Optimizing Foundation Model Inference on a Many-tiny-core Open-source RISC-V Platform
作者: Viviane Potocnik, Luca Colagrande, Tim Fischer, Luca Bertaccini, Daniele Jahier Pagliari, Alessio Burrello, Luca Benini
分类: cs.DC, cs.AI, cs.AR
发布日期: 2024-05-29
备注: 14 pages, 10 figures, 4 tables, IEEE Transactions on Circuits and Systems for Artificial Intelligence
💡 一句话要点
在多微核RISC-V平台上优化Transformer基础模型推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RISC-V Transformer模型 推理优化 多微核平台 SIMD扩展 DMA引擎 边缘计算 开源硬件
📋 核心要点
- 现有Transformer模型推理主要依赖GPU或专用加速器,RISC-V通用平台关注不足。
- 论文提出在多微核RISC-V平台上,通过优化Softmax、SIMD扩展和DMA引擎,加速Transformer推理。
- 实验表明,优化后的实现在编码器模型上加速12.8倍,解码器模型上加速高达35.6倍,且能效优于SoA加速器。
📝 摘要(中文)
基于Transformer的基础模型在自然语言处理(NLP)和计算机视觉(CV)等领域至关重要。这些模型主要部署在高性能GPU或具有高度定制化、专有指令集的硬连线加速器上。目前,基于RISC-V的通用平台受到的关注有限。本文首次展示了Transformer模型在开源多微核RISC-V平台上的端到端推理结果,该平台实现了分布式Softmax原语,并利用ISA扩展进行SIMD浮点操作数流式传输和指令重复,以及专用DMA引擎以最大限度地减少昂贵的主存访问并容忍其延迟。我们重点关注两种基础Transformer拓扑结构:仅编码器和仅解码器模型。对于仅编码器模型,我们展示了优化后的实现与基线版本之间高达12.8倍的加速。我们实现了超过79%的FPU利用率和294 GFLOPS/W,在利用硬件平台的同时,性能超过了最先进的(SoA)加速器2倍以上,并实现了相当的每计算单元吞吐量。对于仅解码器拓扑,与基线实现相比,我们在非自回归(NAR)模式下实现了16.1倍的加速,在自回归(AR)模式下实现了高达35.6倍的加速。与最佳SoA专用加速器相比,我们实现了2.04倍更高的FPU利用率。
🔬 方法详解
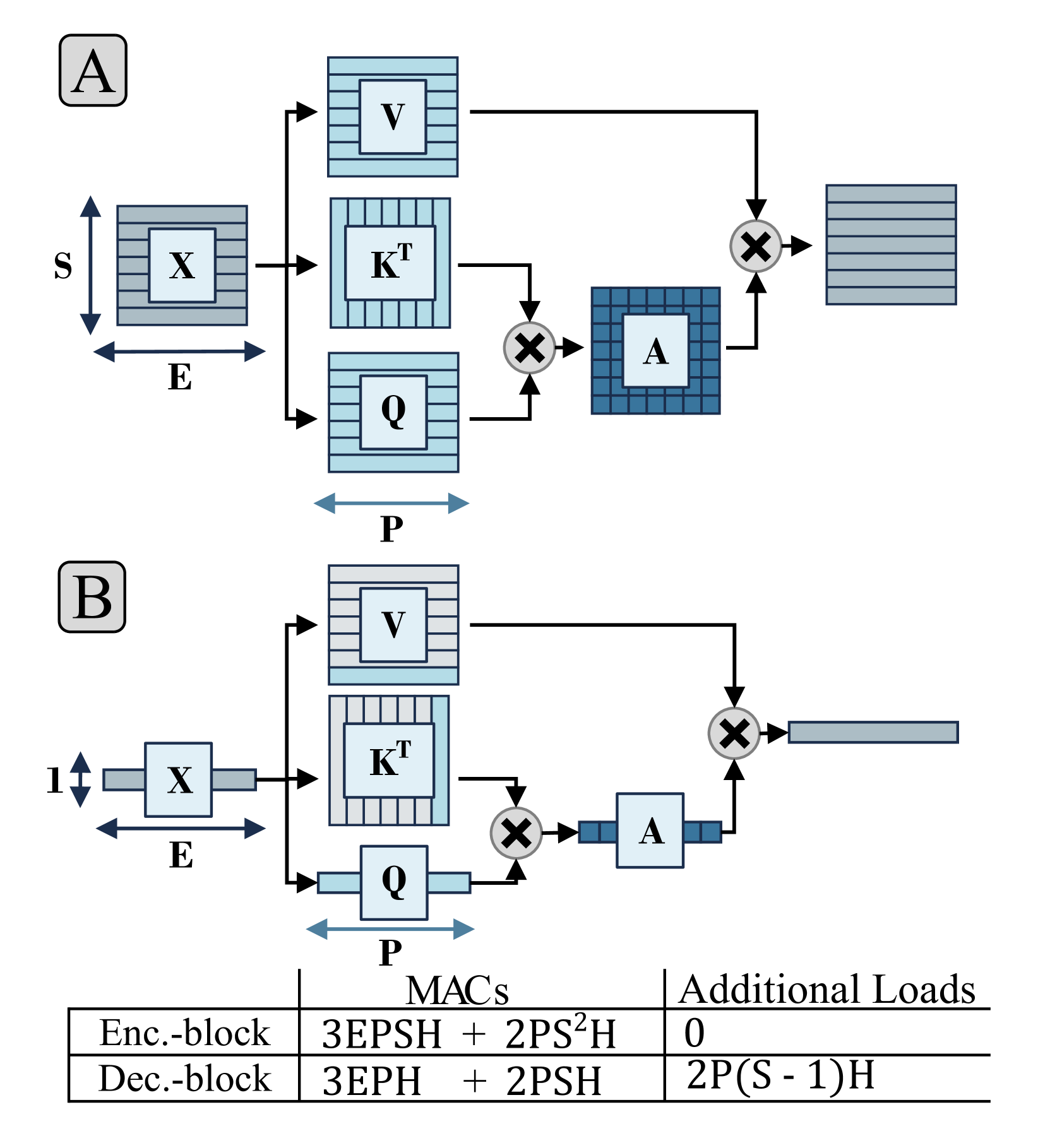
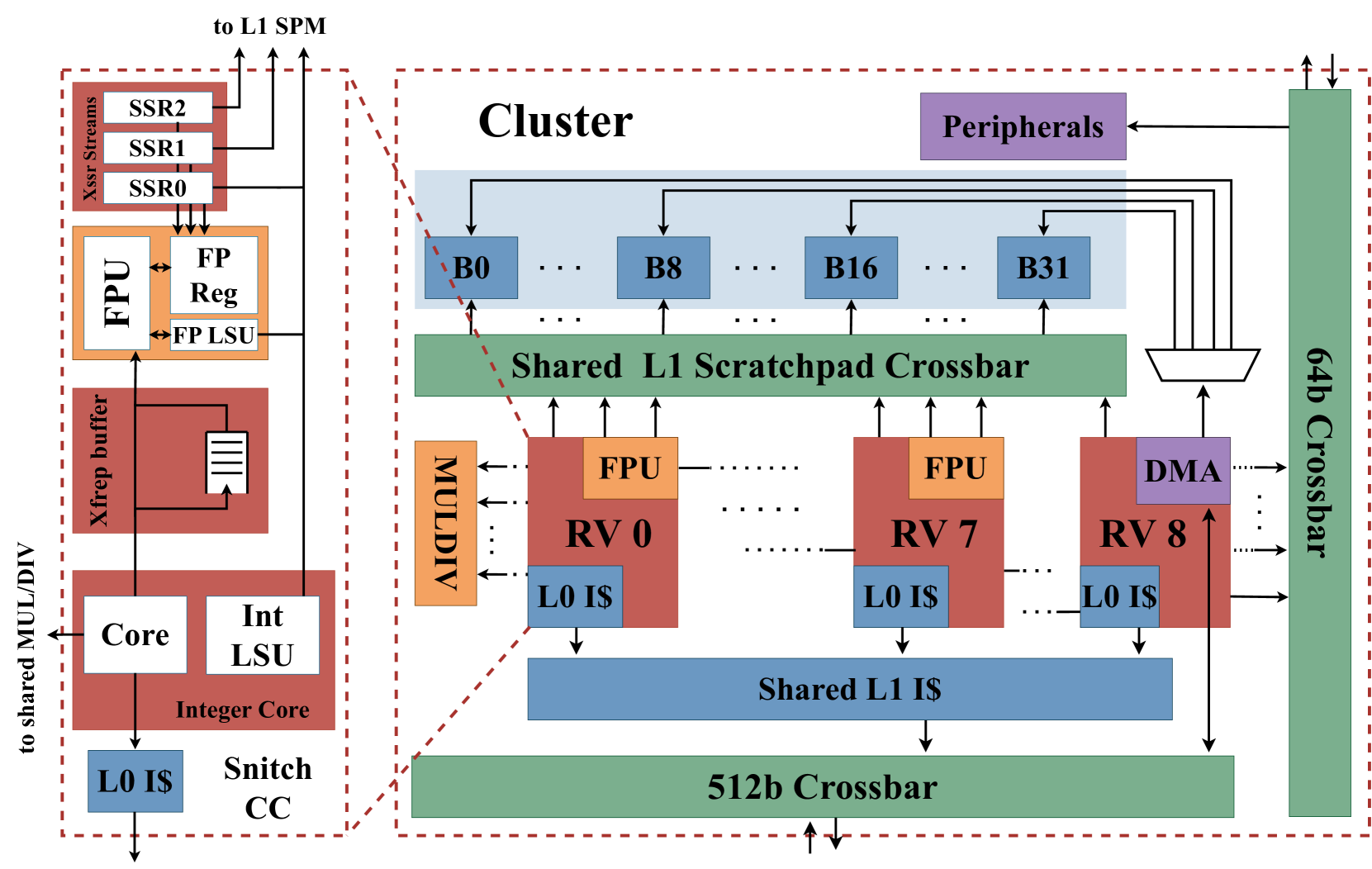
问题定义:论文旨在解决Transformer模型在RISC-V通用平台上推理效率低下的问题。现有方法主要依赖GPU或专用加速器,成本高昂且缺乏灵活性。RISC-V平台虽然具有开源、低功耗等优点,但在Transformer模型推理方面性能不足,主要瓶颈在于计算密集型操作(如Softmax)和频繁的内存访问。
核心思路:论文的核心思路是通过软硬件协同优化,充分利用多微核RISC-V平台的并行计算能力,并减少内存访问开销。具体而言,通过分布式Softmax原语、SIMD指令扩展和专用DMA引擎,加速计算密集型操作,并降低内存访问延迟。
技术框架:整体框架包括以下几个主要模块:1) 多微核RISC-V平台:作为硬件基础,提供并行计算能力。2) 分布式Softmax原语:优化Softmax计算,减少通信开销。3) SIMD指令扩展:利用RISC-V ISA扩展,加速浮点运算。4) 专用DMA引擎:减少主存访问,容忍延迟。5) 软件优化:针对Transformer模型结构,进行代码优化和调度。
关键创新:论文的关键创新在于针对RISC-V平台的软硬件协同优化方案。与现有方法相比,该方案充分利用了RISC-V平台的特点,通过定制化的硬件加速和软件优化,实现了更高的性能和能效。特别是在分布式Softmax原语和专用DMA引擎的设计上,体现了对RISC-V平台架构的深入理解。
关键设计:论文中,分布式Softmax原语的设计考虑了多核之间的通信开销,采用了一种高效的通信策略。SIMD指令扩展则针对Transformer模型中的浮点运算进行了优化,提高了计算效率。专用DMA引擎的设计则考虑了内存访问的延迟,采用了一种预取机制,减少了内存访问的等待时间。具体的参数设置和网络结构则根据不同的Transformer模型进行了调整。
🖼️ 关键图片

📊 实验亮点
论文实验结果表明,在仅编码器模型上,优化后的实现相比基线版本加速高达12.8倍,FPU利用率超过79%,能效达到294 GFLOPS/W,超过了现有SoA加速器2倍以上。在仅解码器模型上,非自回归模式下加速16.1倍,自回归模式下加速高达35.6倍。与最佳SoA专用加速器相比,FPU利用率提高了2.04倍,充分验证了该方案的有效性。
🎯 应用场景
该研究成果可应用于边缘计算设备、物联网设备等资源受限的场景,实现低功耗、高性能的Transformer模型推理。例如,在智能家居、自动驾驶等领域,可以利用该技术实现本地化的自然语言处理和计算机视觉任务,提高响应速度和隐私保护能力。此外,该研究也有助于推动RISC-V生态系统的发展,促进开源硬件和软件的协同创新。
📄 摘要(原文)
Transformer-based foundation models have become crucial for various domains, most notably natural language processing (NLP) or computer vision (CV). These models are predominantly deployed on high-performance GPUs or hardwired accelerators with highly customized, proprietary instruction sets. Until now, limited attention has been given to RISC-V-based general-purpose platforms. In our work, we present the first end-to-end inference results of transformer models on an open-source many-tiny-core RISC-V platform implementing distributed Softmax primitives and leveraging ISA extensions for SIMD floating-point operand streaming and instruction repetition, as well as specialized DMA engines to minimize costly main memory accesses and to tolerate their latency. We focus on two foundational transformer topologies, encoder-only and decoder-only models. For encoder-only models, we demonstrate a speedup of up to 12.8x between the most optimized implementation and the baseline version. We reach over 79% FPU utilization and 294 GFLOPS/W, outperforming State-of-the-Art (SoA) accelerators by more than 2x utilizing the HW platform while achieving comparable throughput per computational unit. For decoder-only topologies, we achieve 16.1x speedup in the Non-Autoregressive (NAR) mode and up to 35.6x speedup in the Autoregressive (AR) mode compared to the baseline implementation. Compared to the best SoA dedicated accelerator, we achieve 2.04x higher FPU utilization.