Federated Cross-Training Learners for Robust Generalization under Data Heterogeneity
作者: Zhuang Qi, Lei Meng, Ruohan Zhang, Yu Wang, Xin Qi, Xiangxu Meng, Han Yu, Qiang Yang
分类: cs.AI
发布日期: 2024-05-30 (更新: 2025-09-16)
💡 一句话要点
提出FedCT,通过多视角知识蒸馏解决联邦学习中的数据异构问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 数据异构 知识蒸馏 交叉训练 表示学习
📋 核心要点
- 联邦学习中,数据异构性导致局部模型优化目标不一致,交叉训练后仍存在特征空间异构问题。
- FedCT通过多视角知识蒸馏,从个性化视角保留客户端特征,从全局视角提供一致性语义锚点,实现特征对齐。
- 实验表明,FedCT能有效减轻局部和全局知识遗忘,在多个数据集上超越现有联邦学习方法。
📝 摘要(中文)
联邦学习受益于交叉训练策略,该策略使模型能够在来自不同来源的数据上进行训练,从而提高泛化能力。然而,由于数据分布的固有差异,局部模型的优化目标仍然不一致,并且这种不匹配在交叉训练后仍然表现为特征空间异构性。本文认为,来自个性化视角的知识蒸馏保留了客户端特定的特征并扩展了本地知识库,而来自全局视角的蒸馏提供了促进客户端之间特征对齐的一致语义锚点。为了实现这一目标,本文提出了一种名为FedCT的交叉训练方案,包括三个主要模块,其中一致性感知知识广播模块旨在优化模型分配策略,从而增强客户端之间的协作优势并实现高效的联邦学习过程。多视角知识引导的表示学习模块利用来自全局和局部视角的融合原型知识来增强模型交换前后本地知识的保留,并确保本地知识和全局知识之间的一致性。基于Mixup的特征增强模块聚合了丰富的信息,以进一步增加特征空间的多样性,从而使模型能够更好地辨别复杂样本。在四个数据集上进行了广泛的实验,包括性能比较、消融研究、深入分析和案例研究。结果表明,FedCT减轻了来自本地和全局视角的知识遗忘,使其优于最先进的方法。
🔬 方法详解
问题定义:联邦学习旨在利用分布式数据训练全局模型,但实际应用中,各客户端数据分布往往存在显著差异(数据异构性)。这种异构性导致局部模型训练目标不一致,即使采用交叉训练,特征空间仍然存在不对齐问题,影响全局模型的泛化性能。现有方法难以有效平衡局部知识的保留和全局知识的对齐。
核心思路:FedCT的核心思路是利用多视角知识蒸馏来解决数据异构性带来的特征不对齐问题。具体来说,从个性化视角进行知识蒸馏,保留客户端的特定特征,避免过度泛化;同时,从全局视角进行知识蒸馏,提供一致的语义锚点,促进客户端之间的特征对齐。通过融合局部和全局知识,增强模型的鲁棒性和泛化能力。
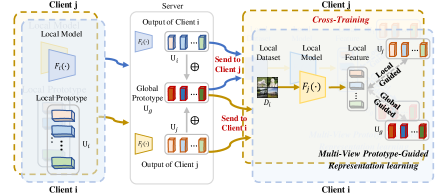
技术框架:FedCT包含三个主要模块:1) 一致性感知知识广播模块:优化模型分配策略,增强客户端之间的协作优势。2) 多视角知识引导的表示学习模块:利用融合的全局和局部原型知识,增强模型交换前后本地知识的保留,并确保本地知识和全局知识之间的一致性。3) 基于Mixup的特征增强模块:聚合丰富的信息,增加特征空间的多样性,使模型更好地辨别复杂样本。整体流程是,首先通过知识广播选择合适的客户端进行交叉训练,然后利用多视角知识蒸馏进行表示学习,最后通过特征增强提高模型的判别能力。
关键创新:FedCT的关键创新在于多视角知识蒸馏策略。不同于以往只关注全局或局部知识的蒸馏方法,FedCT同时考虑了两者,并设计了相应的模块来实现知识的融合和传递。这种多视角的方法能够更好地平衡局部知识的保留和全局知识的对齐,从而提高模型的泛化性能。
关键设计:在一致性感知知识广播模块中,可能使用了某种相似度度量来评估客户端之间的知识相关性,并基于此进行模型分配。在多视角知识引导的表示学习模块中,可能使用了原型网络来提取全局和局部知识的代表性特征,并设计了相应的损失函数来促使局部模型与全局原型对齐。基于Mixup的特征增强模块可能采用了不同的Mixup策略,例如在特征空间或标签空间进行混合,以生成新的训练样本。
🖼️ 关键图片


📊 实验亮点
论文在四个数据集上进行了实验,结果表明FedCT优于现有的联邦学习方法。具体的性能提升数据未知,但摘要中明确指出FedCT减轻了来自本地和全局视角的知识遗忘,使其能够超越当前最先进的方法。消融实验和案例研究进一步验证了FedCT各个模块的有效性。
🎯 应用场景
FedCT可应用于各种数据异构的联邦学习场景,例如医疗健康、金融风控、智能交通等。在这些领域,数据通常分布在不同的机构或设备上,且数据分布存在显著差异。FedCT能够有效解决数据异构性带来的挑战,提高联邦学习模型的性能和鲁棒性,从而促进这些领域的智能化应用。
📄 摘要(原文)
Federated learning benefits from cross-training strategies, which enables models to train on data from distinct sources to improve generalization capability. However, due to inherent differences in data distributions, the optimization goals of local models remain misaligned, and this mismatch continues to manifest as feature space heterogeneity even after cross-training. We argue that knowledge distillation from the personalized view preserves client-specific characteristics and expands the local knowledge base, while distillation from the global view provides consistent semantic anchors that facilitate feature alignment across clients. To achieve this goal, this paper presents a cross-training scheme, termed FedCT, includes three main modules, where the consistency-aware knowledge broadcasting module aims to optimize model assignment strategies, which enhances collaborative advantages between clients and achieves an efficient federated learning process. The multi-view knowledge-guided representation learning module leverages fused prototypical knowledge from both global and local views to enhance the preservation of local knowledge before and after model exchange, as well as to ensure consistency between local and global knowledge. The mixup-based feature augmentation module aggregates rich information to further increase the diversity of feature spaces, which enables the model to better discriminate complex samples. Extensive experiments were conducted on four datasets in terms of performance comparison, ablation study, in-depth analysis and case study. The results demonstrated that FedCT alleviates knowledge forgetting from both local and global views, which enables it outperform state-of-the-art methods.