Leveraging Open-Source Large Language Models for encoding Social Determinants of Health using an Intelligent Router
作者: Akul Goel, Surya Narayanan Hari, Belinda Waltman, Matt Thomson
分类: cs.AI
发布日期: 2024-05-30 (更新: 2026-01-15)
💡 一句话要点
提出基于智能路由的开源大语言模型系统,用于高效编码健康社会决定因素(SDOH)。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 健康社会决定因素 大型语言模型 智能路由 开源模型 医疗编码
📋 核心要点
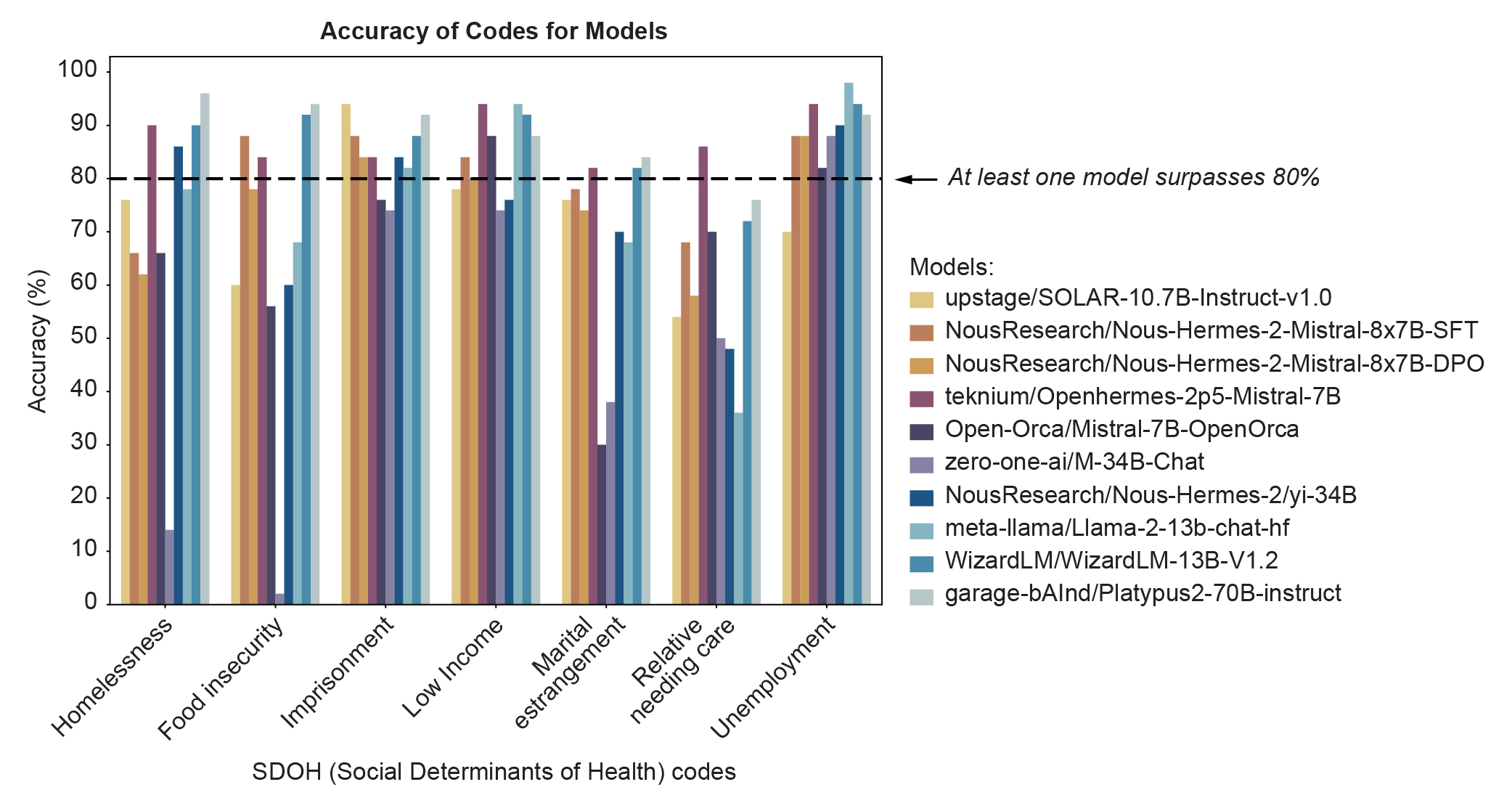
- Z代码在电子健康记录中编码不足,需要从临床笔记中推断,但现有方法难以选择最佳模型。
- 提出一种智能路由系统,将医疗记录数据路由到针对特定SDOH代码表现最佳的开源LLM。
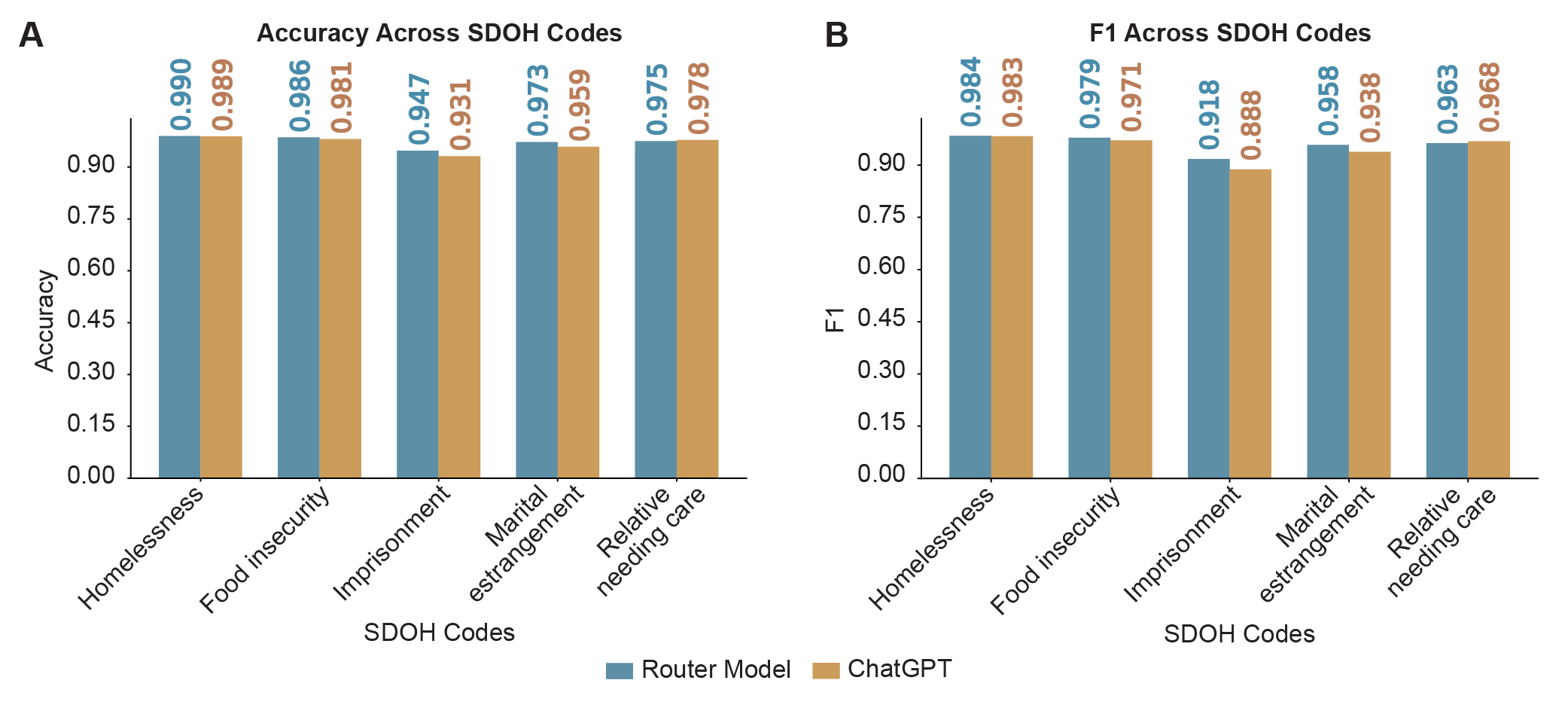
- 实验结果表明,该系统在13个代码上的平均准确率达到96.4%,优于闭源模型GPT-4o。
📝 摘要(中文)
健康社会决定因素(SDOH),也称为健康相关社会需求(HSRN),在患者健康结果中起着重要作用。美国疾病控制与预防中心(CDC)引入了ICD-10代码的一个子集,称为Z代码,以识别和衡量SDOH。然而,Z代码在患者的电子健康记录(EHR)中很少被编码,而通常需要从临床笔记中推断。以往的研究表明,大型语言模型(LLM)在从EHR中提取非结构化数据方面显示出前景,但很难找到一个在各种编码任务中表现最佳的单一模型。此外,临床笔记包含受保护的健康信息,这对使用商业供应商的闭源语言模型提出了挑战。识别可以在健康组织内部运行并在SDOH任务上表现出高性能的开源LLM是一个需要解决的重要问题。本文介绍了一种用于SDOH编码的智能路由系统,该系统使用语言模型路由器将医疗记录数据定向到在特定SDOH代码上表现出最佳性能的开源LLM。该智能路由系统在13个代码(包括无家可归和食物不足)上的平均准确率达到96.4%,表现出最先进的性能,优于GPT-4o等闭源模型。我们利用公开的、去识别化的医疗记录笔记数据集来运行路由器,但我们也引入了一种合成数据生成和验证范式,以增加训练数据的规模,而无需受隐私保护的医疗记录。总之,我们展示了一种智能路由架构,可以将输入路由到任务最优的语言模型,从而在一组医疗编码子任务中实现高性能。
🔬 方法详解
问题定义:论文旨在解决健康社会决定因素(SDOH)编码问题,具体来说,就是如何有效地从电子健康记录(EHR)的临床笔记中提取并编码SDOH信息。现有方法主要面临两个痛点:一是Z代码在EHR中编码不足,需要从非结构化文本中推断;二是难以找到一个在所有SDOH编码任务上都表现最佳的单一语言模型,且闭源模型存在隐私风险。
核心思路:论文的核心思路是利用一个智能路由系统,将不同的医疗记录数据路由到最适合处理该数据的开源大型语言模型(LLM)。这种方法避免了使用单一模型处理所有任务的局限性,而是根据任务的特性选择最优模型,从而提高整体编码的准确性和效率。同时,使用开源模型也规避了隐私问题。
技术框架:该智能路由系统包含以下主要模块:1) 数据输入模块:接收医疗记录数据,例如临床笔记。2) 语言模型路由器:根据输入数据的特征,决定将数据路由到哪个开源LLM。3) 开源LLM池:包含多个开源LLM,每个模型针对特定的SDOH代码进行了优化。4) 编码输出模块:将LLM的编码结果输出。整体流程是:输入数据首先经过路由器,路由器选择合适的LLM,LLM对数据进行编码,最后输出编码结果。
关键创新:该论文的关键创新在于提出了一个智能路由系统,能够根据输入数据的特征动态地选择最优的开源LLM进行编码。这种方法与传统的单一模型方法相比,能够更好地适应不同SDOH编码任务的特点,从而提高整体性能。此外,论文还提出了一个合成数据生成和验证范式,用于增加训练数据的规模,而无需使用受隐私保护的医疗记录。
关键设计:论文的关键设计包括:1) 语言模型路由器的设计:路由器的具体实现细节(例如,使用的模型、训练方法等)未知,但其核心功能是根据输入数据的特征选择最优LLM。2) 开源LLM池的构建:选择合适的开源LLM,并针对特定的SDOH代码进行优化。3) 合成数据生成和验证范式的设计:如何生成高质量的合成数据,并验证其有效性,是提高模型性能的关键。
🖼️ 关键图片

📊 实验亮点
该智能路由系统在13个SDOH代码上的平均准确率达到96.4%,优于闭源模型GPT-4o。此外,论文还提出了一个合成数据生成和验证范式,用于增加训练数据的规模,而无需使用受隐私保护的医疗记录,为解决数据隐私问题提供了一种新的思路。
🎯 应用场景
该研究成果可应用于医疗机构,辅助医生进行SDOH编码,提高编码效率和准确性,从而更好地了解患者的社会需求,制定个性化的治疗方案。此外,该方法还可以推广到其他医疗编码任务,例如疾病诊断、药物处方等,具有广阔的应用前景。
📄 摘要(原文)
Social Determinants of Health (SDOH), also known as Health-Related Social Needs (HSRN), play a significant role in patient health outcomes. The Centers for Disease Control and Prevention (CDC) introduced a subset of ICD-10 codes called Z-codes to recognize and measure SDOH. However, Z-codes are infrequently coded in a patient's Electronic Health Record (EHR), and instead, in many cases, need to be inferred from clinical notes. Previous research has shown that large language models (LLMs) show promise on extracting unstructured data from EHRs, but it can be difficult to identify a single model that performs best on varied coding tasks. Further, clinical notes contain protected health information posing a challenge for the use of closed-source language models from commercial vendors. The identification of open-source LLMs that can be run within health organizations and exhibit high performance on SDOH tasks is an important issue to solve. Here, we introduce an intelligent routing system for SDOH coding that uses a language model router to direct medical record data to open-source LLMs that demonstrate optimal performance on specific SDOH codes. This intelligent routing system exhibits state of the art performance of 96.4% accuracy averaged across 13 codes, including homelessness and food insecurity, outperforming closed models such as GPT-4o. We leveraged a publicly-available, deidentified dataset of medical record notes to run the router, but we also introduce a synthetic data generation and validation paradigm to increase the scale of training data without needing privacy-protected medical records. Together, we demonstrate an architecture for intelligent routing of inputs to task-optimal language models to achieve high performance across a set of medical coding sub-tasks.