Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
作者: Yang Zhang, Shixin Yang, Chenjia Bai, Fei Wu, Xiu Li, Zhen Wang, Xuelong Li
分类: cs.AI, cs.CL, cs.LG, cs.MA, cs.RO
发布日期: 2024-05-23 (更新: 2025-09-29)
备注: accepted by ACL'2025
💡 一句话要点
提出ReAd框架,高效引导LLM进行具身多智能体协作
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体协作 大型语言模型 具身智能 强化学习 优势函数
📋 核心要点
- 现有方法过度依赖物理验证或自我反思,导致LLM查询效率低下,难以有效进行多智能体协作。
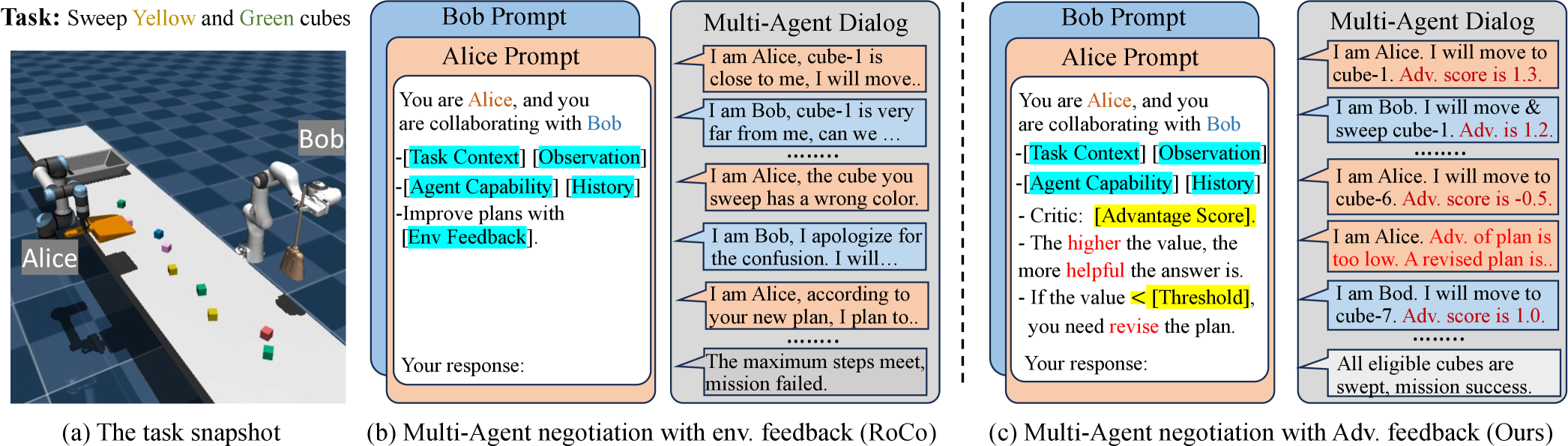
- 提出ReAd框架,通过强化优势反馈,使LLM具备前瞻性,判断动作对最终任务的贡献。
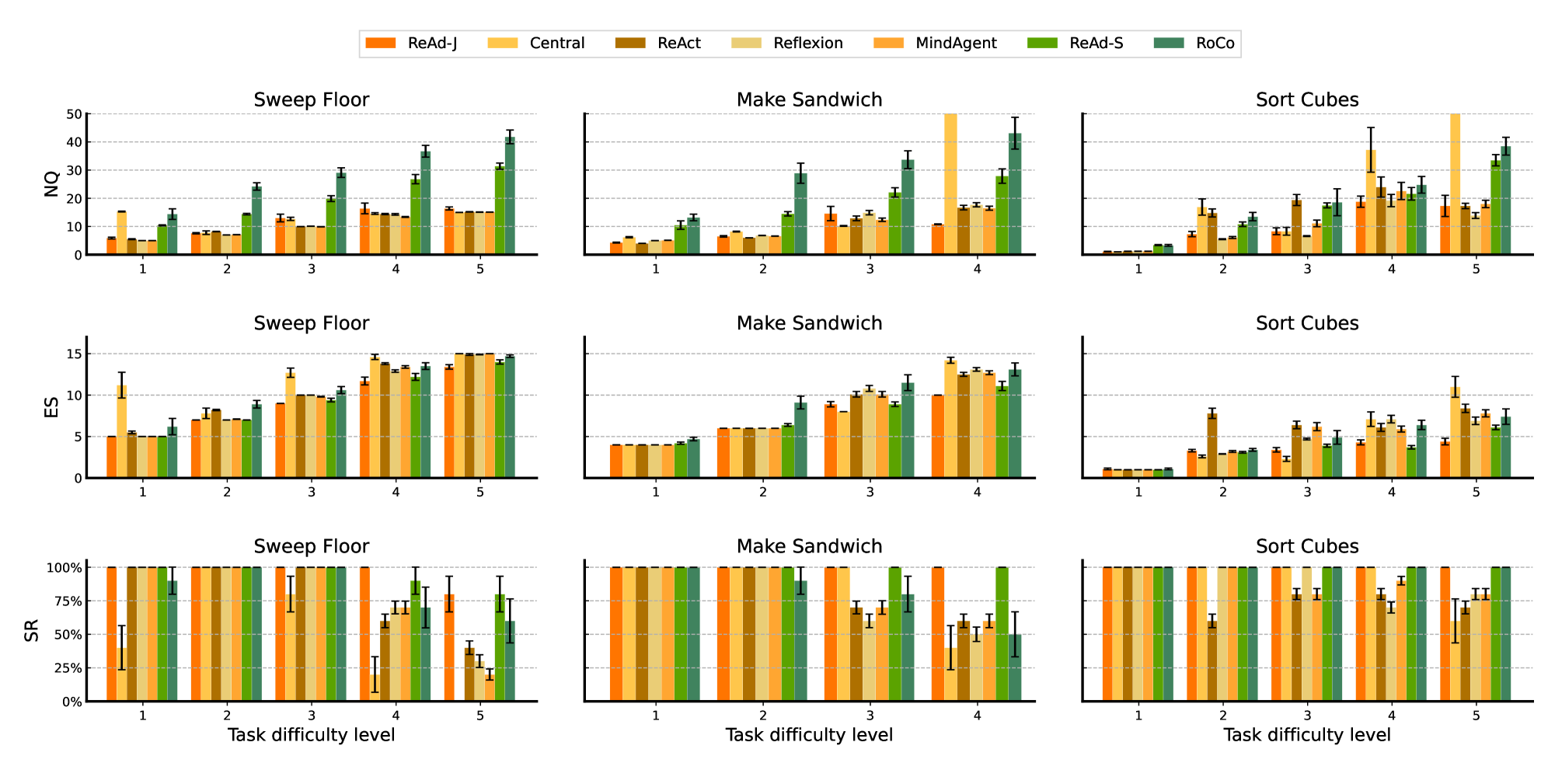
- 实验表明,ReAd在成功率上超越基线,并显著减少智能体交互步骤和LLM查询轮数。
📝 摘要(中文)
由于物理世界的复杂性,将大型语言模型(LLM)的推理能力应用于具身任务具有挑战性。特别是,多智能体协作的LLM规划需要智能体之间的通信或信用分配作为反馈,以重新调整提出的计划并实现有效的协调。然而,现有过度依赖物理验证或自我反思的方法会过度且低效地查询LLM。本文提出了一种用于多智能体协作的新框架,该框架引入了强化优势反馈(ReAd),用于高效地自我改进计划。具体来说,我们执行评论家回归,从LLM规划的数据中学习序列优势函数,然后将LLM规划器视为优化器,以生成最大化优势函数的动作。这使LLM具有洞察力,能够辨别该动作是否有助于完成最终任务。我们通过将强化学习中的优势加权回归扩展到多智能体系统来提供理论分析。在Overcooked-AI和一个困难的RoCoBench变体上的实验表明,ReAd在成功率方面超过了基线,并且还显着减少了智能体的交互步骤和LLM的查询轮数,证明了其在引导LLM方面的高效率。
🔬 方法详解
问题定义:论文旨在解决多智能体协作任务中,如何高效地利用大型语言模型(LLM)进行规划和决策的问题。现有方法,如过度依赖物理环境验证或自我反思,导致LLM查询次数过多,效率低下,难以适应复杂的多智能体协作场景。这些方法未能充分利用LLM的推理能力,且缺乏有效的反馈机制来指导LLM进行规划。
核心思路:论文的核心思路是引入强化学习中的优势函数(Advantage Function)的概念,通过学习一个评论家(Critic)来评估LLM生成的动作的优劣,并利用这个优势函数来引导LLM进行规划。具体来说,将LLM视为一个优化器,目标是生成能够最大化优势函数的动作。这样,LLM在规划时就能考虑到动作对最终任务的贡献,从而提高规划效率和成功率。
技术框架:ReAd框架主要包含以下几个模块:1) LLM规划器:负责生成初始的动作序列。2) 评论家回归:利用LLM规划的数据,学习一个序列优势函数,用于评估动作的优劣。3) 强化优势反馈:将优势函数作为反馈信号,引导LLM规划器生成更好的动作序列。整个流程可以看作是一个迭代优化的过程,LLM不断根据优势反馈调整其规划策略,最终实现高效的多智能体协作。
关键创新:论文的关键创新在于将强化学习中的优势函数引入到LLM的规划过程中,并将其扩展到多智能体系统。与现有方法相比,ReAd框架能够更有效地利用LLM的推理能力,减少LLM的查询次数,并提高规划的效率和成功率。此外,通过学习优势函数,ReAd框架能够为LLM提供更有效的反馈信号,从而更好地指导LLM进行规划。
关键设计:ReAd框架的关键设计包括:1) 优势函数的定义和学习方法:论文采用评论家回归的方法来学习优势函数,具体来说,使用LLM规划的数据训练一个神经网络,使其能够预测每个动作的优势值。2) LLM规划器的优化方法:论文将LLM视为一个优化器,通过最大化优势函数来生成动作序列。具体来说,可以使用梯度上升等优化算法来调整LLM的参数,使其生成的动作能够获得更高的优势值。3) 多智能体系统的扩展:论文将优势函数的概念扩展到多智能体系统,通过考虑每个智能体的贡献来学习优势函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ReAd框架在Overcooked-AI和RoCoBench两个基准测试中均取得了显著的性能提升。在Overcooked-AI中,ReAd的成功率超过了现有基线方法,并且显著减少了智能体的交互步骤和LLM的查询轮数。在RoCoBench的一个困难变体中,ReAd也表现出优异的性能,验证了其在复杂环境下的有效性。这些结果表明,ReAd框架能够高效地引导LLM进行多智能体协作,并显著提高系统的整体性能。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,如机器人协同操作、自动驾驶车队管理、智能交通调度等。通过高效引导LLM进行规划和决策,可以提高系统的整体效率和性能,降低运营成本,并为复杂任务的自动化提供新的解决方案。未来,该方法有望进一步扩展到更复杂的环境和任务中,实现更智能、更高效的多智能体协作。
📄 摘要(原文)
Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the complexity of the physical world. Especially, LLM planning for multi-agent collaboration requires communication of agents or credit assignment as the feedback to re-adjust the proposed plans and achieve effective coordination. However, existing methods that overly rely on physical verification or self-reflection suffer from excessive and inefficient querying of LLMs. In this paper, we propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans. Specifically, we perform critic regression to learn a sequential advantage function from LLM-planned data, and then treat the LLM planner as an optimizer to generate actions that maximize the advantage function. It endows the LLM with the foresight to discern whether the action contributes to accomplishing the final task. We provide theoretical analysis by extending advantage-weighted regression in reinforcement learning to multi-agent systems. Experiments on Overcooked-AI and a difficult variant of RoCoBench show that ReAd surpasses baselines in success rate, and also significantly decreases the interaction steps of agents and query rounds of LLMs, demonstrating its high efficiency for grounding LLMs. More results are given at https://embodied-read.github.io