CATCODER: Repository-Level Code Generation with Relevant Code and Type Context
作者: Zhiyuan Pan, Xing Hu, Xin Xia, Xiaohu Yang
分类: cs.SE, cs.AI
发布日期: 2024-06-05 (更新: 2025-11-21)
备注: Revised and extended version; To be published in ACM Transactions on Software Engineering and Methodology
💡 一句话要点
CatCoder:通过融合相关代码和类型上下文,提升仓库级代码生成效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 仓库级代码 类型上下文 静态分析 大型语言模型
📋 核心要点
- 仓库级代码生成面临挑战,需要利用整个仓库的信息,现有检索方法难以获取全面上下文。
- CatCoder通过静态分析提取类型依赖,并将其与检索到的代码融合,为LLM提供更全面的提示。
- 实验表明,CatCoder在Java和Rust任务上优于RepoCoder,且在不同LLM上均有提升,具有实用性和可扩展性。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成任务中展现了卓越的能力。然而,仓库级代码生成提出了独特的挑战,特别是需要利用仓库内多个文件中传播的信息。成功的生成依赖于对通用、与上下文无关的知识和特定、与上下文相关的知识的扎实掌握。虽然LLMs被广泛用于处理上下文无关的方面,但现有的基于检索的方法有时会不足,因为它们在获取更广泛和更深入的仓库上下文方面受到限制。本文提出了CatCoder,一种为静态类型编程语言设计的新型代码生成框架。CatCoder通过集成相关代码和类型上下文来增强仓库级代码生成。具体来说,它利用静态分析器提取类型依赖关系,并将此信息与检索到的代码合并,从而为LLMs创建全面的提示。为了评估CatCoder的有效性,我们调整并构建了包含199个Java任务和90个Rust任务的基准。结果表明,在compile@k和pass@k指标方面,CatCoder优于RepoCoder基线高达14.44%和17.35%。此外,使用各种LLMs(包括代码专用模型和通用模型)评估了CatCoder的泛化能力。我们的研究结果表明,所有模型的性能都得到了持续的提高,这突出了CatCoder的实用性。此外,我们评估了CatCoder在大型开源仓库中的时间消耗,结果表明CatCoder具有良好的可扩展性。
🔬 方法详解
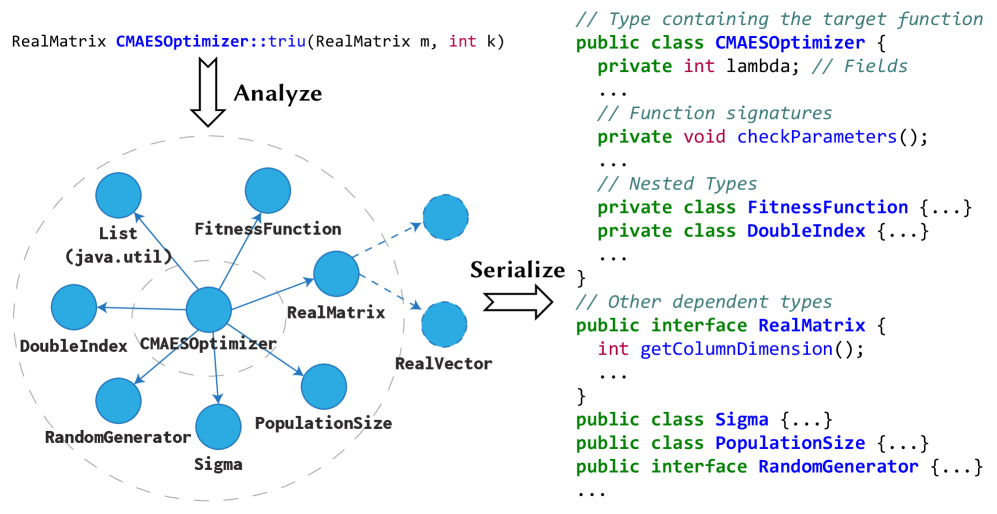
问题定义:仓库级代码生成需要利用整个代码仓库的上下文信息,而现有方法,特别是基于检索的方法,难以有效地获取和利用这些信息。它们通常无法捕捉到代码库中类型依赖等关键信息,导致生成的代码质量不高。
核心思路:CatCoder的核心思路是通过静态分析提取代码仓库中的类型依赖关系,并将这些类型信息与检索到的相关代码片段结合起来,形成一个更全面的上下文提示,提供给大型语言模型(LLMs)。这样可以帮助LLMs更好地理解代码的语义,从而生成更准确、更符合要求的代码。
技术框架:CatCoder框架主要包含以下几个阶段:1) 静态分析:使用静态分析器提取代码仓库中的类型依赖关系。2) 代码检索:检索与当前代码生成任务相关的代码片段。3) 上下文融合:将提取的类型依赖关系与检索到的代码片段融合,形成一个综合的上下文提示。4) 代码生成:将上下文提示输入到LLM中,生成代码。
关键创新:CatCoder的关键创新在于将静态分析提取的类型信息融入到代码生成过程中。与传统的仅依赖代码检索的方法相比,CatCoder能够提供更丰富的上下文信息,从而提高代码生成的准确性和可靠性。
关键设计:CatCoder的关键设计包括:1) 如何选择合适的静态分析器来提取类型依赖关系。2) 如何有效地融合类型信息和代码片段,形成一个清晰、易于理解的上下文提示。3) 如何选择合适的LLM,并针对仓库级代码生成任务进行优化。论文中没有明确提及具体的参数设置、损失函数或网络结构等技术细节,这部分信息未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CatCoder在Java和Rust代码生成任务上均取得了显著的性能提升。在Java任务上,CatCoder的compile@k和pass@k指标比RepoCoder基线提高了高达14.44%。在Rust任务上,提升幅度更是达到了17.35%。此外,CatCoder在不同的LLM上均表现出一致的性能提升,证明了其良好的泛化能力。
🎯 应用场景
CatCoder可应用于各种软件开发场景,例如自动化代码补全、代码修复、代码迁移等。通过提高代码生成的准确性和效率,可以显著提升开发者的生产力,降低软件开发成本。未来,CatCoder有望成为智能软件开发工具的重要组成部分。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, repository-level code generation presents unique challenges, particularly due to the need to utilize information spread across multiple files within a repository. Specifically, successful generation depends on a solid grasp of both general, context-agnostic knowledge and specific, context-dependent knowledge. While LLMs are widely used for the context-agnostic aspect, existing retrieval-based approaches sometimes fall short as they are limited in obtaining a broader and deeper repository context. In this paper, we present CatCoder, a novel code generation framework designed for statically typed programming languages. CatCoder enhances repository-level code generation by integrating relevant code and type context. Specifically, it leverages static analyzers to extract type dependencies and merges this information with retrieved code to create comprehensive prompts for LLMs. To evaluate the effectiveness of CatCoder, we adapt and construct benchmarks that include 199 Java tasks and 90 Rust tasks. The results show that CatCoder outperforms the RepoCoder baseline by up to 14.44% and 17.35%, in terms of compile@k and pass@k scores. In addition, the generalizability of CatCoder is assessed using various LLMs, including both code-specialized models and general-purpose models. Our findings indicate consistent performance improvements across all models, which underlines the practicality of CatCoder. Furthermore, we evaluate the time consumption of CatCoder in a large open source repository, and the results demonstrate the scalability of CatCoder.