Biological Neurons Compete with Deep Reinforcement Learning in Sample Efficiency in a Simulated Gameworld
作者: Moein Khajehnejad, Forough Habibollahi, Aswin Paul, Adeel Razi, Brett J. Kagan
分类: q-bio.NC, cs.AI
发布日期: 2024-05-27
备注: 13 Pages, 6 Figures - 38 Supplementary Pages, 6 Supplementary Figures, 4 Supplementary Tables
💡 一句话要点
体外生物神经元在Pong游戏中样本效率优于深度强化学习算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生物神经元网络 深度强化学习 样本效率 DishBrain 体外神经元 Pong游戏 人工智能 神经科学
📋 核心要点
- 深度强化学习算法在样本效率方面存在不足,限制了其在资源受限环境中的应用。
- 利用体外培养的生物神经元网络DishBrain,探索其在强化学习任务中的样本效率优势。
- 实验结果表明,生物神经元在Pong游戏中表现出比DQN、A2C和PPO等算法更高的样本效率。
📝 摘要(中文)
本研究对比了体外生物神经网络和最先进的深度强化学习(RL)算法在完成任务时所需的样本数量。通过DishBrain系统,该系统利用高密度多电极阵列将体外神经网络与计算机计算相结合,我们比较了这些生物系统的学习速率和性能,以及三种最先进的深度RL算法(即DQN、A2C和PPO)在同一游戏环境中的学习情况。这使得生物神经系统和深度RL之间能够进行有意义的比较。研究发现,当样本限制在真实世界的时间范围内时,即使是非常简单的生物培养物在各种游戏性能特征方面也优于深度RL算法,这意味着更高的样本效率。最终,即使在测试多种类型的信息输入以评估更高维度数据输入的影响时,生物神经元也表现出比所有深度强化学习智能体更快的学习速度。
🔬 方法详解
问题定义:论文旨在解决深度强化学习算法在样本效率方面的不足。现有深度强化学习算法在训练过程中需要大量的样本数据,这在实际应用中,尤其是在资源受限或数据获取成本高的场景下,是一个显著的痛点。生物神经元在学习过程中展现出更高的效率,因此研究希望探索生物神经元在强化学习任务中的潜力。
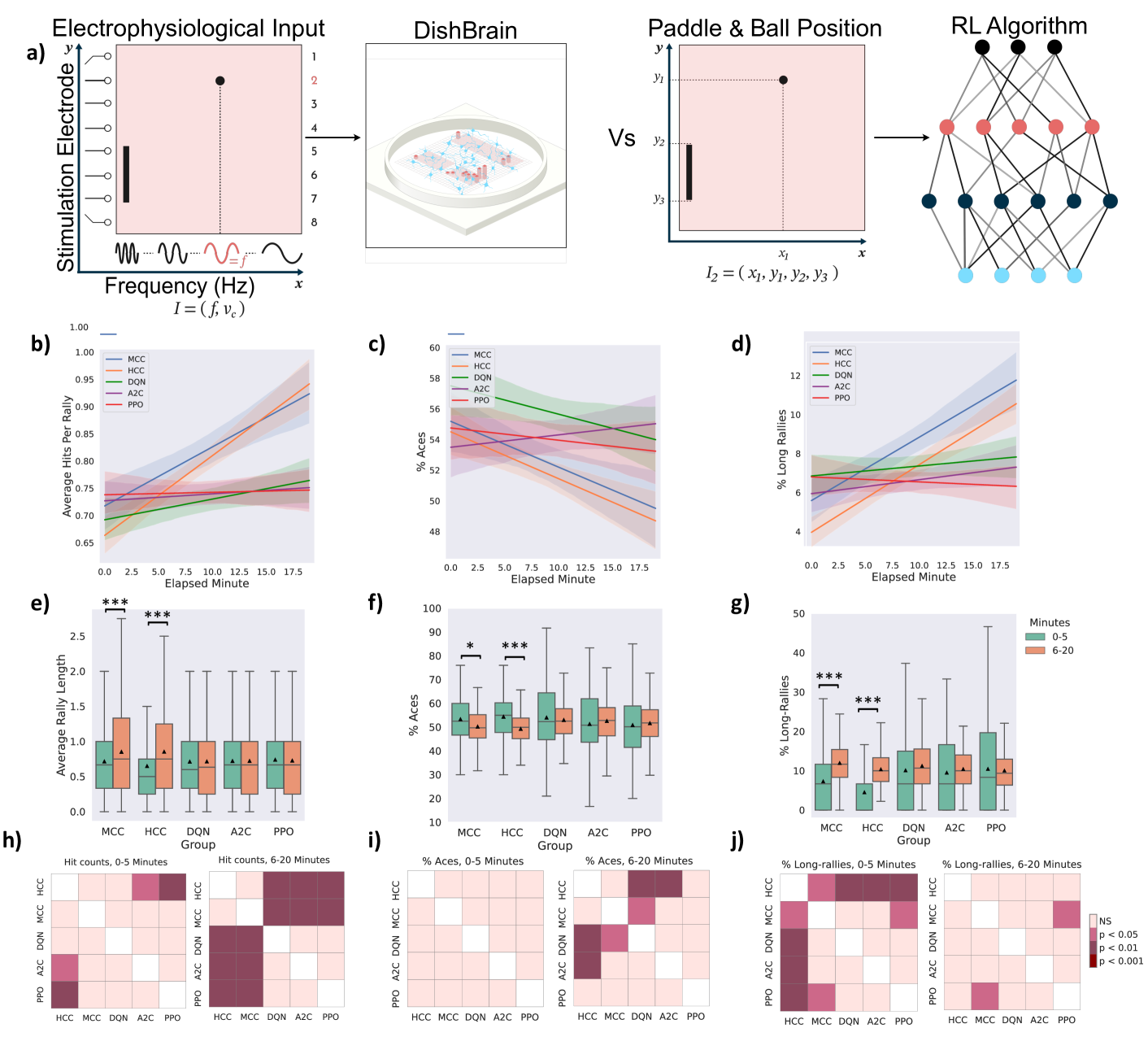
核心思路:论文的核心思路是将体外培养的生物神经元网络(DishBrain)作为智能体,通过电刺激和反馈机制,使其在Pong游戏中学习控制游戏行为。通过比较DishBrain与深度强化学习算法在相同环境下的学习效率,评估生物神经元在样本效率方面的优势。这种思路旨在探索生物智能在解决复杂问题方面的潜力,并为开发更高效的智能算法提供新的思路。
技术框架:整体框架包括以下几个主要部分:1) 体外神经元培养:使用DishBrain系统培养生物神经元网络。2) 环境模拟:构建Pong游戏的模拟环境。3) 交互机制:通过多电极阵列向神经元网络发送刺激信号,并接收神经元网络的响应信号。4) 奖励机制:根据神经元网络控制的游戏行为给予奖励或惩罚。5) 算法对比:将DishBrain的学习性能与DQN、A2C和PPO等深度强化学习算法进行对比。
关键创新:论文的关键创新在于将体外生物神经元网络应用于强化学习任务,并证明其在样本效率方面优于传统的深度强化学习算法。与现有方法相比,该研究探索了一种全新的智能体形式,并揭示了生物智能在解决复杂问题方面的潜力。这种方法为开发更高效、更具适应性的智能算法提供了新的思路。
关键设计:DishBrain系统使用高密度多电极阵列与体外培养的神经元网络进行交互。通过电刺激向神经元网络输入信息,并接收神经元网络的电生理响应。奖励机制的设计基于Pong游戏的得分规则,当神经元网络控制的游戏行为获得更高的分数时,给予更高的奖励。实验中,对不同类型的输入信息进行了测试,以评估生物神经元对高维数据的处理能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Pong游戏中,DishBrain在样本效率方面优于DQN、A2C和PPO等深度强化学习算法。即使在限制样本数量的情况下,DishBrain也能更快地学会控制游戏行为,并取得更好的游戏性能。此外,DishBrain在处理高维数据输入时也表现出更快的学习速度,表明其具有更强的适应性和泛化能力。
🎯 应用场景
该研究成果可应用于开发更高效、更具适应性的智能算法,尤其是在数据受限或计算资源有限的场景下。例如,可用于机器人控制、医疗诊断、金融预测等领域。此外,该研究也为理解生物智能的运作机制提供了新的视角,有助于推动人工智能和神经科学的交叉研究。
📄 摘要(原文)
How do biological systems and machine learning algorithms compare in the number of samples required to show significant improvements in completing a task? We compared the learning efficiency of in vitro biological neural networks to the state-of-the-art deep reinforcement learning (RL) algorithms in a simplified simulation of the game `Pong'. Using DishBrain, a system that embodies in vitro neural networks with in silico computation using a high-density multi-electrode array, we contrasted the learning rate and the performance of these biological systems against time-matched learning from three state-of-the-art deep RL algorithms (i.e., DQN, A2C, and PPO) in the same game environment. This allowed a meaningful comparison between biological neural systems and deep RL. We find that when samples are limited to a real-world time course, even these very simple biological cultures outperformed deep RL algorithms across various game performance characteristics, implying a higher sample efficiency. Ultimately, even when tested across multiple types of information input to assess the impact of higher dimensional data input, biological neurons showcased faster learning than all deep reinforcement learning agents.