Multiple Heads are Better than One: Mixture of Modality Knowledge Experts for Entity Representation Learning
作者: Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Binbin Hu, Ziqi Liu, Wen Zhang, Huajun Chen
分类: cs.AI, cs.CL
发布日期: 2024-05-27 (更新: 2025-04-06)
备注: ICLR 2025 Camera-ready Version. Fix a caption typo in the current version
💡 一句话要点
提出MoMoK框架,利用模态知识专家混合建模实体表示,提升多模态知识图谱补全效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态知识图谱 实体表示学习 知识图谱补全 模态融合 关系感知 专家混合模型 互信息最小化
📋 核心要点
- 现有MMKG表示学习方法侧重于实体级多模态融合,忽略了关系上下文中模态内部的多视角特征。
- MoMoK框架通过关系引导的模态知识专家,学习关系感知的模态嵌入,并进行联合决策。
- 实验结果表明,MoMoK在多个MMKG基准数据集上取得了显著的性能提升,验证了其有效性。
📝 摘要(中文)
高质量的多模态实体表示学习是多模态知识图谱(MMKG)表示学习的重要目标,它可以增强MMKG中的推理任务,例如MMKG补全(MMKGC)。主要的挑战在于协同建模海量三元组中蕴含的结构信息和实体的多模态特征。现有方法侧重于设计精巧的实体级多模态融合策略,但忽略了在不同关系上下文中模态内部蕴含的多视角特征的利用。为了解决这个问题,我们引入了一个新的框架,即模态知识专家混合(MoMoK),以学习自适应的多模态实体表示,从而更好地进行MMKGC。我们设计了关系引导的模态知识专家来获取关系感知的模态嵌入,并整合来自多模态的预测以实现联合决策。此外,我们通过最小化专家之间的互信息来解耦专家。在四个公共MMKG基准上的实验表明,MoMoK在复杂场景下表现出色。
🔬 方法详解
问题定义:论文旨在解决多模态知识图谱补全任务中,现有方法无法充分利用模态内部在不同关系上下文中的多视角特征的问题。现有方法主要集中在设计实体级别的多模态融合策略,忽略了模态本身所蕴含的丰富信息,以及这些信息在不同关系下的差异性表达。
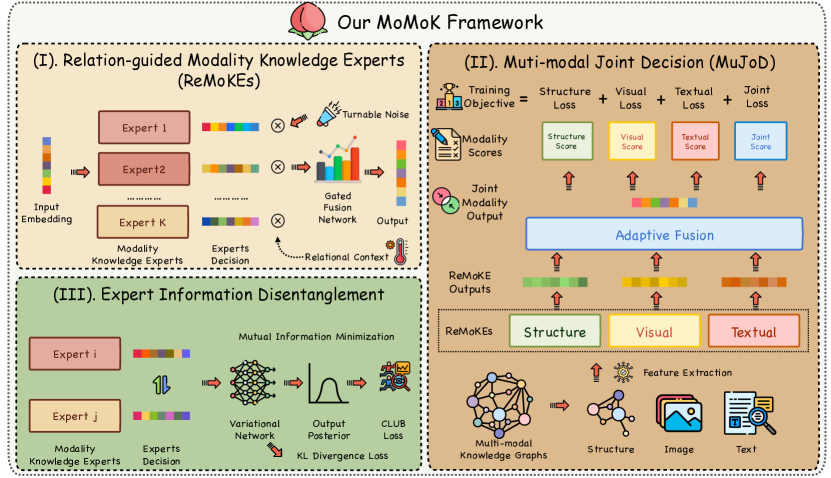
核心思路:论文的核心思路是利用“模态知识专家混合” (Mixture of Modality Knowledge Experts, MoMoK) 框架,为每个模态学习多个专家,每个专家关注不同关系上下文下的模态特征。通过这种方式,模型可以学习到关系感知的模态嵌入,从而更好地捕捉实体在不同关系下的语义信息。
技术框架:MoMoK框架主要包含以下几个模块:1) 关系引导的模态知识专家:为每个模态训练多个专家,每个专家负责学习特定关系上下文下的模态嵌入。2) 专家预测整合:将来自不同模态专家的预测结果进行整合,以实现联合决策。3) 专家解耦:通过最小化专家之间的互信息,鼓励专家学习到不同的特征表示,从而提高模型的泛化能力。整体流程是,给定一个三元组,首先利用关系引导的模态知识专家提取关系感知的模态嵌入,然后将这些嵌入输入到预测模块中进行三元组真假性预测,最后通过最小化损失函数来优化模型参数。
关键创新:论文的关键创新在于提出了关系引导的模态知识专家,这使得模型能够学习到关系感知的模态嵌入,从而更好地捕捉实体在不同关系下的语义信息。与现有方法相比,MoMoK框架更加关注模态内部的信息,以及这些信息在不同关系下的差异性表达。此外,通过解耦专家,可以提高模型的泛化能力。
关键设计:在关系引导的模态知识专家模块中,可以使用不同的神经网络结构来实现专家,例如多层感知机(MLP)或卷积神经网络(CNN)。损失函数通常包括三元组分类损失和专家解耦损失。三元组分类损失用于训练模型预测三元组真假性的能力,专家解耦损失用于鼓励专家学习到不同的特征表示。专家解耦损失可以通过最小化专家之间的互信息来实现,例如使用互信息神经网络估计器(MINE)。
🖼️ 关键图片

📊 实验亮点
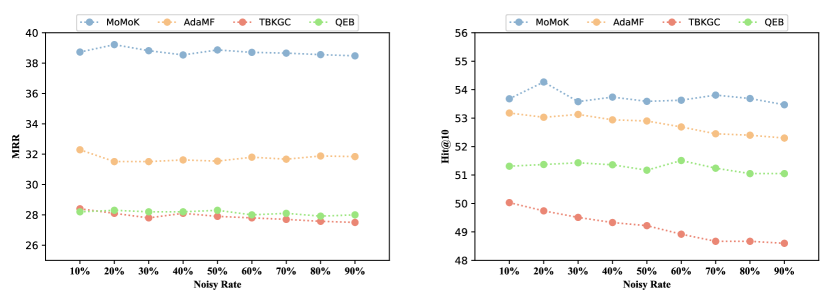
MoMoK在四个公开的MMKG基准数据集上进行了实验,结果表明MoMoK在所有数据集上都取得了最佳性能。例如,在一项实验中,MoMoK的Hits@1指标比最强的基线模型提高了超过5%。实验结果充分证明了MoMoK框架的有效性,以及关系引导的模态知识专家在多模态知识图谱补全任务中的优势。
🎯 应用场景
该研究成果可应用于多模态知识图谱补全、实体链接、关系抽取等任务。通过学习高质量的多模态实体表示,可以提升知识图谱的推理能力和信息检索效果,在智能问答、推荐系统等领域具有广泛的应用前景。未来可以进一步探索如何将MoMoK框架应用于更大规模、更复杂的知识图谱中。
📄 摘要(原文)
Learning high-quality multi-modal entity representations is an important goal of multi-modal knowledge graph (MMKG) representation learning, which can enhance reasoning tasks within the MMKGs, such as MMKG completion (MMKGC). The main challenge is to collaboratively model the structural information concealed in massive triples and the multi-modal features of the entities. Existing methods focus on crafting elegant entity-wise multi-modal fusion strategies, yet they overlook the utilization of multi-perspective features concealed within the modalities under diverse relational contexts. To address this issue, we introduce a novel framework with Mixture of Modality Knowledge experts (MoMoK for short) to learn adaptive multi-modal entity representations for better MMKGC. We design relation-guided modality knowledge experts to acquire relation-aware modality embeddings and integrate the predictions from multi-modalities to achieve joint decisions. Additionally, we disentangle the experts by minimizing their mutual information. Experiments on four public MMKG benchmarks demonstrate the outstanding performance of MoMoK under complex scenarios.