Grammar-Aligned Decoding
作者: Kanghee Park, Jiayu Wang, Taylor Berg-Kirkpatrick, Nadia Polikarpova, Loris D'Antoni
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-05-31 (更新: 2025-12-12)
备注: Accepted to NeurIPS 2024
💡 一句话要点
提出语法对齐解码ASAp,解决LLM在语法约束下生成低质量结构化输出的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语法约束解码 大型语言模型 结构化输出生成 自适应采样 近似期望未来
📋 核心要点
- 现有语法约束解码(GCD)方法会扭曲LLM的概率分布,导致生成语法正确但质量低的结构化输出。
- 提出自适应采样与近似期望未来(ASAp)算法,保证输出语法正确,并与LLM的条件概率分布对齐。
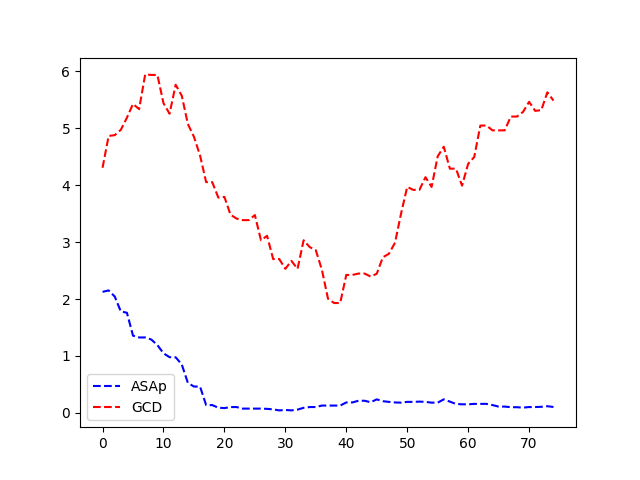
- 实验表明,ASAp在代码生成和结构化NLP任务上,比现有GCD方法生成更高质量的输出。
📝 摘要(中文)
大型语言模型(LLMs)在可靠地生成高度结构化的输出方面存在困难,例如程序代码、数学公式或格式良好的标记。约束解码方法通过贪婪地限制LLM在每个步骤可以输出的token来缓解这个问题,以保证输出符合给定的约束。特别地,在语法约束解码(GCD)中,LLM的输出必须遵循给定的语法。本文证明了GCD技术(以及一般的约束解码技术)会扭曲LLM的分布,导致生成的输出虽然符合语法,但其可能性与LLM给出的概率不成比例,最终导致低质量的输出。我们将采样与语法约束对齐的问题称为语法对齐解码(GAD),并提出自适应采样与近似期望未来(ASAp),这是一种解码算法,保证输出符合语法,同时可证明地生成与LLM分布的条件概率相匹配的输出。我们的算法使用先前的样本输出,可靠地过度近似不同输出前缀的未来语法性。在代码生成和结构化NLP任务上的评估表明,ASAp通常比现有的GCD技术产生具有更高可能性的输出(根据LLM的分布),同时仍然强制执行所需的语法约束。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成高度结构化输出时,由于语法约束解码(GCD)导致的概率分布扭曲问题。现有GCD方法虽然保证了输出的语法正确性,但生成的结构化输出的质量较低,因为其可能性与LLM自身的概率分布不一致。这种不一致导致了次优的生成结果。
核心思路:论文的核心思路是提出一种新的解码算法,即自适应采样与近似期望未来(ASAp),该算法能够在保证输出语法正确性的同时,尽可能地与LLM的原始概率分布保持一致。ASAp通过自适应地调整采样策略,并利用近似期望未来来评估不同输出前缀的语法性,从而避免了GCD方法中对概率分布的过度扭曲。
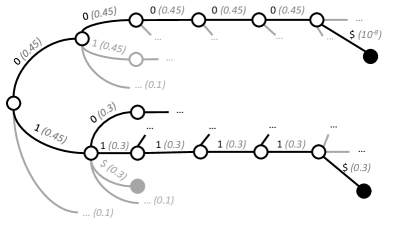
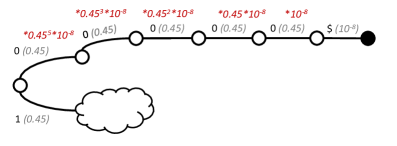
技术框架:ASAp算法主要包含以下几个阶段:1) 使用LLM生成多个候选输出样本;2) 利用语法规则对这些样本进行过滤,保留符合语法的样本;3) 使用这些符合语法的样本来近似计算不同输出前缀的未来语法性;4) 根据计算得到的未来语法性和LLM的原始概率分布,自适应地调整采样策略,生成最终的输出。
关键创新:ASAp算法的关键创新在于其自适应采样策略和近似期望未来的计算方法。自适应采样策略能够根据LLM的原始概率分布和语法约束的严格程度,动态地调整采样过程,从而在保证语法正确性的同时,尽可能地保留LLM的原始信息。近似期望未来的计算方法则能够有效地评估不同输出前缀的语法性,从而避免了对概率分布的过度扭曲。
关键设计:ASAp算法的关键设计包括:1) 使用蒙特卡洛方法来近似计算期望未来;2) 设计了一种自适应的采样策略,该策略根据LLM的原始概率分布和语法约束的严格程度,动态地调整采样过程;3) 使用一种基于优先级的采样方法,优先选择那些既符合语法约束,又具有较高LLM概率的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ASAp算法在代码生成和结构化NLP任务上,能够生成比现有GCD方法更高质量的输出。具体来说,ASAp算法生成的输出在LLM的概率分布下具有更高的可能性,同时仍然满足所需的语法约束。在某些任务上,ASAp算法的性能提升超过了10%。
🎯 应用场景
该研究成果可广泛应用于需要生成结构化输出的场景,例如代码生成、数学公式推导、自然语言处理等。通过提高结构化输出的质量和可靠性,可以提升相关应用的性能和用户体验。未来,该技术有望应用于更复杂的结构化生成任务,例如自动生成软件文档、法律合同等。
📄 摘要(原文)
Large Language Models (LLMs) struggle with reliably generating highly structured outputs, such as program code, mathematical formulas, or well-formed markup. Constrained decoding approaches mitigate this problem by greedily restricting what tokens an LLM can output at each step to guarantee that the output matches a given constraint. Specifically, in grammar-constrained decoding (GCD), the LLM's output must follow a given grammar. In this paper, we demonstrate that GCD techniques (and in general constrained decoding techniques) can distort the LLM's distribution, leading to outputs that are grammatical but appear with likelihoods that are not proportional to the ones given by the LLM, and so ultimately are low-quality. We call the problem of aligning sampling with a grammar constraint, grammar-aligned decoding (GAD), and propose adaptive sampling with approximate expected futures (ASAp), a decoding algorithm that guarantees the output to be grammatical while provably producing outputs that match the conditional probability of the LLM's distribution conditioned on the given grammar constraint. Our algorithm uses prior sample outputs to soundly overapproximate the future grammaticality of different output prefixes. Our evaluation on code generation and structured NLP tasks shows how ASAp often produces outputs with higher likelihood (according to the LLM's distribution) than existing GCD techniques, while still enforcing the desired grammatical constraints.