Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
作者: Xinlu Zhang, Zhiyu Zoey Chen, Xi Ye, Xianjun Yang, Lichang Chen, William Yang Wang, Linda Ruth Petzold
分类: cs.AI, cs.CL
发布日期: 2024-05-30 (更新: 2024-12-12)
💡 一句话要点
研究编码数据指令微调对大语言模型推理能力的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 大语言模型 推理能力 编码数据 零样本学习
📋 核心要点
- 现有研究对编码数据在指令微调阶段如何影响大语言模型的推理能力缺乏深入理解。
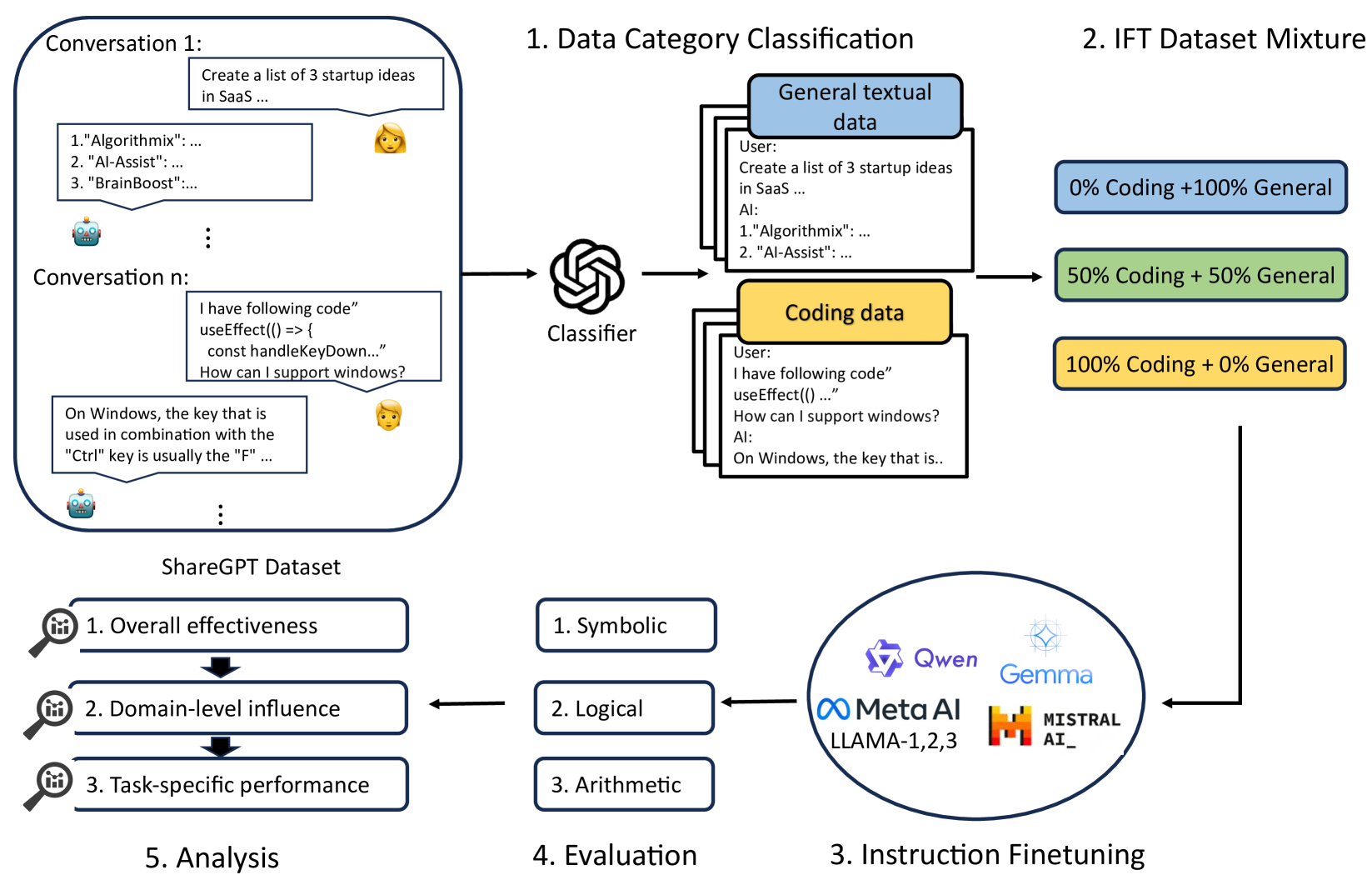
- 该研究通过构建不同编码数据比例的指令微调数据集,探索编码数据对模型推理能力的影响。
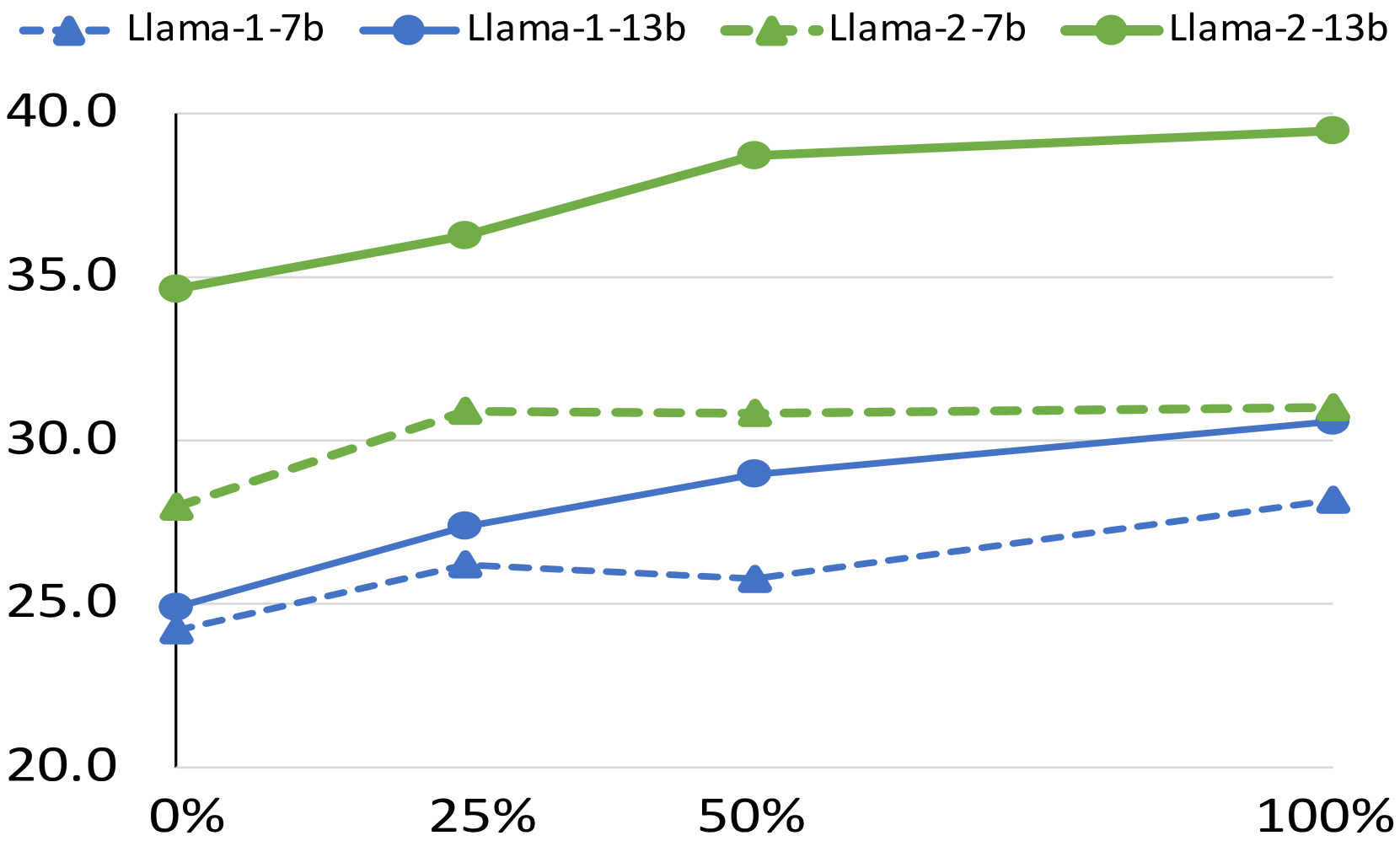
- 实验结果表明,编码数据微调能提升LLM的整体推理能力,且最佳比例因任务而异。
📝 摘要(中文)
指令微调(IFT)显著增强了预训练大语言模型(LLM)的零样本能力。虽然编码数据在预训练阶段已知可以提升LLM的推理能力,但其在IFT阶段激活内部推理能力的作用仍未得到充分研究。本文探讨了一个关键问题:编码数据如何在IFT阶段影响LLM的推理能力?为了探索这一点,我们从不同角度全面考察了编码数据在不同编码数据比例、模型家族、规模和推理领域的影响。具体来说,我们创建了三个具有递增编码数据比例的IFT数据集,在这些数据集上对六个不同家族和规模的LLM骨干模型进行微调,评估了微调后的模型在三个推理领域的十二个任务中的性能,并从整体、领域和任务三个由粗到细的视角分析了结果。我们的整体分析为每个视角提供了有价值的见解。首先,编码数据微调增强了不同模型家族和规模的LLM的整体推理能力。此外,虽然编码数据的影响因领域而异,但它在不同模型家族和规模的每个领域内都显示出一致的趋势。此外,编码数据通常在不同模型家族中提供相当的任务特定优势,IFT数据集中最佳比例取决于任务。
🔬 方法详解
问题定义:该论文旨在研究编码数据在指令微调(IFT)阶段对大型语言模型(LLM)推理能力的影响。现有研究主要关注编码数据在预训练阶段的作用,而忽略了其在IFT阶段激活和增强LLM内部推理能力的潜力。因此,该研究试图填补这一空白,深入理解编码数据在IFT中的作用,并为如何有效利用编码数据提升LLM推理能力提供指导。
核心思路:核心思路是通过控制IFT数据集中编码数据的比例,观察不同比例的编码数据对LLM在不同推理任务上的表现的影响。通过系统地改变编码数据比例,并结合不同模型家族和规模的LLM进行实验,从而揭示编码数据与LLM推理能力之间的关系。这种方法能够量化编码数据的影响,并识别出最佳的编码数据比例。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建具有不同编码数据比例的IFT数据集;2) 选择不同家族和规模的LLM作为骨干模型;3) 在构建的IFT数据集上对LLM进行微调;4) 在多个推理任务上评估微调后的LLM的性能;5) 从整体、领域和任务三个层面分析实验结果。
关键创新:该研究的关键创新在于系统性地研究了编码数据在IFT阶段对LLM推理能力的影响。通过构建不同编码数据比例的IFT数据集,并结合多种LLM和推理任务进行实验,从而全面地揭示了编码数据与LLM推理能力之间的复杂关系。此外,该研究还提出了从整体、领域和任务三个层面分析实验结果的方法,从而能够更深入地理解编码数据的影响。
关键设计:关键设计包括:1) 构建三个具有递增编码数据比例的IFT数据集,以系统地研究编码数据的影响;2) 选择六个不同家族和规模的LLM作为骨干模型,以验证研究结果的泛化性;3) 在三个推理领域的十二个任务中评估微调后的模型性能,以全面地评估模型的推理能力;4) 从整体、领域和任务三个层面分析实验结果,以深入理解编码数据的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,编码数据微调能够提升不同模型家族和规模的LLM的整体推理能力。虽然编码数据的影响因领域而异,但在同一领域内,不同模型家族和规模的模型表现出一致的趋势。此外,编码数据通常在不同模型家族中提供相当的任务特定优势,且IFT数据集中最佳的编码数据比例取决于具体的任务。
🎯 应用场景
该研究成果可应用于提升大语言模型在各种需要推理能力的场景中的性能,例如代码生成、数学问题求解、逻辑推理等。通过合理配置指令微调数据集中的编码数据比例,可以有效提升模型的推理能力,从而提高模型在实际应用中的表现。此外,该研究还可以为构建更有效的指令微调数据集提供指导。
📄 摘要(原文)
Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost LLM reasoning abilities during pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights into each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, while the impact of coding data varies by domain, it shows consistent trends within each domain across different model families and scales. Additionally, coding data generally provides comparable task-specific benefits across model families, with optimal proportions in IFT datasets being task-dependent.