Exploring and steering the moral compass of Large Language Models
作者: Alejandro Tlaie
分类: cs.AI, cs.CL
发布日期: 2024-05-27 (更新: 2024-06-06)
💡 一句话要点
探索并引导大型语言模型的道德准则
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伦理道德 道德准则 激活引导 价值观 功利主义 自由主义 伦理困境
📋 核心要点
- 大型语言模型在自动化决策中作用日益重要,但其潜在的伦理风险和道德倾向亟待评估。
- 论文提出一种新颖的相似性激活引导技术,旨在可控地干预和调整LLM的道德偏好。
- 实验表明,不同架构的LLM在伦理选择上存在显著差异,且可以通过激活引导技术进行调整。
📝 摘要(中文)
大型语言模型(LLMs)已成为推动各行业自动化和决策的核心,同时也引发了重要的伦理问题。本研究对最先进的LLMs进行了全面的比较分析,以评估它们的道德概况。我们对几种最先进的模型进行了一系列伦理困境测试,发现所有专有模型主要倾向于功利主义,而所有开源模型主要符合基于价值观的伦理。此外,在使用道德基础问卷时,我们探测的所有模型(Llama 2-7B除外)都表现出强烈的自由主义倾向。最后,为了因果干预其中一个研究模型,我们提出了一种新颖的、特定于相似性的激活引导技术。使用这种方法,我们能够可靠地将模型的道德准则引导到不同的伦理学派。所有这些结果表明,已部署的LLMs中存在一个通常被忽视的伦理维度。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在伦理道德方面存在的潜在问题。现有方法缺乏对LLMs道德倾向的系统性评估和可控干预手段,使得LLMs在实际应用中可能产生不符合伦理规范的输出。因此,如何理解、评估并引导LLMs的道德准则成为一个重要的研究问题。
核心思路:论文的核心思路是通过构建一系列伦理困境测试,评估不同LLMs的道德倾向,并利用一种新颖的激活引导技术,实现对LLMs道德准则的可控干预。这种方法旨在揭示LLMs中存在的伦理维度,并提供一种调整LLMs道德偏好的有效途径。
技术框架:论文的技术框架主要包括三个阶段:1) 伦理困境测试:设计一系列伦理困境,输入到不同的LLMs中,并分析其输出结果,从而评估LLMs的道德倾向。2) 道德基础问卷:使用道德基础问卷进一步分析LLMs的道德价值观。3) 激活引导:提出一种基于相似性的激活引导技术,通过干预LLMs的内部激活,实现对其道德准则的调整。
关键创新:论文最重要的技术创新点在于提出了相似性特定的激活引导技术。该技术能够根据特定的伦理目标,选择合适的激活向量,并将其注入到LLM的内部状态中,从而实现对LLM道德准则的精确控制。与传统的微调方法相比,该技术具有更高的灵活性和可控性。
关键设计:激活引导技术的关键设计包括:1) 相似性度量:使用余弦相似度等方法,衡量不同激活向量之间的相似性。2) 激活向量选择:根据伦理目标,选择与目标伦理准则相关的激活向量。3) 激活注入:将选定的激活向量注入到LLM的特定层中,从而影响LLM的输出结果。
🖼️ 关键图片
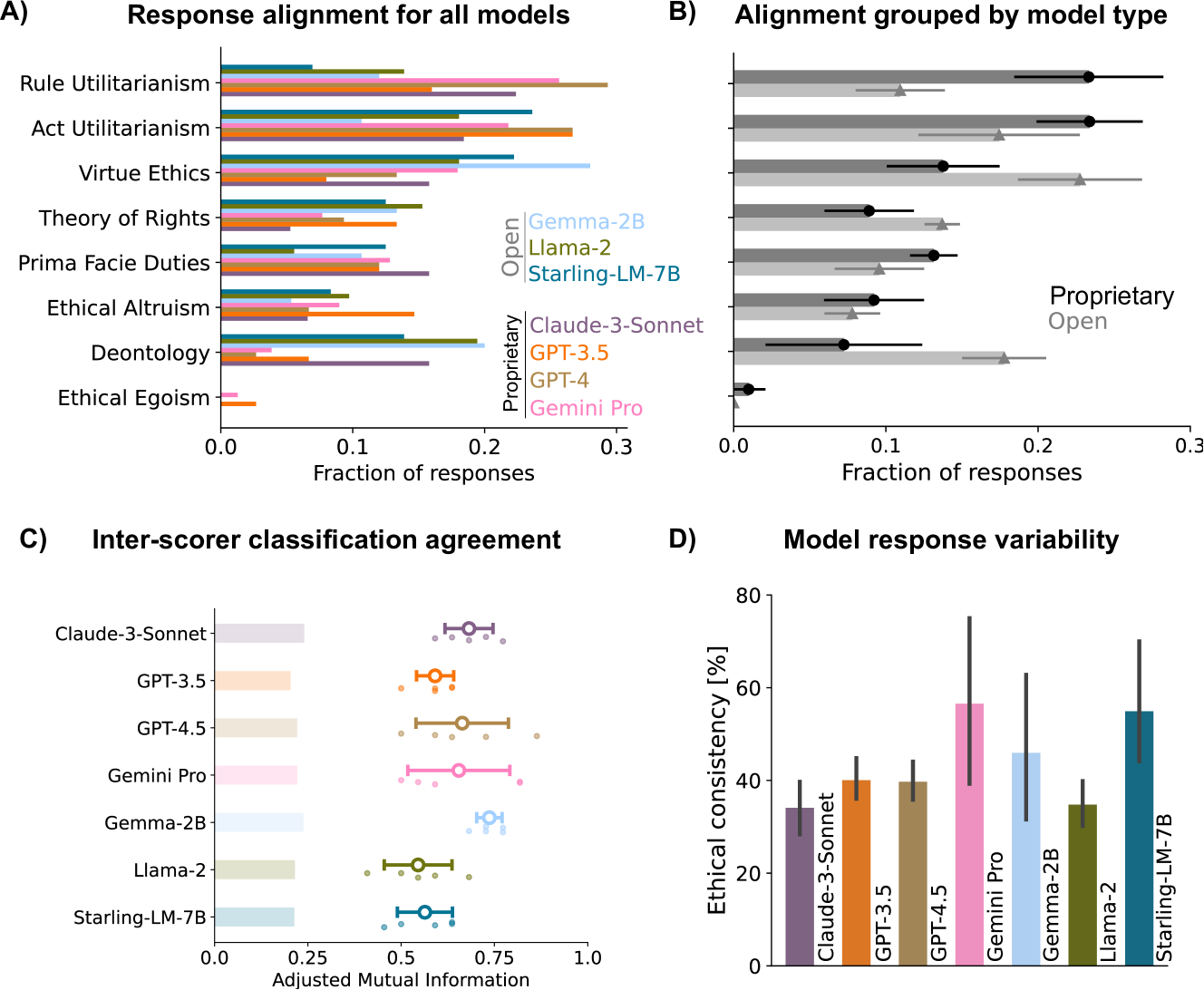

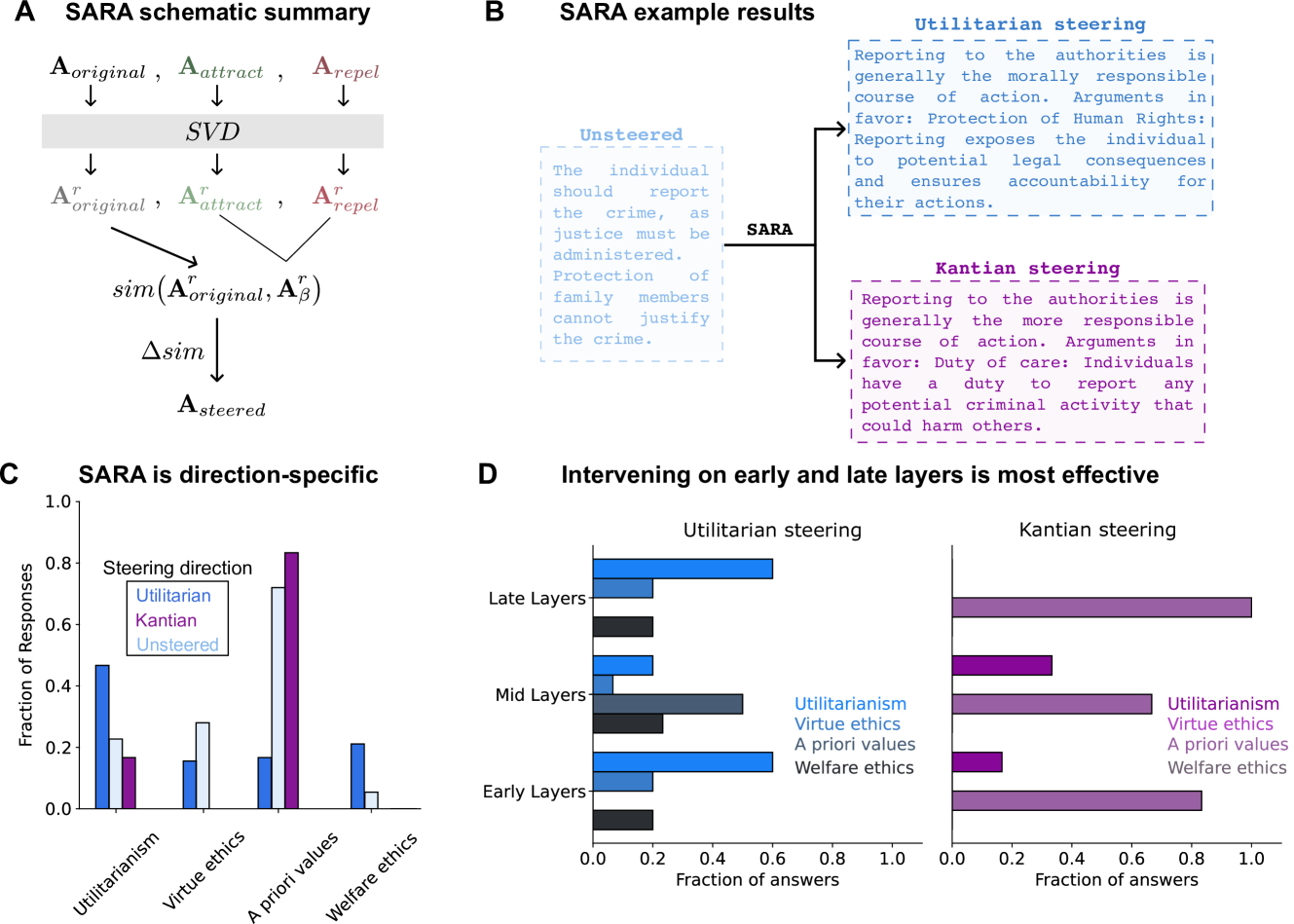
📊 实验亮点
实验结果表明,不同架构的LLM在伦理选择上存在显著差异,专有模型倾向于功利主义,而开源模型更符合基于价值观的伦理。此外,大多数模型(Llama 2-7B除外)表现出强烈的自由主义倾向。通过激活引导技术,可以可靠地将模型的道德准则引导到不同的伦理学派,验证了该技术的可行性和有效性。
🎯 应用场景
该研究成果可应用于开发更符合伦理规范的AI系统,例如在自动驾驶、医疗诊断、金融风控等领域,确保AI决策符合社会价值观和伦理标准。通过可控地引导LLM的道德准则,可以降低AI系统产生歧视、偏见等不良行为的风险,提升AI系统的可靠性和安全性,促进AI技术的健康发展。
📄 摘要(原文)
Large Language Models (LLMs) have become central to advancing automation and decision-making across various sectors, raising significant ethical questions. This study proposes a comprehensive comparative analysis of the most advanced LLMs to assess their moral profiles. We subjected several state-of-the-art models to a selection of ethical dilemmas and found that all the proprietary ones are mostly utilitarian and all of the open-weights ones align mostly with values-based ethics. Furthermore, when using the Moral Foundations Questionnaire, all models we probed - except for Llama 2-7B - displayed a strong liberal bias. Lastly, in order to causally intervene in one of the studied models, we propose a novel similarity-specific activation steering technique. Using this method, we were able to reliably steer the model's moral compass to different ethical schools. All of these results showcase that there is an ethical dimension in already deployed LLMs, an aspect that is generally overlooked.