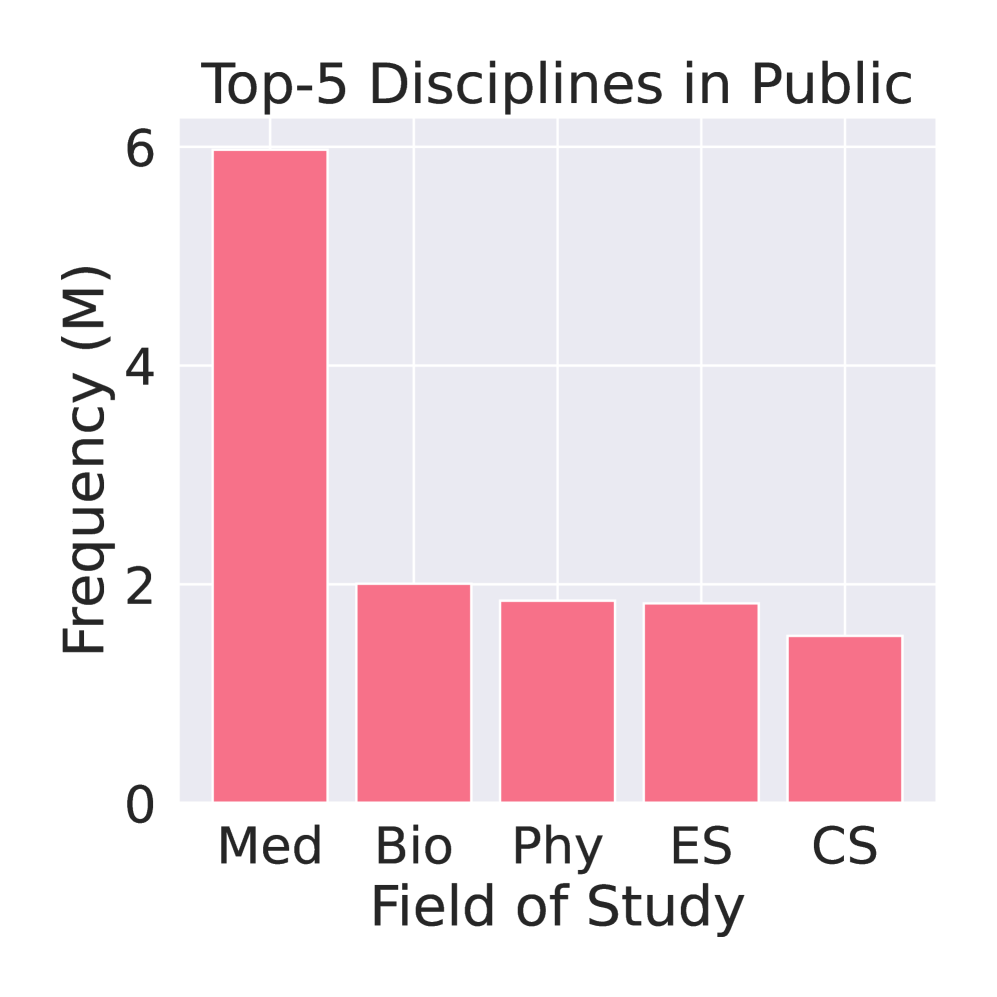
大型语言模型(LLMs)在许多自然语言处理任务中表现出色,但在领域特定的分析任务(如进行研究调查)中面临挑战。本研究引入了ResearchArena,这是一个旨在评估LLMs进行学术调查能力(学术研究的基础步骤)的基准。ResearchArena将该过程建模为三个阶段:(1)信息发现,识别相关文献;(2)信息选择,评估论文的相关性和影响力;(3)信息组织,将知识构建成层次结构框架,如思维导图。值得注意的是,思维导图构建被视为一项奖励任务,反映了其在调查报告撰写中的补充作用。为了支持这些评估,我们构建了一个包含1200万篇全文的学术论文和7900篇调查论文的离线环境。为了确保符合伦理规范,我们不重新分发受版权保护的材料;而是提供代码以从Semantic Scholar Open Research Corpus(S2ORC)构建环境。初步评估表明,基于LLM的方法的性能不如简单的基于关键词的检索方法,但最近的推理模型(如DeepSeek-R1)表现出稍好的零样本性能。这些结果强调了在自主研究中推进LLM的巨大机会。我们开源了用于构建ResearchArena基准的代码,地址为https://github.com/cxcscmu/ResearchArena。
🔬 方法详解
问题定义:论文旨在评估和提升大型语言模型在学术研究中的自主调研能力。现有方法在处理领域特定、分析性强的任务(如文献综述)时,信息检索和组织效率较低,难以胜任研究代理的角色。
核心思路:论文将学术调研过程分解为信息发现、信息选择和信息组织三个阶段,并构建相应的评估基准。通过模拟研究人员的调研流程,系统性地考察LLM在各个环节的表现,从而发现其优势与不足。
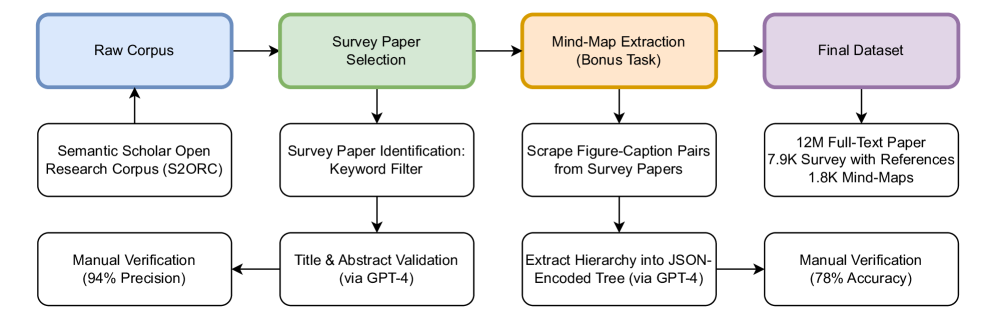
技术框架:ResearchArena基准包含以下几个关键组成部分:1)大规模离线学术论文数据集(基于S2ORC构建);2)学术调研流程建模(信息发现、选择、组织);3)评估指标体系(衡量各阶段的性能);4)可选的思维导图构建任务。整个流程旨在模拟研究人员进行文献综述的过程。
关键创新:该研究的核心创新在于构建了一个专门用于评估LLM自主调研能力的基准测试环境。与以往侧重于通用NLP能力的评估不同,ResearchArena更加关注LLM在特定领域、复杂任务中的表现,并提供了更细粒度的评估指标。
关键设计:ResearchArena的关键设计包括:1)数据集的构建方式,确保数据规模和质量;2)流程建模的合理性,尽可能贴近真实科研场景;3)评估指标的选择,能够有效区分不同模型的性能差异。此外,思维导图构建任务的设计,鼓励模型进行更高级的知识组织和推理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有LLM在ResearchArena基准上的表现不如传统的关键词检索方法,这表明LLM在信息检索和组织方面仍有很大的提升空间。然而,DeepSeek-R1等新型推理模型展现出一定的零样本学习能力,预示着LLM在自主调研方面具有潜在的优势。
🎯 应用场景
该研究成果可应用于开发智能科研助手,辅助研究人员进行文献综述、课题调研等工作。通过提升LLM的自主调研能力,可以显著提高科研效率,加速知识发现和创新。未来,该技术还可应用于智能咨询、决策支持等领域。
📄 摘要(原文)
Large language models (LLMs) excel across many natural language processing tasks but face challenges in domain-specific, analytical tasks such as conducting research surveys. This study introduces ResearchArena, a benchmark designed to evaluate LLMs' capabilities in conducting academic surveys -- a foundational step in academic research. ResearchArena models the process in three stages: (1) information discovery, identifying relevant literature; (2) information selection, evaluating papers' relevance and impact; and (3) information organization, structuring knowledge into hierarchical frameworks such as mind-maps. Notably, mind-map construction is treated as a bonus task, reflecting its supplementary role in survey-writing. To support these evaluations, we construct an offline environment of 12M full-text academic papers and 7.9K survey papers. To ensure ethical compliance, we do not redistribute copyrighted materials; instead, we provide code to construct the environment from the Semantic Scholar Open Research Corpus (S2ORC). Preliminary evaluations reveal that LLM-based approaches underperform compared to simpler keyword-based retrieval methods, though recent reasoning models such as DeepSeek-R1 show slightly better zero-shot performance. These results underscore significant opportunities for advancing LLMs in autonomous research. We open-source the code to construct the ResearchArena benchmark at https://github.com/cxcscmu/ResearchArena.