Learning Reward and Policy Jointly from Demonstration and Preference Improves Alignment
作者: Chenliang Li, Siliang Zeng, Zeyi Liao, Jiaxiang Li, Dongyeop Kang, Alfredo Garcia, Mingyi Hong
分类: cs.AI, cs.HC, cs.RO
发布日期: 2024-06-11 (更新: 2024-11-29)
💡 一句话要点
提出AIHF,通过联合学习奖励和策略,提升人类对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人类反馈强化学习 奖励模型 策略优化 对齐 单阶段学习
📋 核心要点
- 现有RLHF等方法将对齐任务分解为多个阶段,导致数据利用率低和奖励模型与策略分布不匹配。
- AIHF是一种单阶段方法,它整合人类偏好和演示数据,联合训练奖励模型和策略。
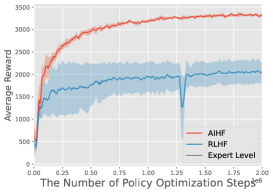
- 实验表明,AIHF在LLM和机器人控制任务中显著优于RLHF和DPO,尤其是在偏好数据有限时。
📝 摘要(中文)
对齐人类偏好和价值是构建现代基础模型和具身智能的重要需求。然而,诸如基于人类反馈的强化学习(RLHF)等流行方法将任务分解为连续的阶段,例如监督微调(SFT)、奖励建模(RM)和强化学习(RL),每个阶段执行一个特定的学习任务。这种顺序方法导致严重的问题,例如数据利用率不足以及学习到的奖励模型和生成的策略之间的分布不匹配,最终导致较差的对齐性能。我们开发了一种名为“通过集成人类反馈进行对齐”(AIHF)的单阶段方法,能够整合人类偏好和演示来训练奖励模型和策略。所提出的方法允许一套高效的算法,可以轻松地简化为并利用流行的对齐算法,例如RLHF和直接策略优化(DPO),并且只需要对现有的对齐流程进行较小的更改。我们通过涉及LLM中的对齐问题和MuJoCo中的机器人控制问题的广泛实验证明了所提出解决方案的效率。我们观察到,所提出的解决方案优于现有的对齐算法(例如RLHF和DPO)很大幅度,尤其是在高质量偏好数据的数量相对有限时。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法通常采用多阶段流程,包括监督微调(SFT)、奖励建模(RM)和强化学习(RL)。这种分离的训练方式导致数据利用率低下,并且学习到的奖励模型与最终策略之间存在分布差异,从而影响对齐效果。核心问题是如何更有效地利用人类反馈数据,并避免多阶段训练带来的问题,以提高模型与人类偏好的一致性。
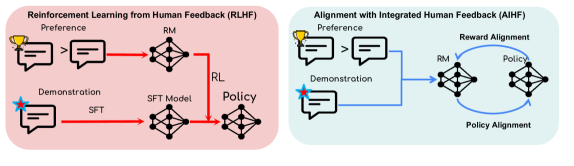
核心思路:AIHF的核心思路是将奖励模型和策略的学习整合到一个单阶段的训练过程中。通过同时优化奖励函数和策略,AIHF能够更有效地利用人类偏好和演示数据,避免了多阶段训练中可能出现的分布漂移问题。这种联合学习的方式旨在提高模型与人类意图的对齐程度。
技术框架:AIHF方法的核心在于构建一个能够同时学习奖励模型和策略的框架。该框架接收人类偏好和演示数据作为输入,通过一个集成的优化过程,同时更新奖励模型和策略。具体流程可能涉及:1) 定义一个联合损失函数,该函数同时考虑奖励预测的准确性和策略的性能;2) 使用梯度下降或其他优化算法,迭代更新奖励模型和策略的参数;3) 在训练过程中,利用人类偏好数据来指导奖励模型的学习,并利用演示数据来引导策略的探索。
关键创新:AIHF的关键创新在于其单阶段的联合学习方法。与传统的RLHF方法相比,AIHF避免了多阶段训练带来的数据利用率低和分布漂移问题。通过同时优化奖励模型和策略,AIHF能够更有效地利用人类反馈数据,并提高模型与人类意图的对齐程度。此外,AIHF框架可以兼容现有的对齐算法,如RLHF和DPO,只需进行少量修改即可集成。
关键设计:AIHF的关键设计包括:1) 联合损失函数的设计,需要平衡奖励预测的准确性和策略的性能;2) 优化算法的选择,需要考虑计算效率和收敛性;3) 人类偏好数据的利用方式,例如,可以使用对比学习或排序学习等方法来训练奖励模型;4) 演示数据的利用方式,例如,可以使用行为克隆或模仿学习等方法来引导策略的探索。具体的网络结构和参数设置需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
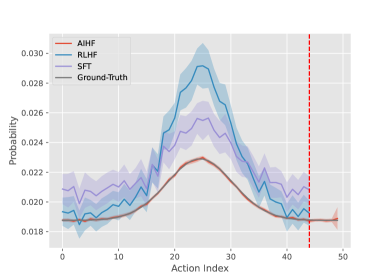
实验结果表明,AIHF在LLM和机器人控制任务中显著优于现有的对齐算法,如RLHF和DPO。尤其是在高质量偏好数据有限的情况下,AIHF的优势更加明显。具体的性能提升幅度取决于具体的任务和数据集,但总体而言,AIHF能够显著提高模型与人类意图的对齐程度。
🎯 应用场景
AIHF方法具有广泛的应用前景,包括大型语言模型的对齐、机器人控制、推荐系统等领域。通过更有效地利用人类反馈数据,AIHF可以帮助构建更符合人类意图和价值观的智能系统。例如,在LLM中,AIHF可以用于训练更安全、更可靠的对话模型;在机器人控制中,AIHF可以用于训练能够完成复杂任务的自主机器人。
📄 摘要(原文)
Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.