Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
作者: Runsong Jia, Bowen Zhang, Sergio J. Rodríguez Méndez, Pouya G. Omran
分类: cs.IR, cs.AI, cs.CL
发布日期: 2024-05-24
备注: for the associated repository, see http://w3id.org/kgcp/KGQP
💡 一句话要点
提出结合LLM与知识图谱的语义查询处理系统,提升学术知识获取效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大型语言模型 语义查询处理 深度文档模型 学术知识管理
📋 核心要点
- 传统学术知识图谱构建方法难以捕捉细粒度信息,限制了知识的有效利用。
- 提出结合深度文档模型(DDM)和知识图谱增强的查询处理(KGQP)框架,提升查询准确性和效率。
- 实验结果表明,该框架在准确性检索和查询效率方面优于现有基线方法,具有实际应用潜力。
📝 摘要(中文)
本研究旨在开发一种创新的语义查询处理系统,使用户能够获取澳大利亚国立大学(ANU)计算机科学(CS)研究人员产生的研究工作的全面信息。该系统将大型语言模型(LLM)与ANU学术知识图谱(ASKG)集成,ASKG是ANU在CS领域产生的所有研究相关成果的结构化存储库。每个成果及其组成部分都表示为存储在知识图谱(KG)中的文本节点。为了解决传统学术KG构建和利用方法的局限性,我们提出了一个新颖的框架,该框架集成了深度文档模型(DDM)以进行全面的文档表示,以及KG增强的查询处理(KGQP)以优化复杂的查询处理。DDM能够对学术论文中的层次结构和语义关系进行细粒度的表示,而KGQP利用KG结构来提高LLM的查询准确性和效率。通过将ASKG与LLM相结合,我们的方法增强了知识利用和自然语言理解能力。该系统采用自动LLM-SPARQL融合来检索ASKG中的相关事实和文本节点。初步实验表明,我们的框架在准确性检索和查询效率方面优于基线方法。我们展示了该框架在学术研究场景中的实际应用,突出了其在革新学术知识管理和发现方面的潜力。这项工作使研究人员能够更有效地获取和利用文档中的知识,并为开发与LLM的精确和可靠的交互奠定了基础。
🔬 方法详解
问题定义:现有学术知识图谱构建方法无法捕捉细粒度的文档信息,导致查询结果不够精确和全面。传统方法难以有效利用文档的层次结构和语义关系,使得研究人员难以高效地获取所需知识。
核心思路:核心思路是将大型语言模型(LLM)与学术知识图谱(ASKG)相结合,利用LLM的自然语言理解能力和知识图谱的结构化信息,实现更精确和高效的语义查询处理。通过深度文档模型(DDM)提取文档的细粒度特征,并利用知识图谱增强查询处理(KGQP)优化查询过程。
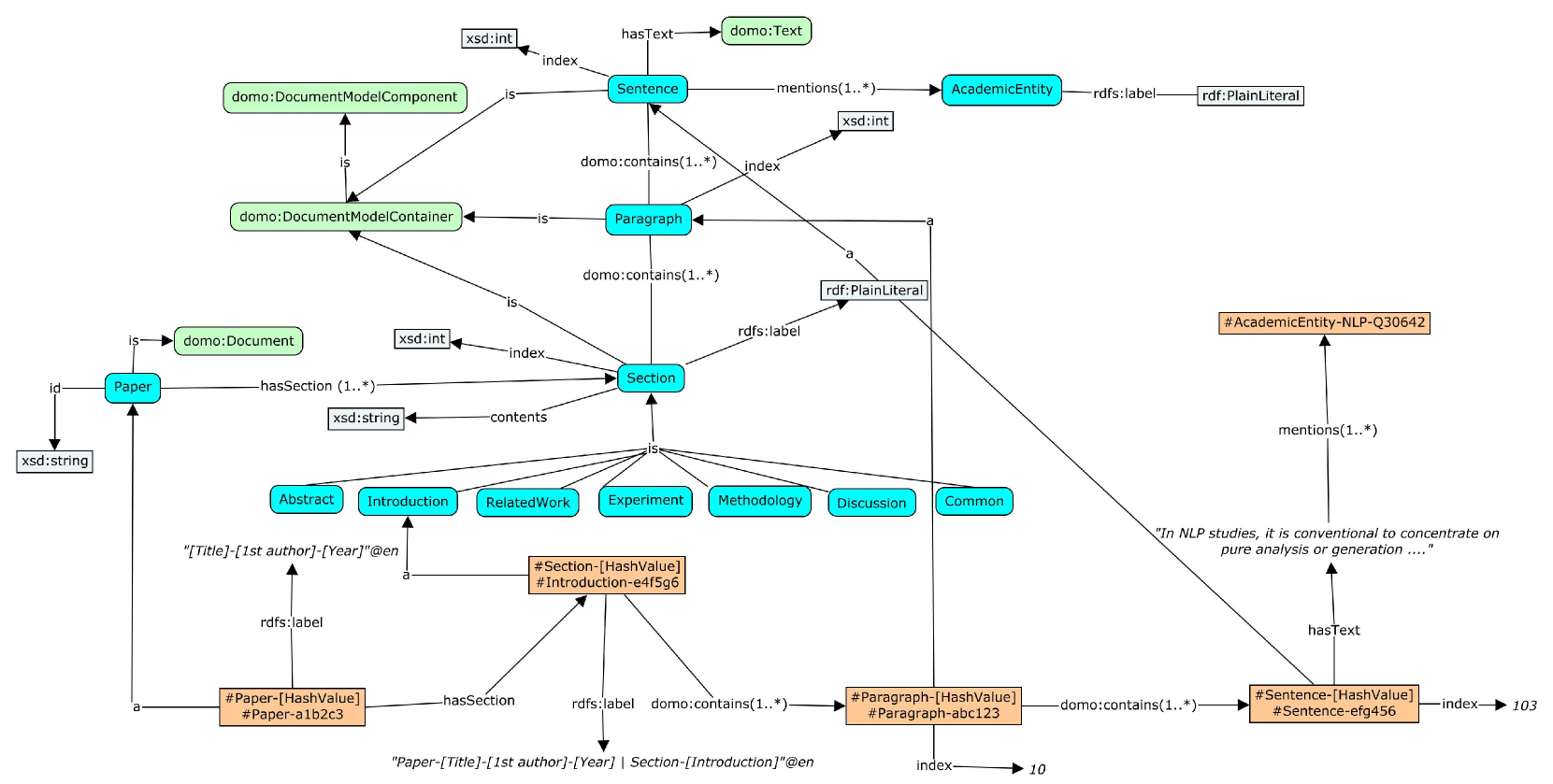
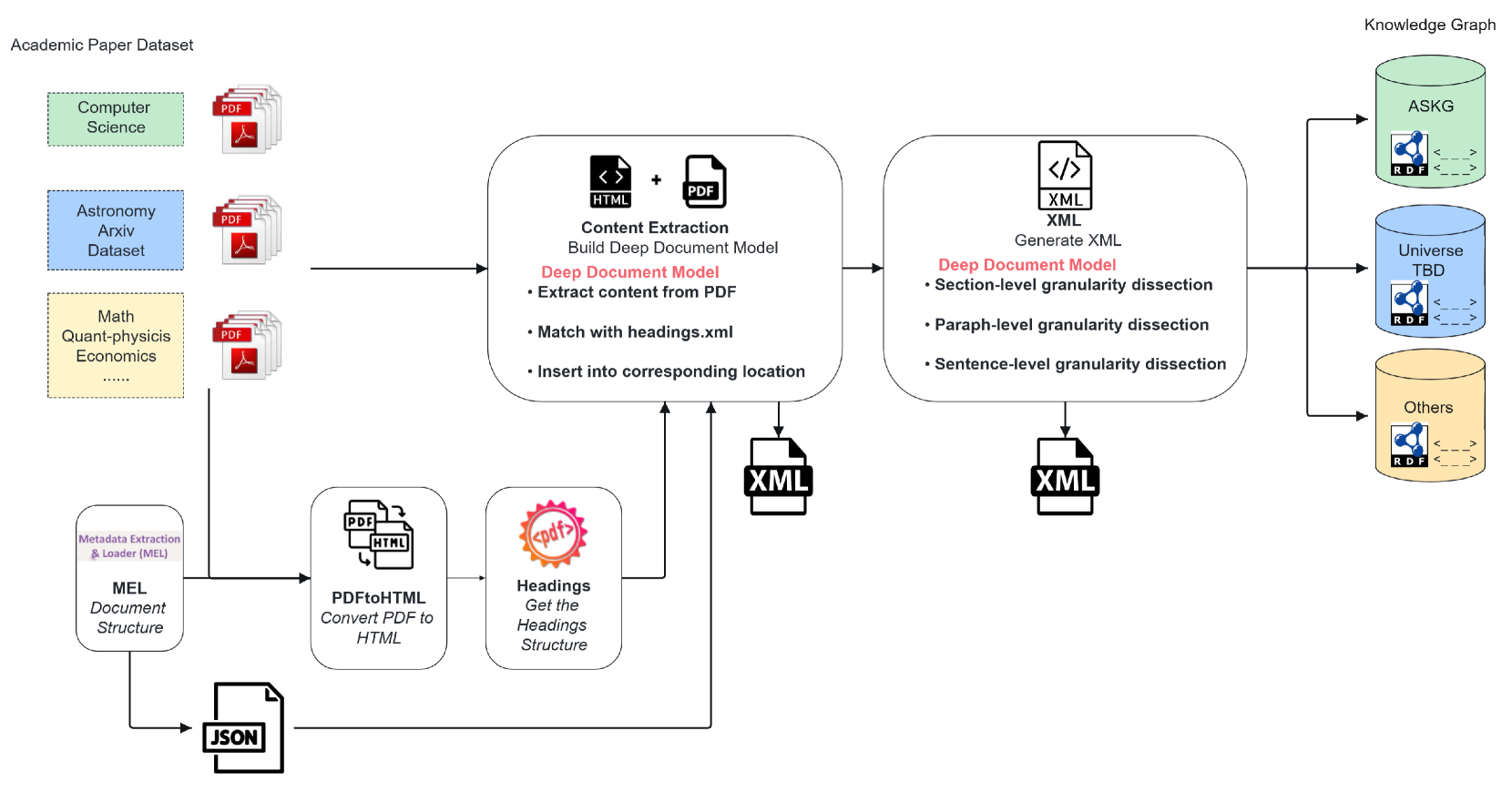
技术框架:该系统主要包含以下几个模块:1) ANU学术知识图谱(ASKG):存储澳大利亚国立大学计算机科学领域的研究成果。2) 深度文档模型(DDM):用于提取文档的层次结构和语义关系,生成细粒度的文档表示。3) KG增强的查询处理(KGQP):利用知识图谱的结构化信息优化查询过程,提高查询准确性和效率。4) LLM-SPARQL融合模块:自动将自然语言查询转换为SPARQL查询,并结合LLM进行语义理解和推理。
关键创新:关键创新在于将深度文档模型(DDM)与知识图谱增强的查询处理(KGQP)相结合,并利用LLM进行语义理解和推理。这种方法能够更有效地利用文档的细粒度信息和知识图谱的结构化信息,从而提高查询的准确性和效率。自动LLM-SPARQL融合也减少了人工干预,提高了系统的易用性。
关键设计:DDM的具体结构和训练方法未知,但推测可能使用了Transformer或其他深度学习模型来捕捉文档的语义信息。KGQP的具体实现方式未知,但推测可能使用了图神经网络或其他图算法来利用知识图谱的结构化信息。LLM-SPARQL融合模块的具体实现方式未知,但推测可能使用了基于规则或机器学习的方法将自然语言查询转换为SPARQL查询。
🖼️ 关键图片

📊 实验亮点
初步实验表明,该框架在准确性检索和查询效率方面优于基线方法。具体性能数据未知,但论文强调了该框架在学术研究场景中的实际应用潜力,表明其在提升知识获取效率方面具有显著优势。该系统能够更准确地检索相关信息,并提高查询效率,从而节省研究人员的时间和精力。
🎯 应用场景
该研究成果可应用于学术知识管理和发现领域,帮助研究人员更有效地获取和利用文档中的知识。该系统可以用于构建智能问答系统、推荐系统和知识发现系统,为学术研究提供更强大的支持。未来,该技术还可以扩展到其他领域,如法律、医疗等,实现更智能化的知识管理和利用。
📄 摘要(原文)
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.