Video Enriched Retrieval Augmented Generation Using Aligned Video Captions
作者: Kevin Dela Rosa
分类: cs.AI, cs.CV, cs.IR
发布日期: 2024-05-27
备注: SIGIR 2024 Workshop on Multimodal Representation and Retrieval (MRR 2024)
💡 一句话要点
提出利用对齐视频字幕增强检索增强生成,提升视频信息在聊天助手中的应用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 检索增强生成 视觉字幕 多模态学习 大型语言模型
📋 核心要点
- 现有RAG系统在处理视频信息时,直接使用视频帧会导致上下文窗口快速饱和,效率低下。
- 论文提出使用对齐的视觉字幕,将视频内容转化为文本,便于LLM理解和处理,减少上下文占用。
- 论文贡献包括数据集的构建和自动评估流程的设计,旨在推动视频RAG领域的研究进展。
📝 摘要(中文)
本文提出使用“对齐的视觉字幕”作为一种机制,将视频中包含的信息集成到基于检索增强生成(RAG)的聊天助手系统中。这些字幕能够描述大型语料库中视频的视觉和音频内容,同时具有文本格式的优势,易于推理并融入大型语言模型(LLM)提示中。此外,与直接采样视频帧相比,视觉字幕通常需要更少的媒体内容插入到多模态LLM上下文窗口中,避免了上下文窗口被快速填满的问题。视觉字幕还可以通过提示原始基础模型/字幕器以获取特定的视觉细节或进行微调来适应特定的用例。为了促进该领域的发展,我们整理了一个数据集,并描述了在常见RAG任务上的自动评估程序。
🔬 方法详解
问题定义:现有基于RAG的聊天助手系统在处理视频信息时,通常直接使用视频帧作为输入。这种方法的主要痛点在于,视频帧数据量大,容易迅速占用LLM的上下文窗口,导致信息处理效率低下,且难以进行有效的推理和理解。此外,针对特定任务定制视频信息也较为困难。
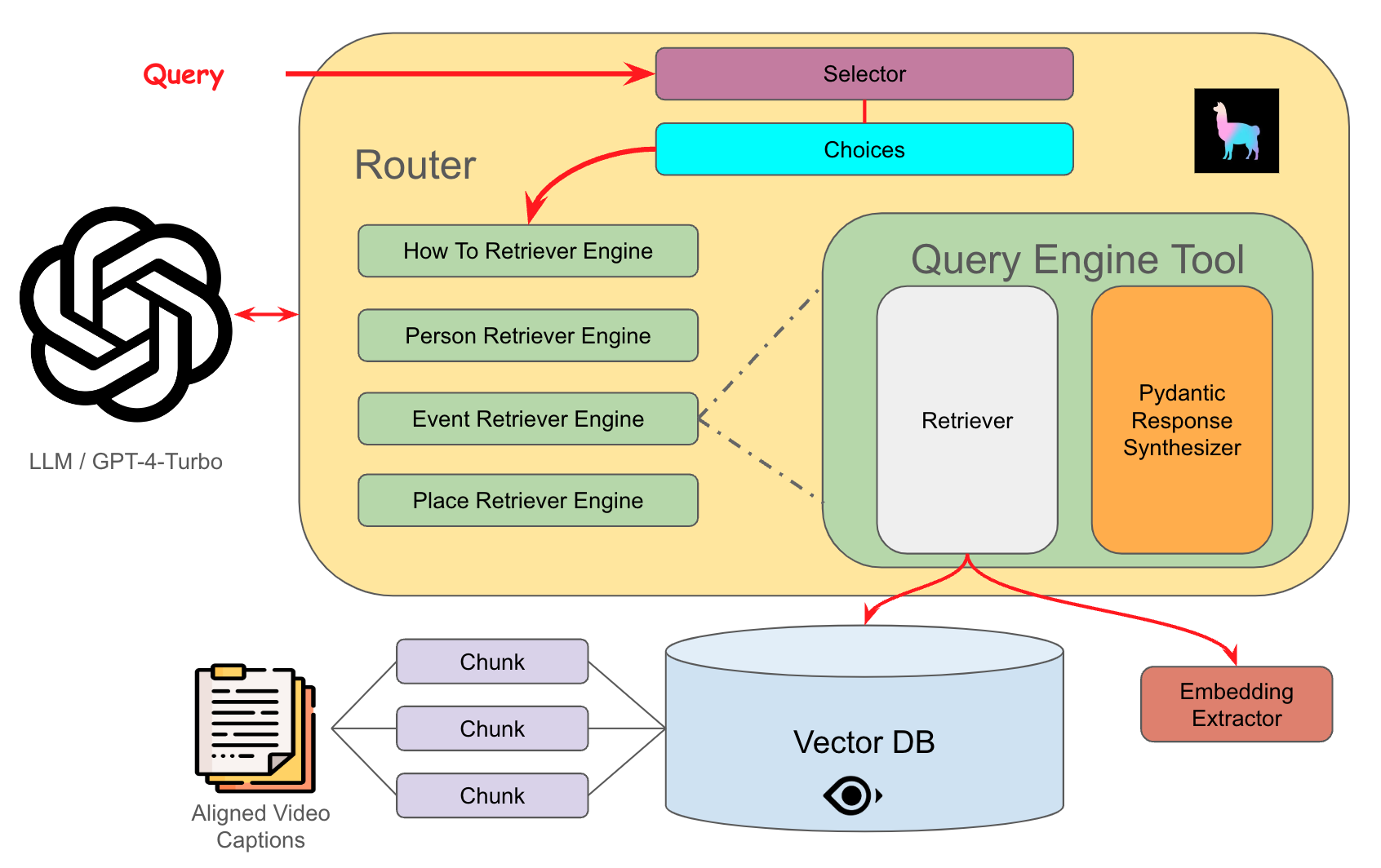
核心思路:论文的核心思路是将视频的视觉和音频内容转化为文本描述,即“对齐的视觉字幕”。通过这种方式,视频信息可以以文本形式输入LLM,从而减少上下文占用,提高处理效率,并方便进行推理和定制。这种方法利用了LLM对文本的强大理解能力,将多模态信息转化为单模态文本信息。
技术框架:整体框架包含以下几个主要步骤:1) 使用预训练的视觉字幕模型生成视频的视觉字幕。2) 将生成的视觉字幕与用户查询一起输入LLM。3) LLM基于字幕和查询生成回复。该框架的关键在于视觉字幕的生成质量,以及LLM如何有效地利用这些字幕进行推理和生成。
关键创新:论文的关键创新在于提出使用“对齐的视觉字幕”作为视频RAG系统的核心组成部分。与直接使用视频帧相比,这种方法能够显著减少上下文占用,提高处理效率,并方便进行定制。此外,论文还贡献了一个数据集和自动评估流程,为该领域的研究提供了基础。
关键设计:论文的关键设计包括:1) 如何选择和使用预训练的视觉字幕模型,以生成高质量的视觉字幕。2) 如何设计LLM的提示,以引导其有效地利用视觉字幕进行推理和生成。3) 如何构建自动评估流程,以评估不同方法的性能。论文可能还涉及对视觉字幕模型进行微调,以适应特定的用例。
🖼️ 关键图片


📊 实验亮点
论文的主要亮点在于提出了使用对齐视频字幕的RAG方法,并构建了相应的数据集和评估流程。虽然论文中没有提供具体的性能数据,但其核心思想在于通过文本化的视频信息表示,有效缓解了多模态信息处理中的上下文窗口限制问题,为视频RAG领域的研究提供了一个新的方向。
🎯 应用场景
该研究成果可应用于智能客服、视频内容理解、教育视频辅助、视频搜索等领域。通过将视频信息转化为文本描述,可以使聊天机器人更好地理解视频内容,并为用户提供更准确、更全面的信息服务。未来,该技术有望应用于更广泛的视频相关任务,例如视频摘要、视频问答等。
📄 摘要(原文)
In this work, we propose the use of "aligned visual captions" as a mechanism for integrating information contained within videos into retrieval augmented generation (RAG) based chat assistant systems. These captions are able to describe the visual and audio content of videos in a large corpus while having the advantage of being in a textual format that is both easy to reason about & incorporate into large language model (LLM) prompts, but also typically require less multimedia content to be inserted into the multimodal LLM context window, where typical configurations can aggressively fill up the context window by sampling video frames from the source video. Furthermore, visual captions can be adapted to specific use cases by prompting the original foundational model / captioner for particular visual details or fine tuning. In hopes of helping advancing progress in this area, we curate a dataset and describe automatic evaluation procedures on common RAG tasks.