Large Language Models for Relevance Judgment in Product Search
作者: Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
分类: cs.IR, cs.AI
发布日期: 2024-06-01 (更新: 2024-07-16)
备注: 10 pages, 1 figure, 11 tables - SIGIR 2024, LLM4Eval
💡 一句话要点
利用大型语言模型自动化产品搜索中的相关性判断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 相关性判断 产品搜索 信息检索 微调 低秩适应 提示工程 自动化
📋 核心要点
- 产品搜索中,人工标注查询-商品对的相关性成本高昂且效率低下,限制了搜索质量的提升。
- 本文探索了利用大型语言模型(LLM)自动判断查询-商品对相关性的方法,旨在降低人工成本并提高效率。
- 实验表明,经过微调的LLM在相关性判断任务上显著优于传统模型,接近人工评估员的水平。
📝 摘要(中文)
产品搜索成功的基石在于检索和重排序的商品与搜索查询的高度相关性。然而,衡量商品与查询的相关性是产品信息检索中最具挑战性的任务之一,产品搜索的质量很大程度上受到可用相关性标注数据的精确性和规模的影响。本文提出了一系列技术,利用大型语言模型(LLM)大规模自动化查询-商品对(QIP)的相关性判断。我们使用一个独特的多百万QIP数据集(由人工评估员标注),测试并优化了具有和不具有低秩适应(LoRA)的数十亿参数LLM的超参数,以及LLM微调中各种商品属性连接和提示模式,并考虑了商品属性包含在相关性预测质量方面的权衡。我们证明了相对于前几代LLM以及现成模型的基线,在与人工相关性评估员相当的相关性标注方面,有显著的改进。我们的发现对产品搜索中日益增长的相关性判断自动化领域具有直接意义。
🔬 方法详解
问题定义:论文旨在解决产品搜索中大规模查询-商品对(QIP)相关性判断的问题。现有方法依赖于人工标注,成本高昂且难以扩展。此外,传统模型在理解查询和商品之间的复杂关系方面存在局限性。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语义理解和生成能力,通过微调LLM使其能够自动判断QIP的相关性。通过学习人工标注的数据,LLM可以模拟人工评估员的判断过程,从而实现自动化相关性判断。
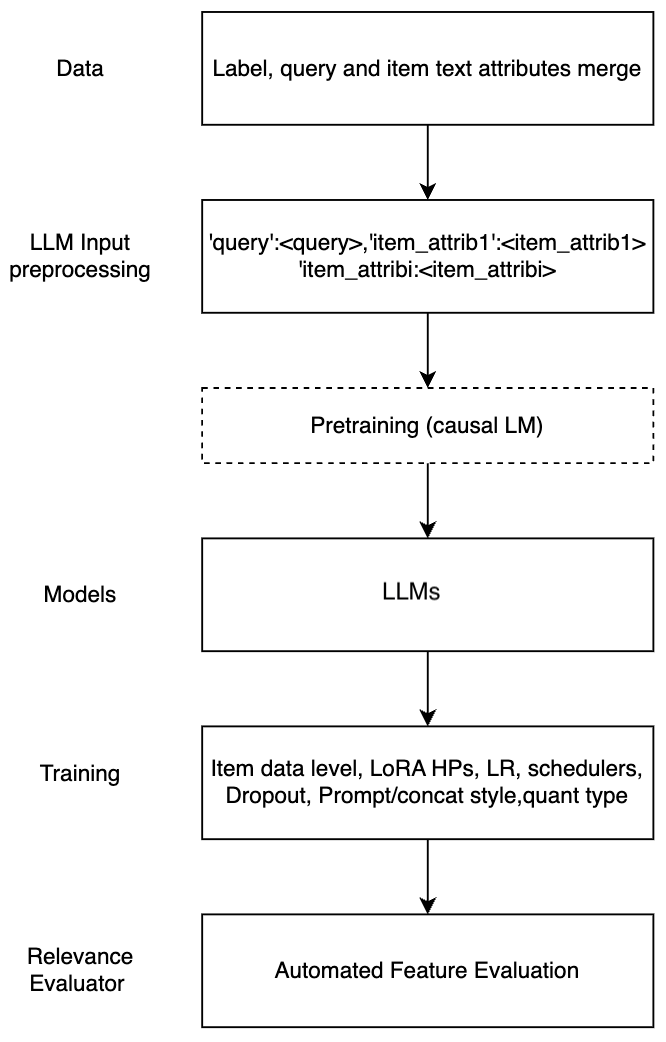
技术框架:整体框架包括数据准备、模型选择与微调、以及评估三个主要阶段。首先,收集并清洗包含查询、商品信息和人工标注相关性的QIP数据集。然后,选择预训练的LLM作为基础模型,并根据QIP数据的特点设计合适的输入格式(例如,将查询和商品属性连接成文本)。接着,使用人工标注的数据对LLM进行微调,优化模型参数。最后,使用评估指标(例如,准确率、召回率)评估微调后的LLM在相关性判断任务上的性能。
关键创新:论文的关键创新在于探索了多种利用LLM进行相关性判断的方法,包括不同的微调策略(例如,使用LoRA进行参数高效微调)、不同的商品属性连接方式、以及不同的提示工程方法。通过对比实验,论文找到了最佳的LLM微调方案,实现了显著的性能提升。
关键设计:论文的关键设计包括:1) 探索了不同的商品属性连接方式,例如将商品标题、描述、类别等信息拼接成文本输入LLM;2) 尝试了不同的提示工程方法,例如在输入文本中加入引导性语句,帮助LLM更好地理解任务;3) 使用了低秩适应(LoRA)技术,在微调LLM的同时减少了计算资源消耗;4) 优化了LLM的超参数,例如学习率、batch size等,以获得最佳的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过微调的LLM在相关性判断任务上显著优于传统模型和未经微调的LLM。具体而言,最佳的LLM微调方案在准确率、召回率等指标上都取得了显著提升,并且在一定程度上达到了人工评估员的水平。这表明LLM在自动化相关性判断方面具有巨大的潜力。
🎯 应用场景
该研究成果可广泛应用于电商平台的搜索排序、推荐系统、广告投放等领域。通过自动化相关性判断,可以降低人工成本,提高搜索结果的质量和用户满意度。此外,该方法还可以应用于其他信息检索领域,例如新闻搜索、学术搜索等,具有重要的实际应用价值。
📄 摘要(原文)
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.