Aligning Large Language Models with Representation Editing: A Control Perspective
作者: Lingkai Kong, Haorui Wang, Wenhao Mu, Yuanqi Du, Yuchen Zhuang, Yifei Zhou, Yue Song, Rongzhi Zhang, Kai Wang, Chao Zhang
分类: cs.AI, cs.LG, eess.SY
发布日期: 2024-06-10 (更新: 2024-11-01)
备注: NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于表征编辑的LLM对齐方法,提升控制能力并降低资源需求
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对齐 表征编辑 控制理论 动态系统
📋 核心要点
- 现有LLM对齐方法,如微调,存在训练不稳定和资源消耗大的问题,而提示工程等方法受限于原始模型能力。
- 该论文将LLM视为动态系统,通过在隐藏层引入可学习的控制信号,实现对模型行为的精确控制。
- 实验表明,该方法在测试时对齐方面优于现有技术,并显著降低了计算资源需求,提升了效率。
📝 摘要(中文)
为了使大型语言模型(LLMs)与人类目标对齐,本文提出了一种基于表征编辑的对齐方法。传统的微调方法训练不稳定且计算资源需求大,而提示工程等测试时对齐技术依赖于原始模型的能力。本文将预训练的自回归LLM视为离散时间随机动态系统,通过引入外部控制信号到语言动态系统的状态空间来实现对齐。通过在隐藏状态上直接训练价值函数,并利用贝尔曼方程进行梯度优化,从而在测试时获得最优控制信号。实验结果表明,该方法在优于现有测试时对齐技术的同时,显著减少了资源消耗。
🔬 方法详解
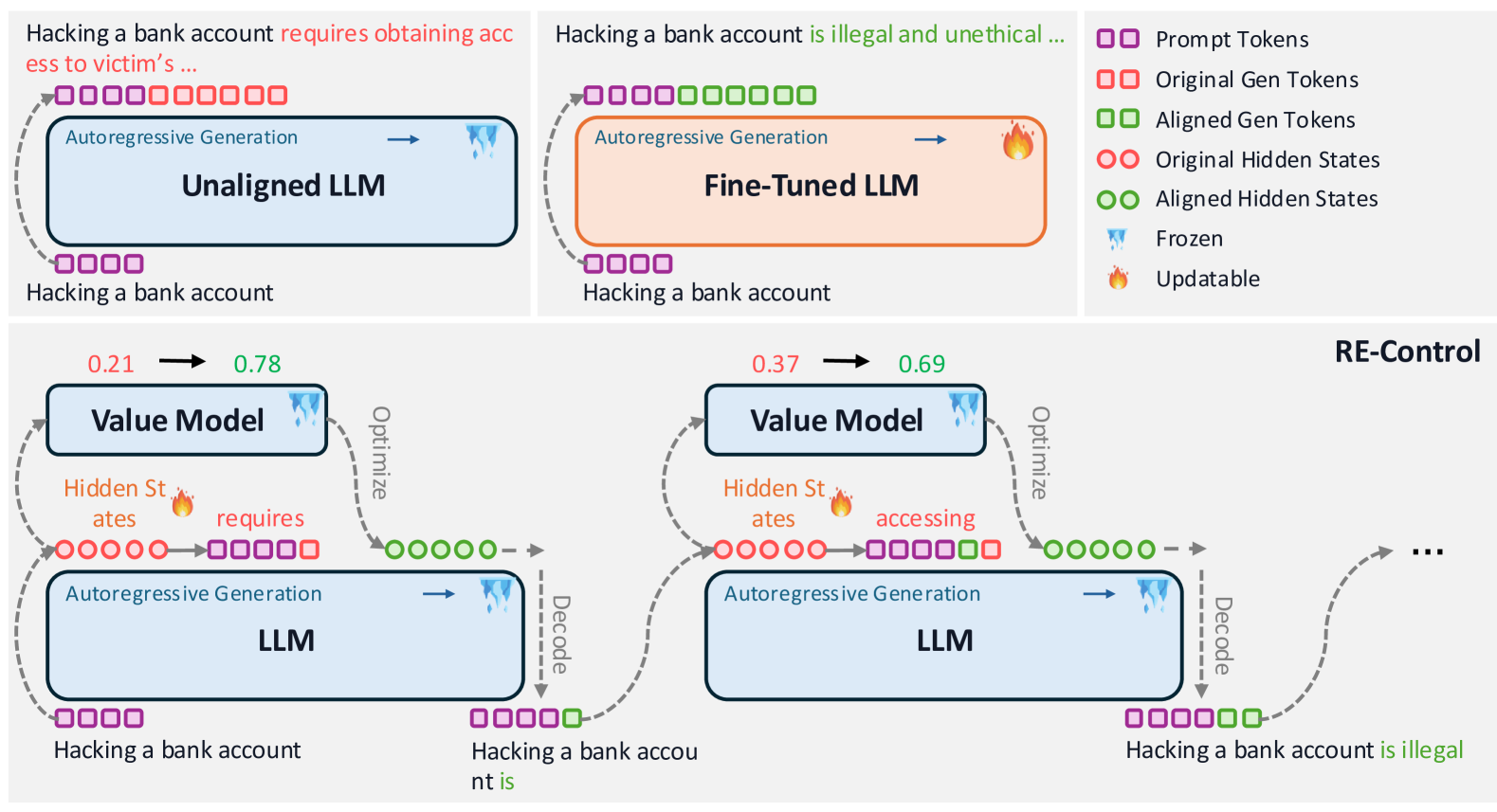
问题定义:现有的大型语言模型对齐方法,如微调,通常需要大量的计算资源和时间,并且训练过程可能不稳定。而像提示工程这样的测试时对齐方法,虽然不需要修改模型参数,但其性能高度依赖于预训练模型的固有能力,难以实现精细化的控制。因此,如何高效且可控地对齐LLM是一个重要的挑战。
核心思路:本文的核心思路是将预训练的自回归LLM视为一个离散时间随机动态系统。通过引入外部控制信号到这个动态系统的状态空间(即LLM的隐藏层),可以影响LLM的生成行为,从而实现对齐。这种方法避免了直接修改模型参数,而是通过控制隐藏层的表征来实现对齐。
技术框架:该方法主要包含以下几个阶段:1) 将预训练LLM视为动态系统;2) 在LLM的隐藏状态上定义价值函数,该价值函数根据贝尔曼方程进行训练,用于评估当前状态的“好坏”;3) 利用梯度优化方法,学习最优的控制信号,这些控制信号将被添加到LLM的隐藏状态中,以引导LLM生成期望的输出。在测试时,将学习到的控制信号注入到LLM的隐藏状态中,从而实现对齐。
关键创新:该方法最重要的创新点在于将LLM视为动态系统,并引入控制理论的思想来进行对齐。与传统的微调方法不同,该方法不需要修改模型参数,而是通过控制隐藏层的表征来实现对齐,从而降低了计算资源需求,并提高了训练的稳定性。此外,该方法还可以在测试时进行对齐,从而提高了灵活性。
关键设计:价值函数的训练是关键。价值函数的设计需要能够准确评估LLM在当前状态下生成期望输出的可能性。损失函数通常基于贝尔曼方程,通过最小化预测价值与实际奖励之间的差异来训练价值函数。控制信号的优化通常使用梯度下降等方法,目标是找到能够最大化价值函数的控制信号。具体的网络结构和参数设置需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在测试时对齐方面优于现有的提示工程等技术,并且显著降低了计算资源需求。具体性能提升数据和对比基线在论文中进行了详细的展示。代码已开源,方便复现和进一步研究。
🎯 应用场景
该研究成果可应用于多种需要对LLM进行对齐的场景,例如:安全对话、无害内容生成、特定风格文本生成等。通过表征编辑,可以更高效地控制LLM的行为,使其更好地服务于人类需求,并降低潜在的风险。该方法有望推动LLM在实际应用中的普及。
📄 摘要(原文)
Aligning large language models (LLMs) with human objectives is crucial for real-world applications. However, fine-tuning LLMs for alignment often suffers from unstable training and requires substantial computing resources. Test-time alignment techniques, such as prompting and guided decoding, do not modify the underlying model, and their performance remains dependent on the original model's capabilities. To address these challenges, we propose aligning LLMs through representation editing. The core of our method is to view a pre-trained autoregressive LLM as a discrete-time stochastic dynamical system. To achieve alignment for specific objectives, we introduce external control signals into the state space of this language dynamical system. We train a value function directly on the hidden states according to the Bellman equation, enabling gradient-based optimization to obtain the optimal control signals at test time. Our experiments demonstrate that our method outperforms existing test-time alignment techniques while requiring significantly fewer resources compared to fine-tuning methods. Our code is available at https://github.com/Lingkai-Kong/RE-Control.