The Evolution of Multimodal Model Architectures
作者: Shakti N. Wadekar, Abhishek Chaurasia, Aman Chadha, Eugenio Culurciello
分类: cs.AI, cs.CL, cs.CV, cs.LG, eess.AS
发布日期: 2024-05-28
备注: 30 pages, 6 tables, 7 figures
💡 一句话要点
对多模态模型架构进行系统性分类,促进多模态领域发展监控。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 模型架构 深度学习 模态融合 交叉注意力 Tokenizer 多模态学习
📋 核心要点
- 现有方法缺乏对多模态模型架构的系统性分类,阻碍了对该领域发展的有效监控。
- 论文提出基于模态融合方式对多模态模型架构进行分类,分为深度融合和早期融合两大类。
- 研究分析了四种架构类型的优缺点,为模型选择提供了指导,并指出了C型架构的潜力。
📝 摘要(中文)
本研究独特地识别并描述了当前多模态领域中四种流行的多模态模型架构模式。通过架构类型对模型进行系统分类,有助于监控多模态领域的发展。与最近介绍多模态架构一般信息的综述论文不同,本研究对架构细节进行了全面探索,并确定了四种特定的架构类型。这些类型的区别在于它们将多模态输入集成到深度神经网络模型中的各自方法。前两种类型(A型和B型)在模型的内部层中深度融合多模态输入,而后两种类型(C型和D型)则在输入阶段促进早期融合。A型采用标准交叉注意力机制,而B型则利用定制设计的层在内部层中进行模态融合。另一方面,C型利用模态特定的编码器,而D型则利用tokenizer来处理模型输入阶段的模态。所识别的架构类型有助于监控任意到任意多模态模型的发展。值得注意的是,C型和D型目前在构建任意到任意多模态模型中更受欢迎。C型以其非tokenizing多模态模型架构而著称,正在成为D型(使用输入tokenizing技术)的可行替代方案。为了帮助模型选择,本研究根据数据和计算需求、架构复杂性、可扩展性、简化添加模态、训练目标以及任意到任意多模态生成能力,突出了每种架构类型的优点和缺点。
🔬 方法详解
问题定义:当前多模态模型种类繁多,缺乏统一的分类标准,难以追踪和理解不同架构的演进趋势。现有综述性工作通常只提供一般性信息,缺乏对架构细节的深入分析,无法有效指导模型选择和设计。
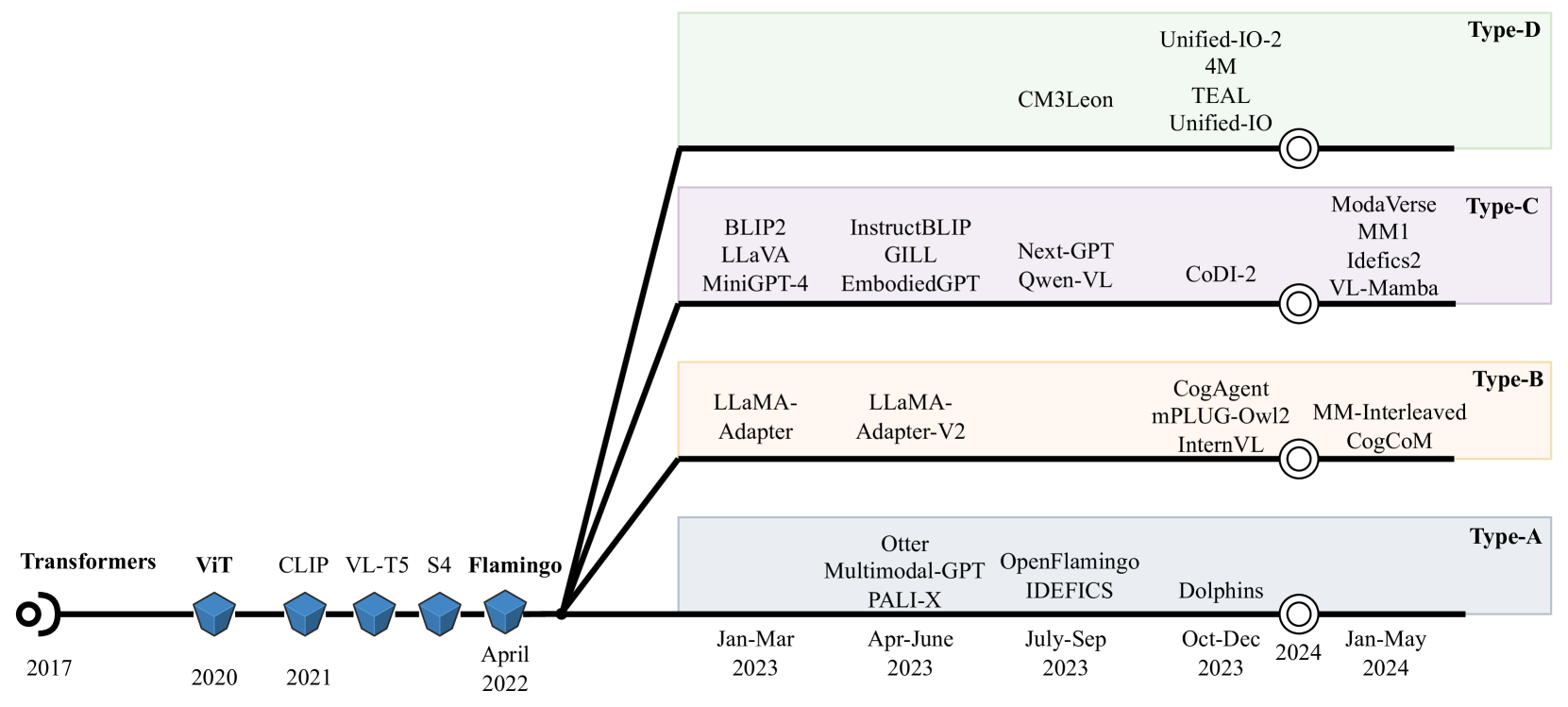
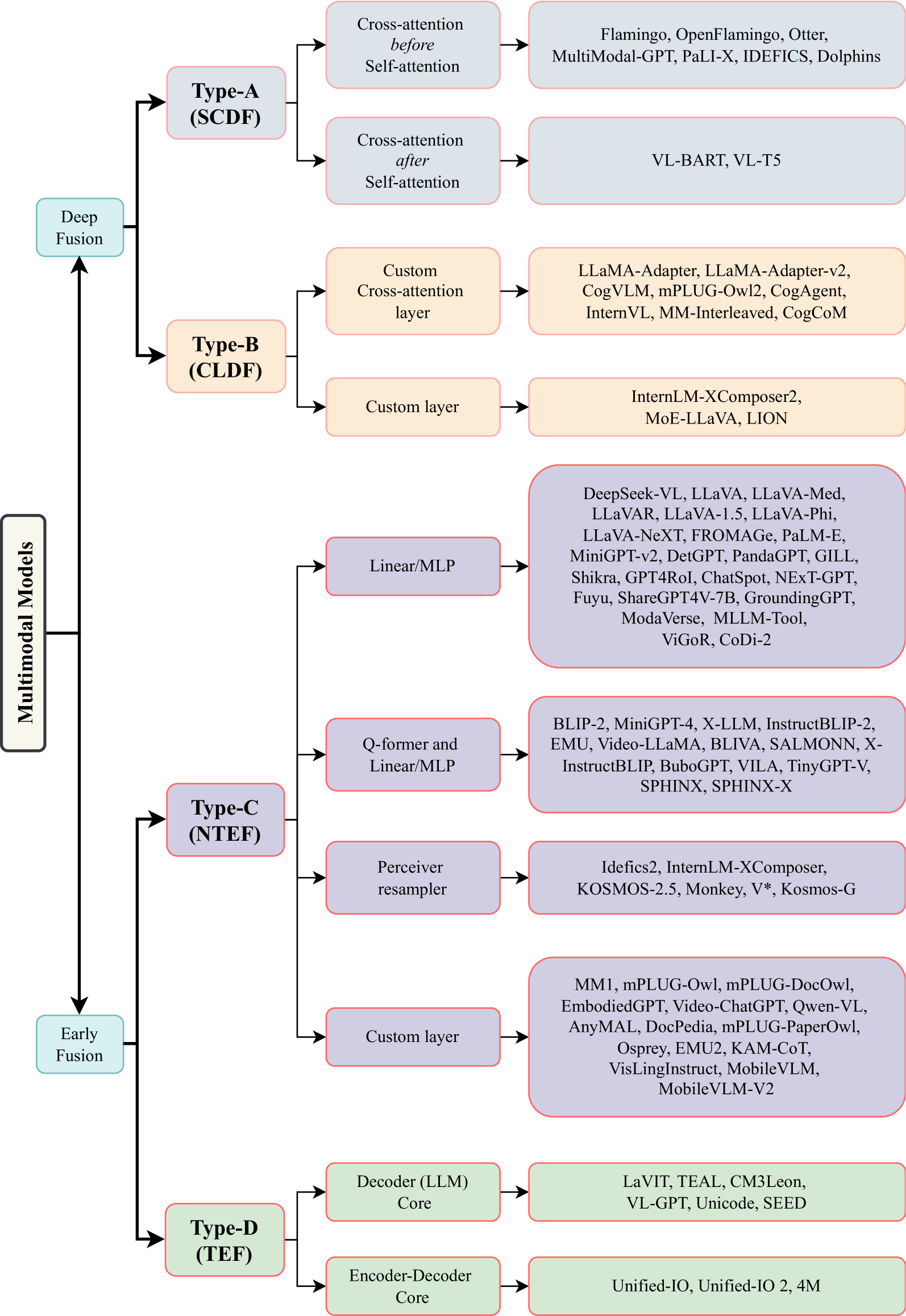
核心思路:论文的核心思路是根据多模态输入在模型中的融合方式,将现有模型架构划分为四种类型:A型(标准交叉注意力深度融合)、B型(自定义层深度融合)、C型(模态特定编码器早期融合)和D型(Tokenizer早期融合)。这种分类方式能够清晰地反映不同架构在模态交互上的差异。
技术框架:该研究通过对现有文献的深入分析,识别出四种主流的多模态模型架构类型。A型和B型在模型的内部层进行深度融合,而C型和D型则在输入阶段进行早期融合。A型使用标准的交叉注意力机制,B型则使用定制设计的层进行模态融合。C型使用模态特定的编码器,D型使用tokenizer处理输入模态。
关键创新:该研究的关键创新在于提出了一个系统性的多模态模型架构分类框架,并深入分析了每种架构类型的优缺点。这种分类方法有助于研究人员更好地理解不同架构的特性,并为模型选择和设计提供指导。此外,该研究还指出了C型架构(非tokenizing多模态模型架构)作为D型架构(使用输入tokenizing技术)的潜在替代方案。
关键设计:该研究的关键设计在于根据数据和计算需求、架构复杂性、可扩展性、简化添加模态、训练目标以及任意到任意多模态生成能力等因素,对每种架构类型的优缺点进行了详细分析。这些分析结果可以帮助研究人员根据具体应用场景选择合适的模型架构。
🖼️ 关键图片

📊 实验亮点
论文通过对现有模型的分析,指出了C型架构(非tokenizing多模态模型架构)作为D型架构(使用输入tokenizing技术)的潜在替代方案。C型架构在某些场景下可能具有更高的效率和更低的计算成本,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于多模态信息检索、多模态情感分析、多模态机器翻译、视觉问答等领域。通过选择合适的模型架构,可以提升模型性能,降低计算成本,并简化多模态数据的处理流程。该研究还有助于推动任意到任意多模态生成技术的发展。
📄 摘要(原文)
This work uniquely identifies and characterizes four prevalent multimodal model architectural patterns in the contemporary multimodal landscape. Systematically categorizing models by architecture type facilitates monitoring of developments in the multimodal domain. Distinct from recent survey papers that present general information on multimodal architectures, this research conducts a comprehensive exploration of architectural details and identifies four specific architectural types. The types are distinguished by their respective methodologies for integrating multimodal inputs into the deep neural network model. The first two types (Type A and B) deeply fuses multimodal inputs within the internal layers of the model, whereas the following two types (Type C and D) facilitate early fusion at the input stage. Type-A employs standard cross-attention, whereas Type-B utilizes custom-designed layers for modality fusion within the internal layers. On the other hand, Type-C utilizes modality-specific encoders, while Type-D leverages tokenizers to process the modalities at the model's input stage. The identified architecture types aid the monitoring of any-to-any multimodal model development. Notably, Type-C and Type-D are currently favored in the construction of any-to-any multimodal models. Type-C, distinguished by its non-tokenizing multimodal model architecture, is emerging as a viable alternative to Type-D, which utilizes input-tokenizing techniques. To assist in model selection, this work highlights the advantages and disadvantages of each architecture type based on data and compute requirements, architecture complexity, scalability, simplification of adding modalities, training objectives, and any-to-any multimodal generation capability.