Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
作者: Hyo Jin Do, Rachel Ostrand, Justin D. Weisz, Casey Dugan, Prasanna Sattigeri, Dennis Wei, Keerthiram Murugesan, Werner Geyer
分类: cs.HC, cs.AI
发布日期: 2024-05-30
备注: Submitted to the Trust and Reliance in Evolving Human-AI Workflows (TREW) Workshop at CHI 2024
💡 一句话要点
通过事实性评分和来源归属促进人与大型语言模型的协作
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 大型语言模型 事实性验证 来源归属 用户界面设计
📋 核心要点
- 大型语言模型容易产生幻觉,现有方法缺乏有效沟通机制,难以校准用户信任。
- 论文核心在于设计有效的事实性评分和来源归属的可视化策略,提升用户对LLM输出的信任。
- 实验表明,颜色编码的事实性评分和突出显示的来源信息能显著提升用户信任度与验证效率。
📝 摘要(中文)
人类越来越依赖大型语言模型(LLM),但LLM容易生成不准确或虚假的信息,即“幻觉”。在检测幻觉内容方面,通过评估模型响应的事实性并将响应的各个部分归因于特定的源文档,技术上已经取得了进展。然而,关于如何有效地将这些信息传达给用户,以帮助他们适当地校准对LLM的信任,研究还很有限。为了解决这个问题,我们进行了一项基于场景的研究(N=104),系统地比较了用于传达事实性和来源归属的各种设计策略对参与者信任度、偏好以及验证响应准确性难易程度的影响。我们的研究结果表明,参与者更喜欢一种设计,其中响应中的短语根据计算的事实性得分进行颜色编码。此外,与在源材料中没有收到任何注释相比,当源材料的相关部分被突出显示或响应被注释有对应于这些来源的参考编号时,参与者提高了他们的信任度。我们的研究为促进人与LLM的协作提供了实用的设计指南,并提倡一种新的人类角色,即仔细评估并对他们使用LLM输出负责。
🔬 方法详解
问题定义:大型语言模型(LLM)在生成文本时存在“幻觉”问题,即生成不准确或虚假的信息。现有方法在检测幻觉内容方面取得了一定进展,但缺乏有效的方式将这些信息传达给用户,导致用户难以判断LLM输出的可信度,从而影响人与LLM的协作效率。现有方法的痛点在于,无法帮助用户适当地校准对LLM的信任,也无法有效帮助用户验证LLM输出的准确性。
核心思路:论文的核心思路是通过设计不同的可视化策略,将LLM输出的事实性评分和来源归属信息有效地传达给用户。通过颜色编码、高亮显示和参考编号等方式,帮助用户快速识别LLM输出中可能存在错误的部分,并追溯到原始来源进行验证,从而提高用户对LLM输出的信任度和验证效率。这种设计旨在促进人与LLM的协作,使用户能够更好地利用LLM的优势,同时避免受到其幻觉的影响。
技术框架:该研究采用实验方法,通过构建不同的用户界面设计,来评估不同设计策略对用户信任度、偏好和验证效率的影响。具体流程如下: 1. LLM响应生成:使用LLM生成文本响应。 2. 事实性评分和来源归属:使用算法对LLM响应进行事实性评分,并将响应的各个部分归因于特定的源文档。 3. 用户界面设计:设计不同的用户界面,用于展示LLM响应、事实性评分和来源归属信息,包括颜色编码、高亮显示和参考编号等。 4. 用户实验:招募参与者,使用不同的用户界面完成特定任务,并收集参与者的信任度、偏好和验证效率等数据。 5. 数据分析:分析实验数据,评估不同用户界面设计的效果,并得出结论。
关键创新:论文的关键创新在于,它系统地研究了如何通过用户界面设计来有效地传达LLM输出的事实性评分和来源归属信息。与现有方法相比,该研究更加关注用户体验,旨在设计出能够帮助用户更好地理解和利用LLM输出的界面。通过实验验证了不同设计策略的效果,为未来人与LLM协作界面的设计提供了实用的指导。
关键设计:研究中涉及的关键设计包括: * 颜色编码:使用不同的颜色来表示LLM响应中不同部分的事实性评分,例如,绿色表示高可信度,红色表示低可信度。 * 高亮显示:在原始来源中高亮显示与LLM响应相关的部分,帮助用户快速找到验证信息。 * 参考编号:在LLM响应中添加参考编号,对应于原始来源中的特定段落,方便用户追溯来源。 * 用户界面布局:设计不同的用户界面布局,例如,将LLM响应和原始来源并排显示,或者将事实性评分信息以悬浮窗的形式展示。
🖼️ 关键图片


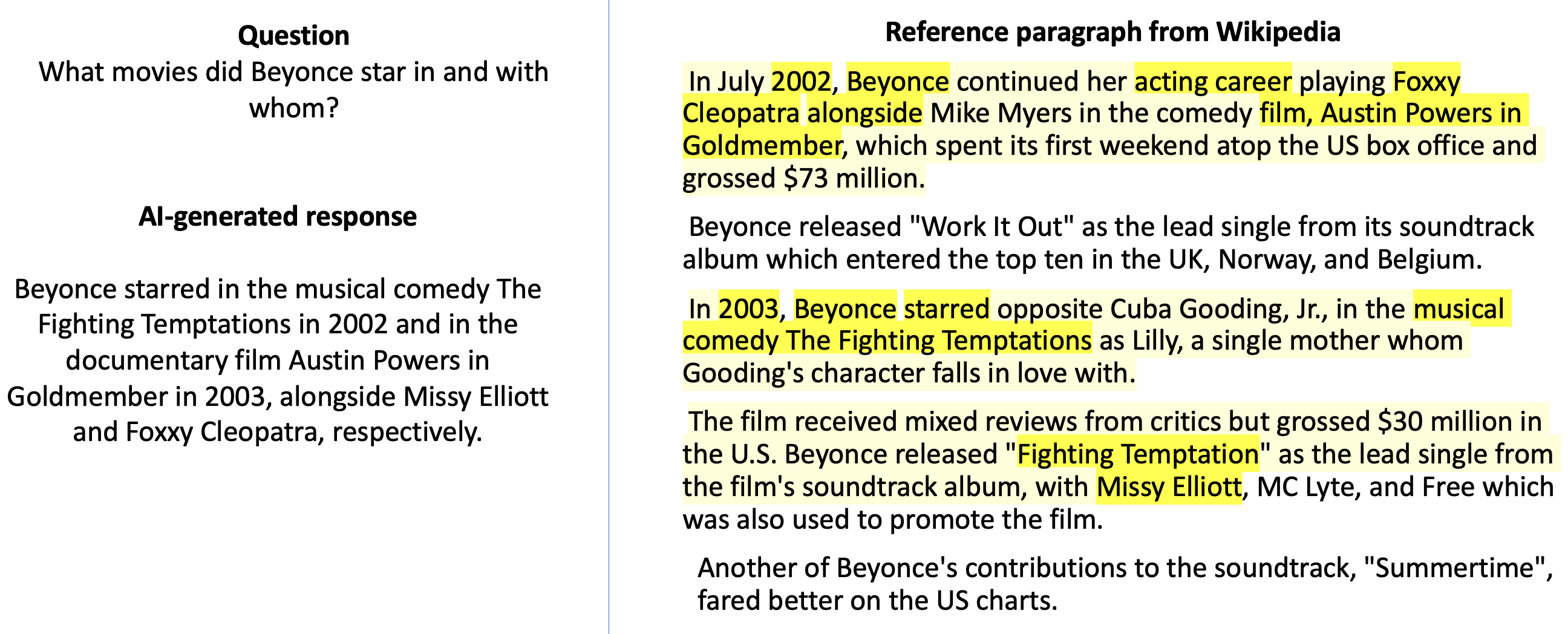
📊 实验亮点
实验结果表明,颜色编码的事实性评分显著提高了用户对LLM输出的信任度。与没有注释的源材料相比,突出显示源材料的相关部分或使用参考编号注释响应可以显著提高用户的信任度。具体来说,参与者更喜欢使用颜色编码来表示事实性评分的设计,并且在使用高亮显示或参考编号的界面中,信任度评分显著高于没有注释的界面。
🎯 应用场景
该研究成果可应用于各种需要人与LLM协作的场景,例如:智能客服、内容创作、信息检索等。通过提升用户对LLM输出的信任度和验证效率,可以更好地利用LLM的优势,提高工作效率和决策质量。未来,该研究可以进一步扩展到其他类型的AI系统,例如图像识别和语音识别,从而促进更广泛的人机协作。
📄 摘要(原文)
While humans increasingly rely on large language models (LLMs), they are susceptible to generating inaccurate or false information, also known as "hallucinations". Technical advancements have been made in algorithms that detect hallucinated content by assessing the factuality of the model's responses and attributing sections of those responses to specific source documents. However, there is limited research on how to effectively communicate this information to users in ways that will help them appropriately calibrate their trust toward LLMs. To address this issue, we conducted a scenario-based study (N=104) to systematically compare the impact of various design strategies for communicating factuality and source attribution on participants' ratings of trust, preferences, and ease in validating response accuracy. Our findings reveal that participants preferred a design in which phrases within a response were color-coded based on the computed factuality scores. Additionally, participants increased their trust ratings when relevant sections of the source material were highlighted or responses were annotated with reference numbers corresponding to those sources, compared to when they received no annotation in the source material. Our study offers practical design guidelines to facilitate human-LLM collaboration and it promotes a new human role to carefully evaluate and take responsibility for their use of LLM outputs.