The Good, the Bad, and the Hulk-like GPT: Analyzing Emotional Decisions of Large Language Models in Cooperation and Bargaining Games
作者: Mikhail Mozikov, Nikita Severin, Valeria Bodishtianu, Maria Glushanina, Mikhail Baklashkin, Andrey V. Savchenko, Ilya Makarov
分类: cs.AI, cs.CL
发布日期: 2024-06-05
💡 一句话要点
提出情感驱动的LLM行为建模框架,用于合作与博弈场景决策分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 行为博弈论 情感计算 人机交互 社会建模
📋 核心要点
- 现有LLM行为模拟研究忽略了情绪这一人类决策的关键因素,且缺乏对LLM行为与人类行为对齐程度的充分验证。
- 该论文提出一种新方法和框架,通过情感诱导,研究LLM在合作与博弈场景下的决策行为,并分析其与人类行为的对齐程度。
- 实验表明,情绪显著影响LLM的性能,尤其是在GPT-3.5上,而GPT-4在特定情感提示下也会表现出类似人类的情感反应。
📝 摘要(中文)
行为研究实验是社会建模和理解人类互动的重要组成部分。然而,由于社会互动和合作的复杂性,许多行为实验在内部和外部有效性、可重复性和社会偏见方面面临挑战。大型语言模型(LLM)的最新进展为研究人员提供了一个模拟人类行为的新工具。然而,现有的基于LLM的模拟是在未经证实的假设下运行的,即LLM代理的行为与人类相似,并且忽略了人类决策中的一个关键因素:情绪。本文介绍了一种新颖的方法和框架,用于研究LLM的决策以及它们在情绪状态下与人类行为的对齐情况。对GPT-3.5和GPT-4在来自行为博弈论两个不同类别的四个博弈上进行的实验表明,情绪深刻地影响了LLM的性能,从而导致更优策略的制定。虽然GPT-3.5的行为反应与人类参与者之间存在很强的对齐,尤其是在议价博弈中,但GPT-4表现出一致的行为,忽略了理性决策的诱导情绪。令人惊讶的是,情感提示,特别是“愤怒”情绪,可以打破GPT-4的“超人”对齐,使其类似于人类的情感反应。
🔬 方法详解
问题定义:现有基于LLM的行为模拟研究,通常假设LLM的行为与人类相似,但忽略了人类决策中至关重要的情绪因素。此外,缺乏对LLM在不同情绪状态下行为模式的系统性研究,以及与人类行为的对齐程度的量化分析。这限制了LLM在社会行为建模中的应用,并可能导致不准确的预测和结论。
核心思路:该论文的核心思路是通过情感诱导,使LLM进入特定的情绪状态,然后观察其在合作与博弈场景下的决策行为。通过对比不同情绪状态下LLM的行为,以及与人类参与者的行为进行对比,来分析情绪对LLM决策的影响,并评估LLM行为与人类行为的对齐程度。这种方法旨在更真实地模拟人类的社会行为,并提高LLM在社会建模中的有效性。
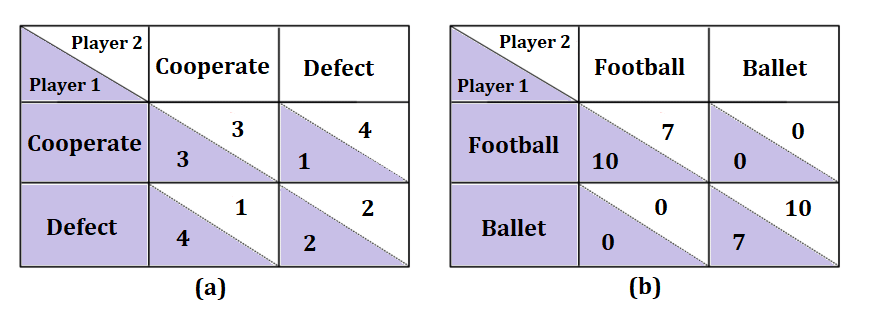
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择合适的合作与博弈游戏,例如最后通牒博弈和囚徒困境;2) 设计情感诱导提示,例如通过文本描述使LLM进入愤怒、悲伤或快乐等情绪状态;3) 使用GPT-3.5和GPT-4等LLM作为代理,在不同的情感状态下进行博弈;4) 收集LLM的决策数据,并与人类参与者的行为数据进行对比分析;5) 使用统计方法评估LLM行为与人类行为的对齐程度,并分析情绪对LLM决策的影响。
关键创新:该论文的关键创新在于:1) 提出了一种基于情感诱导的LLM行为建模方法,能够更真实地模拟人类的社会行为;2) 系统地研究了情绪对LLM决策的影响,并揭示了不同LLM在不同情绪状态下的行为模式;3) 量化分析了LLM行为与人类行为的对齐程度,为评估LLM在社会建模中的有效性提供了依据。
关键设计:在情感诱导方面,论文使用了精心设计的文本提示,例如“你感到非常愤怒,因为...”来引导LLM进入特定的情绪状态。在博弈设计方面,选择了经典的合作与博弈游戏,例如最后通牒博弈和囚徒困境,这些游戏能够有效地考察LLM的合作性和公平性。在数据分析方面,使用了统计方法,例如t检验和方差分析,来评估不同情绪状态下LLM行为的差异,并与人类行为进行对比。
🖼️ 关键图片


📊 实验亮点
实验结果表明,情绪对LLM的决策有显著影响,尤其是在GPT-3.5上,情感诱导能够改变其行为策略,使其更接近人类。令人惊讶的是,即使是表现出“超人”理性的GPT-4,在受到特定情感提示(如“愤怒”)的影响时,也会表现出类似人类的情感反应,打破其理性行为模式。这表明情感提示可以有效影响LLM的行为,使其更具人类特征。
🎯 应用场景
该研究成果可应用于社会行为建模、人机交互设计、以及AI伦理研究等领域。例如,可以利用该方法构建更逼真的人类行为模型,用于预测社会事件的发生和发展。此外,该研究可以帮助设计更具同理心和适应性的人机交互系统,提高用户体验。同时,该研究也有助于理解LLM的决策机制,为AI伦理研究提供参考。
📄 摘要(原文)
Behavior study experiments are an important part of society modeling and understanding human interactions. In practice, many behavioral experiments encounter challenges related to internal and external validity, reproducibility, and social bias due to the complexity of social interactions and cooperation in human user studies. Recent advances in Large Language Models (LLMs) have provided researchers with a new promising tool for the simulation of human behavior. However, existing LLM-based simulations operate under the unproven hypothesis that LLM agents behave similarly to humans as well as ignore a crucial factor in human decision-making: emotions. In this paper, we introduce a novel methodology and the framework to study both, the decision-making of LLMs and their alignment with human behavior under emotional states. Experiments with GPT-3.5 and GPT-4 on four games from two different classes of behavioral game theory showed that emotions profoundly impact the performance of LLMs, leading to the development of more optimal strategies. While there is a strong alignment between the behavioral responses of GPT-3.5 and human participants, particularly evident in bargaining games, GPT-4 exhibits consistent behavior, ignoring induced emotions for rationality decisions. Surprisingly, emotional prompting, particularly with `anger' emotion, can disrupt the "superhuman" alignment of GPT-4, resembling human emotional responses.