Unified Preference Optimization: Language Model Alignment Beyond the Preference Frontier
作者: Anirudhan Badrinath, Prabhat Agarwal, Jiajing Xu
分类: cs.AI
发布日期: 2024-05-28 (更新: 2025-05-25)
备注: Accepted at Transactions on Machine Learning Research (TMLR)
💡 一句话要点
提出统一偏好优化(UPO),在DPO框架下优化用户和设计者偏好,无需额外数据。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型对齐 偏好优化 直接偏好优化 辅助目标 多目标优化
📋 核心要点
- 现有DPO方法难以兼顾用户偏好和设计者定义的辅助目标,例如风格控制和有害内容过滤。
- 论文提出统一偏好优化(UPO),通过分解偏好和辅助目标,在DPO框架下实现多目标优化。
- UPO无需额外数据或复杂调整,即可在多个基准测试中达到或超过现有对齐方法的性能。
📝 摘要(中文)
为了对齐大型语言模型(LLM),先前的工作利用了基于人类反馈的强化学习(RLHF)或直接偏好优化(DPO)的变体。虽然DPO提供了一个基于最大似然估计的更简单的框架,但它牺牲了轻松调整语言模型以根据LLM设计者的偏好最大化辅助的、非偏好目标的能力(例如,调整词汇风格或最小化特定类型的有害内容)。关键是,这些设计者目标可能没有充分的人工标记或在可用数据中表示,与用户偏好对齐,甚至无法通过二元偏好对来处理。为了利用DPO的简单性和性能以及RL的通用性,我们提出了一种统一的方法。基于偏好和辅助目标的简单分解,我们允许调整LLM以优化用户和设计者偏好,而无需任何额外的专门或偏好数据、计算成本、稳定性“调整”或训练不稳定性。所提出的方法,统一偏好优化,展示了有效推广到用户偏好和辅助目标的能力,同时在各种模型大小的一系列具有挑战性的基准上保持或超过对齐性能。
🔬 方法详解
问题定义:现有基于DPO的语言模型对齐方法,虽然简单高效,但难以同时优化用户偏好和设计者定义的辅助目标。设计者目标可能缺乏充足的标注数据,与用户偏好不一致,甚至难以用二元偏好对表示。这限制了模型在风格控制、安全性等方面的灵活性和可控性。
核心思路:UPO的核心思想是将整体优化目标分解为用户偏好和辅助目标两部分,并分别进行优化。通过这种分解,可以利用DPO框架处理用户偏好,同时引入额外的损失函数来优化辅助目标。这种方法避免了直接对所有目标进行偏好排序的困难,也无需额外的偏好数据。
技术框架:UPO的整体框架仍然基于DPO。首先,使用标准的DPO方法,基于用户偏好数据训练语言模型。然后,引入辅助损失函数,用于优化设计者定义的辅助目标。辅助损失函数可以直接作用于模型的输出,例如,可以使用正则化项来控制模型的风格,或者使用分类器来惩罚有害内容的生成。整个训练过程可以看作是在DPO的基础上,增加了一个额外的优化步骤。
关键创新:UPO的关键创新在于将偏好优化问题分解为用户偏好和辅助目标两部分,并分别进行优化。这种分解使得可以在DPO框架下灵活地引入各种辅助目标,而无需修改DPO的核心算法。此外,UPO无需额外的偏好数据,降低了训练成本。
关键设计:UPO的关键设计在于辅助损失函数的选择和权重。辅助损失函数的选择取决于具体的辅助目标,例如,可以使用交叉熵损失函数来训练一个有害内容分类器,然后使用该分类器的输出作为辅助损失函数。辅助损失函数的权重需要仔细调整,以平衡用户偏好和辅助目标之间的关系。
🖼️ 关键图片

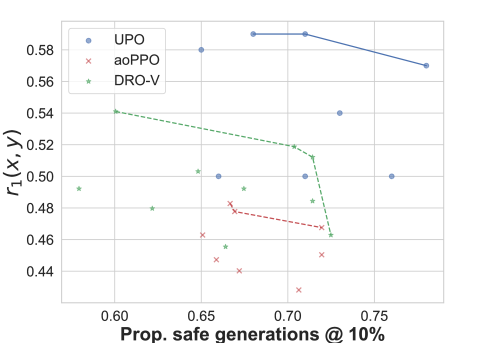
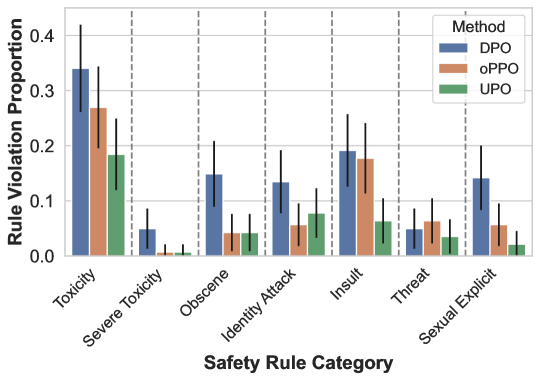
📊 实验亮点
实验结果表明,UPO在多个基准测试中达到了与现有对齐方法相当甚至更高的性能。例如,在安全性评估方面,UPO能够有效降低模型生成有害内容的概率,同时保持良好的对话质量。此外,UPO还展示了在风格控制方面的能力,能够生成符合特定风格要求的文本。
🎯 应用场景
UPO可应用于各种需要兼顾用户偏好和设计者目标的语言模型对齐场景,例如,可以用于训练更安全、更符合伦理规范的聊天机器人,也可以用于生成具有特定风格的文本内容。该方法在内容生成、智能客服、教育辅导等领域具有广泛的应用前景。
📄 摘要(原文)
For aligning large language models (LLMs), prior work has leveraged reinforcement learning via human feedback (RLHF) or variations of direct preference optimization (DPO). While DPO offers a simpler framework based on maximum likelihood estimation, it compromises on the ability to easily tune language models to maximize auxiliary, non-preferential objectives according to the LLM designer's preferences (e.g., tuning lexical style or minimizing specific kinds of harmful content). Critically, these designer objectives may not be amply human-labeled or represented in available data, align with user preferences, or even be able to be captured tractably by binary preference pairs. To leverage the simplicity and performance of DPO with the generality of RL, we propose a unified approach. Based on a simple decomposition of preference and auxiliary objectives, we allow for tuning LLMs to optimize user and designer preferences without any additional specialized or preference data, computational cost, stability ``tweaks'', or training instability. The proposed method, Unified Preference Optimization, shows the ability to effectively generalize to user preferences and auxiliary objectives, while preserving or surpassing alignment performance on challenging benchmarks across a range of model sizes.