C3LLM: Conditional Multimodal Content Generation Using Large Language Models
作者: Zixuan Wang, Qinkai Duan, Yu-Wing Tai, Chi-Keung Tang
分类: cs.AI, cs.CL, cs.LG, cs.SD, eess.AS
发布日期: 2024-05-25
💡 一句话要点
C3LLM:提出一种基于大语言模型的条件多模态内容生成框架,统一视频-音频、音频-文本和文本-音频任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态生成 大语言模型 音频生成 视频理解 文本生成 离散表示 条件生成
📋 核心要点
- 现有方法在多模态内容生成中,难以有效对齐不同模态信息,且任务之间通常相互独立。
- C3LLM利用LLM作为桥梁,对齐视频、音频和文本模态,并以离散token的方式进行多模态生成。
- 实验结果表明,C3LLM在多模态生成任务上取得了改进,实现了更好的语义对齐。
📝 摘要(中文)
本文介绍了一种名为C3LLM(Conditioned-on-Three-Modalities Large Language Models,即基于三种模态条件的大语言模型)的新框架,该框架将视频到音频、音频到文本和文本到音频三个任务结合在一起。C3LLM采用大语言模型(LLM)结构作为桥梁,用于对齐不同的模态,综合给定的条件信息,并以离散的方式进行多模态生成。我们的贡献如下:首先,我们为音频生成任务采用了一种具有预训练音频码本的分层结构。具体来说,我们训练LLM从给定的条件生成音频语义token,并进一步使用非自回归transformer分层生成不同级别的声学token,以更好地提高生成音频的保真度。其次,基于LLM最初是为具有下一个单词预测方法的离散任务而设计的直觉,我们使用离散表示进行音频生成,并将它们的语义含义压缩成声学token,类似于向LLM添加“声学词汇”。第三,我们的方法将之前的音频理解、视频到音频生成和文本到音频生成任务组合成一个统一的模型,以端到端的方式提供更多的通用性。我们的C3LLM通过各种自动评估指标实现了改进的结果,与以前的方法相比提供了更好的语义对齐。
🔬 方法详解
问题定义:论文旨在解决多模态内容生成中,视频、音频和文本三种模态之间的对齐和统一生成问题。现有方法通常针对特定模态组合进行设计,缺乏通用性,且难以有效利用不同模态之间的关联信息。此外,现有音频生成方法在保真度方面仍有提升空间。
核心思路:论文的核心思路是利用大语言模型(LLM)强大的语义理解和生成能力,将其作为不同模态之间的桥梁。通过将不同模态的信息编码为离散的token序列,并训练LLM预测这些token序列,实现多模态信息的对齐和统一生成。这种方法借鉴了LLM在自然语言处理领域的成功经验,将“声学词汇”的概念引入音频生成。
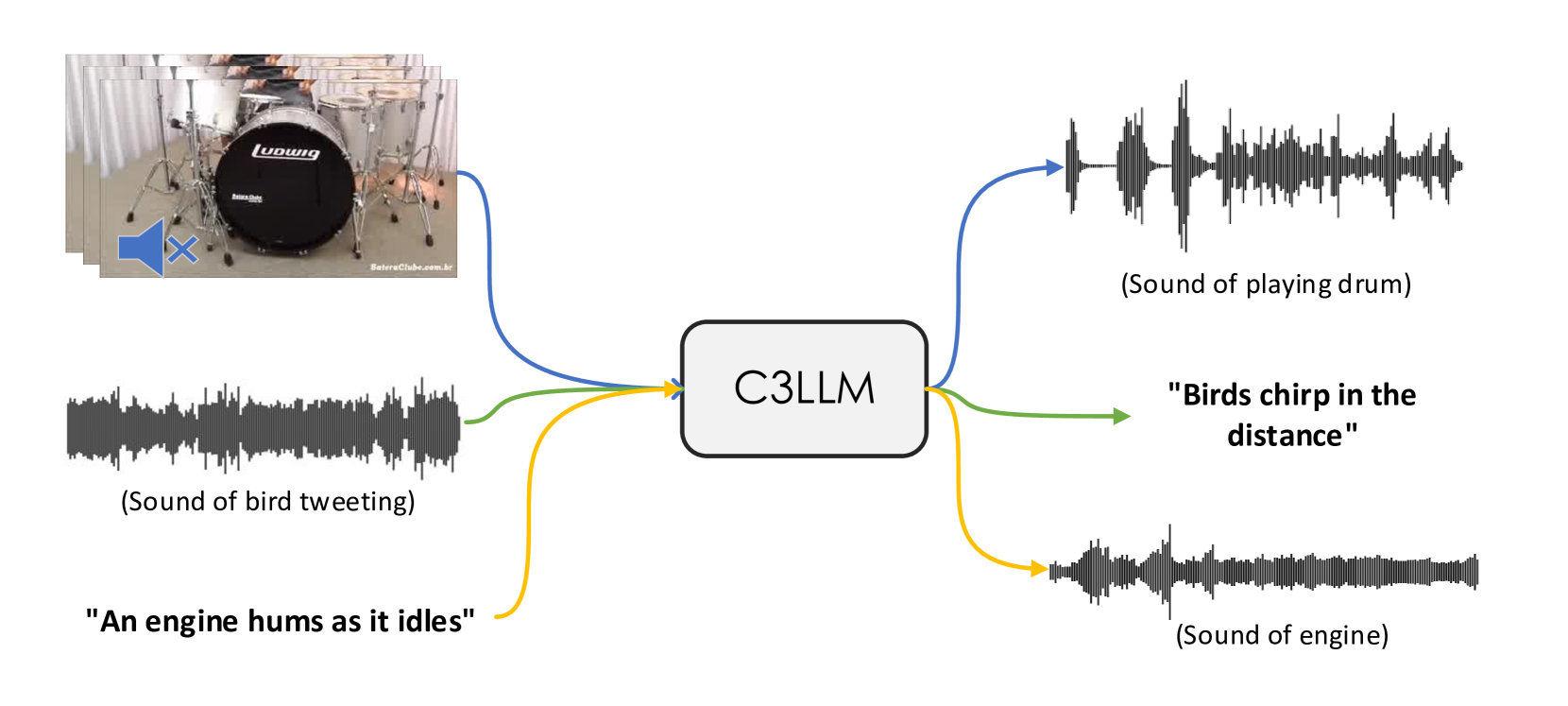
技术框架:C3LLM的整体框架包含以下几个主要模块:1) 模态编码器:将视频、音频和文本信息分别编码为特征向量。2) Token化器:将音频特征向量量化为离散的声学token序列。3) LLM:以编码后的特征向量和声学token序列作为输入,预测下一个声学token。4) 声码器:将生成的声学token序列解码为音频信号。该框架支持视频到音频、音频到文本和文本到音频三种任务,通过共享LLM参数实现知识迁移。
关键创新:论文的关键创新在于:1) 提出了一种基于LLM的通用多模态内容生成框架,能够统一处理视频、音频和文本三种模态。2) 采用离散的声学token表示音频信息,并将其与LLM的token预测机制相结合,提高了音频生成的保真度。3) 引入分层音频生成结构,利用非自回归transformer生成不同级别的声学token,进一步提升音频质量。
关键设计:在音频生成方面,论文采用了两阶段策略:首先,LLM生成高级语义token,然后使用非自回归transformer根据语义token生成低级声学token。这种分层结构能够更好地控制音频的语义信息和声学细节。此外,论文还使用了预训练的音频码本,将音频特征向量量化为离散的token序列,从而降低了LLM的学习难度。
🖼️ 关键图片


📊 实验亮点
C3LLM在多个多模态生成任务上取得了显著的改进。通过自动评估指标,例如在语义对齐方面,C3LLM优于之前的模型。具体性能数据和对比基线在论文中有详细展示,证明了C3LLM在多模态内容生成方面的有效性。
🎯 应用场景
C3LLM具有广泛的应用前景,包括:1) 智能视频编辑:根据视频内容自动生成配乐或音效。2) 语音助手:根据文本指令生成语音回复或音频内容。3) 多媒体内容创作:为视频、游戏等生成各种类型的音频素材。该研究有助于提升多模态内容生成的质量和效率,并为未来的多模态人工智能应用奠定基础。
📄 摘要(原文)
We introduce C3LLM (Conditioned-on-Three-Modalities Large Language Models), a novel framework combining three tasks of video-to-audio, audio-to-text, and text-to-audio together. C3LLM adapts the Large Language Model (LLM) structure as a bridge for aligning different modalities, synthesizing the given conditional information, and making multimodal generation in a discrete manner. Our contributions are as follows. First, we adapt a hierarchical structure for audio generation tasks with pre-trained audio codebooks. Specifically, we train the LLM to generate audio semantic tokens from the given conditions, and further use a non-autoregressive transformer to generate different levels of acoustic tokens in layers to better enhance the fidelity of the generated audio. Second, based on the intuition that LLMs were originally designed for discrete tasks with the next-word prediction method, we use the discrete representation for audio generation and compress their semantic meanings into acoustic tokens, similar to adding "acoustic vocabulary" to LLM. Third, our method combines the previous tasks of audio understanding, video-to-audio generation, and text-to-audio generation together into one unified model, providing more versatility in an end-to-end fashion. Our C3LLM achieves improved results through various automated evaluation metrics, providing better semantic alignment compared to previous methods.