ChatPCG: Large Language Model-Driven Reward Design for Procedural Content Generation
作者: In-Chang Baek, Tae-Hwa Park, Jin-Ha Noh, Cheong-Mok Bae, Kyung-Joong Kim
分类: cs.AI
发布日期: 2024-06-07
备注: 4 pages, 2 figures, accepted at IEEE Conference on Games 2024
💡 一句话要点
ChatPCG:基于大语言模型驱动的程序化内容生成奖励设计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序化内容生成 大语言模型 奖励设计 深度强化学习 游戏AI
📋 核心要点
- 游戏AI模型训练中的奖励设计高度依赖人工专家,需要创造性和工程技能,效率较低且成本较高。
- ChatPCG利用大语言模型理解游戏机制,自动生成针对特定游戏功能的奖励函数,降低了人工干预的需求。
- 实验表明,ChatPCG能够为多人游戏生成定制化内容,提升了内容生成的可访问性,并简化了游戏AI开发流程。
📝 摘要(中文)
本文提出了一种基于大语言模型(LLM)驱动的奖励设计框架ChatPCG,旨在解决游戏AI模型训练中奖励函数设计依赖人工专家的问题。ChatPCG利用LLM的人类水平洞察力和游戏专业知识,自动生成针对特定游戏功能的奖励。该框架与深度强化学习相结合,展示了其在多人游戏内容生成任务中的潜力。实验结果表明,该LLM能够理解游戏机制和内容生成任务,从而为特定游戏定制内容生成。这项研究不仅提高了内容生成的可访问性,还有助于简化游戏AI的开发流程。
🔬 方法详解
问题定义:现有游戏AI的内容生成任务中,奖励函数的设计主要依赖于人类专家,这需要大量的创造力和工程技能。这种人工设计过程耗时且成本高昂,并且难以保证奖励函数的最优性,限制了游戏AI的开发效率和内容生成的多样性。
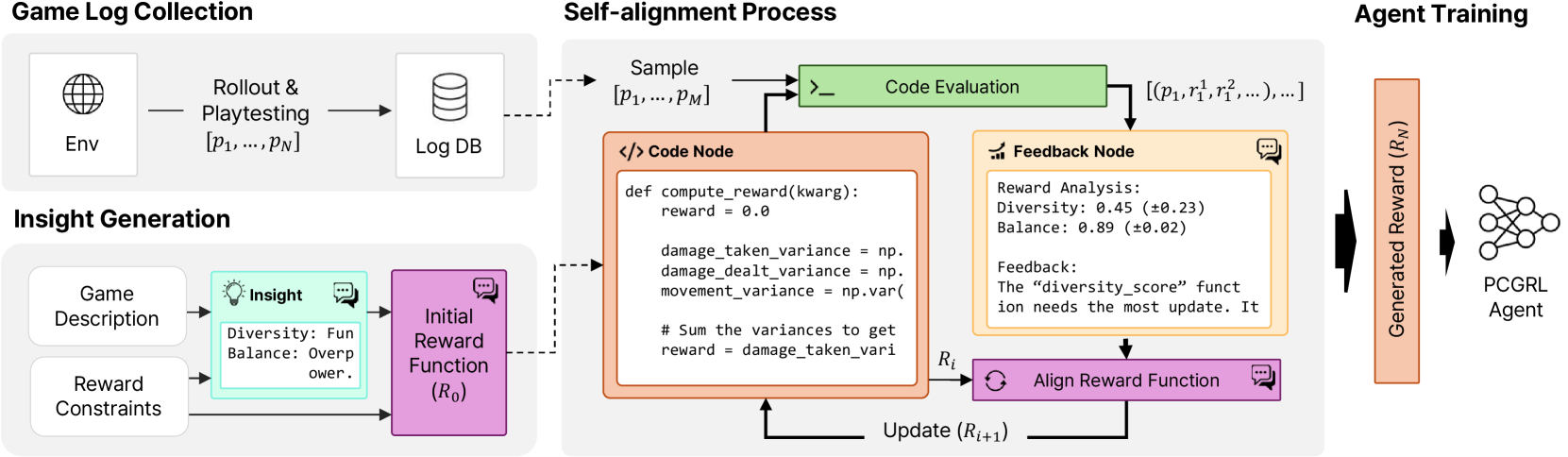
核心思路:ChatPCG的核心思路是利用大语言模型(LLM)的强大理解和生成能力,模拟人类专家的思维过程,自动生成针对特定游戏机制和内容生成目标的奖励函数。通过将LLM与深度强化学习相结合,实现游戏AI的自主学习和内容生成。
技术框架:ChatPCG框架主要包含以下几个模块:1) 游戏信息输入模块:接收游戏规则、目标、约束等信息;2) LLM奖励生成模块:利用LLM生成候选奖励函数;3) 奖励函数评估模块:使用深度强化学习算法评估候选奖励函数的性能;4) 奖励函数优化模块:根据评估结果,迭代优化LLM的奖励生成策略。整个流程形成一个闭环,不断提升奖励函数的效果。
关键创新:ChatPCG的关键创新在于将大语言模型应用于游戏AI的奖励设计,实现了奖励函数的自动生成。与传统的基于规则或人工设计的奖励函数相比,ChatPCG能够更好地理解游戏机制和内容生成目标,生成更有效的奖励函数,从而提升游戏AI的性能和内容生成的多样性。
关键设计:在LLM奖励生成模块中,使用了Prompt Engineering技术,设计了合适的Prompt,引导LLM生成符合要求的奖励函数。奖励函数评估模块使用了常见的深度强化学习算法,如PPO或DQN。奖励函数优化模块则通过强化学习的方式,训练LLM的奖励生成策略,使其能够生成更有效的奖励函数。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文展示了ChatPCG在多人游戏内容生成任务中的应用潜力,但具体的性能数据、对比基线和提升幅度在摘要中没有明确给出。摘要强调了ChatPCG能够理解游戏机制和内容生成任务,并为特定游戏定制内容生成,表明该方法具有一定的有效性。更详细的实验结果需要在论文正文中查找。
🎯 应用场景
ChatPCG可应用于各种游戏类型的内容生成,例如关卡设计、角色生成、剧情创作等。该研究能够降低游戏AI开发的门槛,提高内容生成效率和多样性,并为游戏开发者提供更强大的AI工具。未来,ChatPCG有望扩展到其他领域,如虚拟现实、教育等,实现更智能化的内容生成。
📄 摘要(原文)
Driven by the rapid growth of machine learning, recent advances in game artificial intelligence (AI) have significantly impacted productivity across various gaming genres. Reward design plays a pivotal role in training game AI models, wherein researchers implement concepts of specific reward functions. However, despite the presence of AI, the reward design process predominantly remains in the domain of human experts, as it is heavily reliant on their creativity and engineering skills. Therefore, this paper proposes ChatPCG, a large language model (LLM)-driven reward design framework.It leverages human-level insights, coupled with game expertise, to generate rewards tailored to specific game features automatically. Moreover, ChatPCG is integrated with deep reinforcement learning, demonstrating its potential for multiplayer game content generation tasks. The results suggest that the proposed LLM exhibits the capability to comprehend game mechanics and content generation tasks, enabling tailored content generation for a specified game. This study not only highlights the potential for improving accessibility in content generation but also aims to streamline the game AI development process.