MathChat: Benchmarking Mathematical Reasoning and Instruction Following in Multi-Turn Interactions
作者: Zhenwen Liang, Dian Yu, Wenhao Yu, Wenlin Yao, Zhihan Zhang, Xiangliang Zhang, Dong Yu
分类: cs.AI
发布日期: 2024-05-29
💡 一句话要点
提出MathChat基准测试,评估LLM在多轮数学推理和指令跟随中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话 数学推理 指令跟随 大型语言模型 基准测试
📋 核心要点
- 现有LLM在单轮数学问题上表现良好,但在多轮交互式数学问题解决中存在不足。
- 提出MathChat基准测试和MathChat sync数据集,用于评估和提升LLM在多轮数学推理中的能力。
- 实验表明,现有LLM在MathChat基准上表现不佳,而使用MathChat sync进行微调可以显著提升性能。
📝 摘要(中文)
大型语言模型(LLMs)在数学问题解决方面表现出令人印象深刻的能力,尤其是在单轮问答形式中。然而,现实世界的场景通常涉及需要多轮或交互式信息交换的数学问题解答,而LLMs在这些任务上的表现仍未得到充分探索。本文介绍MathChat,这是一个全面的基准,专门用于评估LLMs在更广泛的数学任务中的能力。这些任务的结构旨在评估模型在多轮交互和开放式生成方面的能力。我们评估了各种SOTA LLMs在MathChat基准上的性能,并且我们观察到,虽然这些模型在单轮问答中表现出色,但在需要持续推理和对话理解的更复杂场景中,它们的表现明显不佳。为了解决现有LLMs在面对多轮和开放式任务时的上述局限性,我们开发了MathChat sync,这是一个基于合成对话的数学数据集,用于LLM微调,重点是提高模型在对话中的交互和指令跟随能力。实验结果强调了使用多样化的、会话式指令调整数据集(如MathChatsync)训练LLMs的必要性。我们相信这项工作概述了一个有希望的方向,可以提高LLMs的多轮数学推理能力,从而推动LLMs在交互式数学问题解决和实际应用中更加熟练的发展。
🔬 方法详解
问题定义:论文旨在解决LLM在多轮交互式数学问题解决中表现不佳的问题。现有LLM在单轮问答中表现出色,但在需要持续推理和对话理解的复杂场景中,性能显著下降。这主要是因为现有数据集和训练方法侧重于单轮问答,缺乏对多轮交互和开放式生成的支持。
核心思路:论文的核心思路是构建一个专门用于评估和提升LLM在多轮数学推理和指令跟随能力的基准测试和数据集。通过MathChat基准测试,可以全面评估LLM在多轮交互中的表现。通过MathChat sync数据集,可以对LLM进行微调,提高其交互和指令跟随能力。
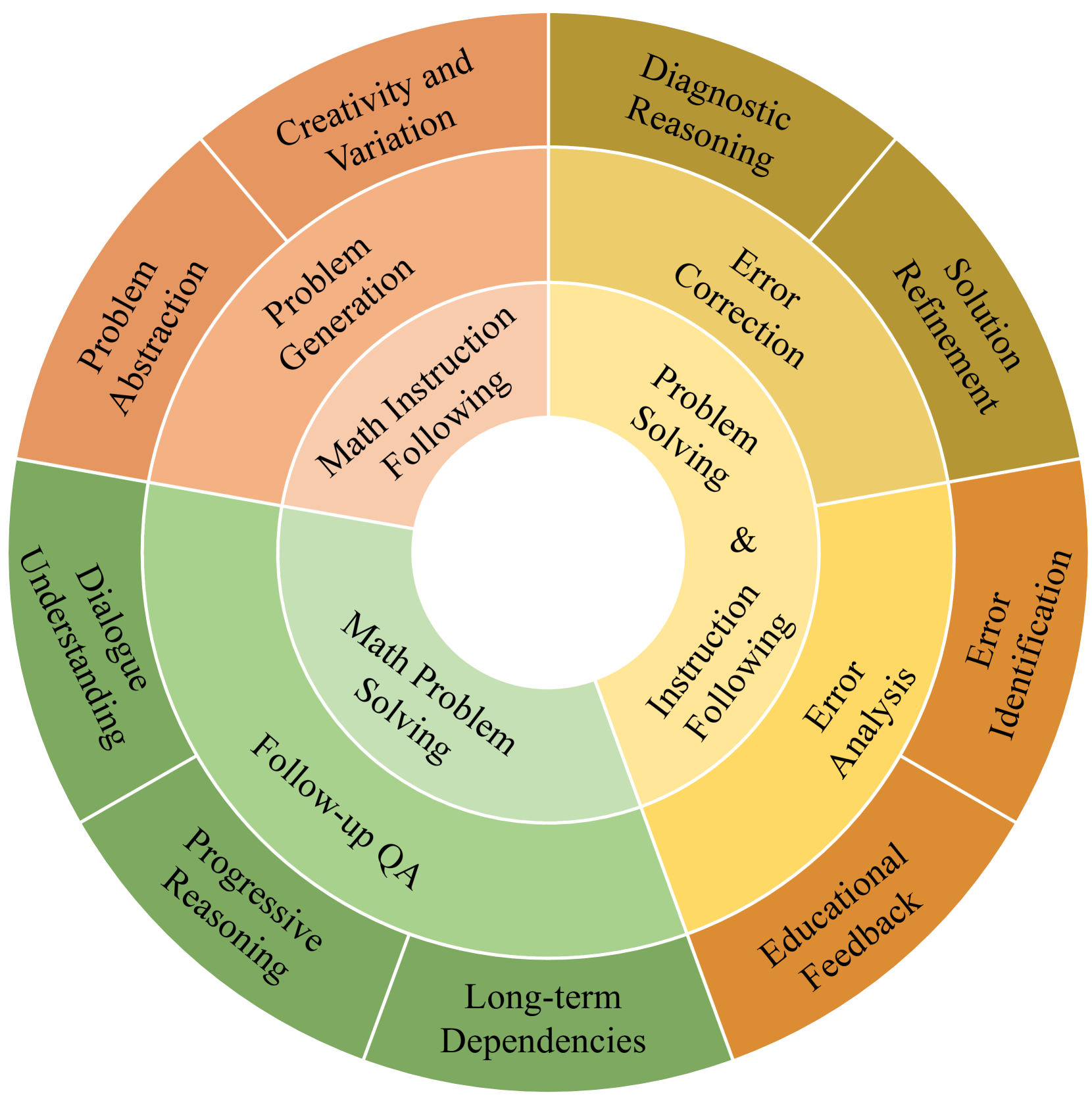
技术框架:整体框架包括两个主要部分:MathChat基准测试和MathChat sync数据集。MathChat基准测试包含一系列多轮数学问题,旨在评估LLM在不同场景下的推理和对话能力。MathChat sync数据集是一个基于合成对话的数学数据集,用于LLM微调,以提高其交互和指令跟随能力。
关键创新:论文的关键创新在于提出了MathChat基准测试和MathChat sync数据集,专门用于评估和提升LLM在多轮数学推理和指令跟随能力。与现有数据集相比,MathChat sync数据集更加注重多轮交互和开放式生成,能够更好地反映现实世界的数学问题解决场景。
关键设计:MathChat sync数据集的生成过程未知,但强调了对话的多样性,以覆盖各种交互模式和指令类型。论文可能使用了某种策略来生成高质量的对话数据,例如基于规则的生成、基于模型的生成或人工标注。损失函数和网络结构等技术细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有SOTA LLM在MathChat基准测试中表现不佳,表明它们在多轮数学推理方面存在局限性。使用MathChat sync数据集进行微调后,LLM在MathChat基准测试中的性能得到显著提升,证明了该数据集的有效性。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于智能教育、数学辅导机器人、智能客服等领域。通过提升LLM在多轮数学推理中的能力,可以开发出更加智能和高效的数学学习工具,帮助学生更好地理解和解决数学问题。此外,该研究还可以促进LLM在其他需要多轮交互和复杂推理的领域的应用。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive capabilities in mathematical problem solving, particularly in single turn question answering formats. However, real world scenarios often involve mathematical question answering that requires multi turn or interactive information exchanges, and the performance of LLMs on these tasks is still underexplored. This paper introduces MathChat, a comprehensive benchmark specifically designed to evaluate LLMs across a broader spectrum of mathematical tasks. These tasks are structured to assess the models' abilities in multiturn interactions and open ended generation. We evaluate the performance of various SOTA LLMs on the MathChat benchmark, and we observe that while these models excel in single turn question answering, they significantly underperform in more complex scenarios that require sustained reasoning and dialogue understanding. To address the above limitations of existing LLMs when faced with multiturn and open ended tasks, we develop MathChat sync, a synthetic dialogue based math dataset for LLM finetuning, focusing on improving models' interaction and instruction following capabilities in conversations. Experimental results emphasize the need for training LLMs with diverse, conversational instruction tuning datasets like MathChatsync. We believe this work outlines one promising direction for improving the multiturn mathematical reasoning abilities of LLMs, thus pushing forward the development of LLMs that are more adept at interactive mathematical problem solving and real world applications.