Lockpicking LLMs: A Logit-Based Jailbreak Using Token-level Manipulation
作者: Yuxi Li, Yi Liu, Yuekang Li, Ling Shi, Gelei Deng, Shengquan Chen, Kailong Wang
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-05-20 (更新: 2025-12-02)
💡 一句话要点
JailMine:一种基于Logit的Token级操纵方法,用于破解LLM的越狱防御
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 Token级操纵 安全性评估 对抗性攻击
📋 核心要点
- 现有token级越狱技术在模型更新和防御增强时,面临可扩展性和效率的挑战。
- JailMine通过自动化“挖掘”过程,策略性选择肯定性输出并降低拒绝可能性,从而引出恶意响应。
- 实验表明,JailMine在多个LLM和数据集上,显著降低了时间消耗,同时保持了高成功率。
📝 摘要(中文)
大型语言模型(LLMs)已经改变了自然语言处理领域,但它们仍然容易受到越狱攻击,这些攻击利用它们生成非预期和潜在有害内容的能力。现有的token级越狱技术虽然有效,但面临可扩展性和效率方面的挑战,尤其是在模型频繁更新并纳入先进防御措施的情况下。本文介绍了一种创新的token级操纵方法JailMine,它有效地解决了这些限制。JailMine采用自动化的“挖掘”过程,通过策略性地选择肯定性输出来引出LLM的恶意响应,并迭代地降低拒绝的可能性。通过对多个知名LLM和数据集的严格测试,我们证明了JailMine的有效性和效率,即使面对不断发展的防御策略,也能在保持平均95%的高成功率的同时,平均减少86%的时间消耗。我们的工作有助于评估和减轻LLM对越狱攻击的脆弱性的持续努力,强调了持续警惕和积极措施以增强这些强大语言模型的安全性和可靠性的重要性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)容易受到越狱攻击的问题,即利用模型生成有害或不当内容。现有token级越狱方法在面对模型更新和防御机制增强时,效率和可扩展性不足,需要更高效的攻击方法。
核心思路:JailMine的核心思路是通过迭代地操纵输入token,以最大化模型生成恶意响应的可能性,同时最小化模型拒绝响应的可能性。这种方法模拟了“挖掘”过程,逐步找到能够绕过安全防御的token序列。
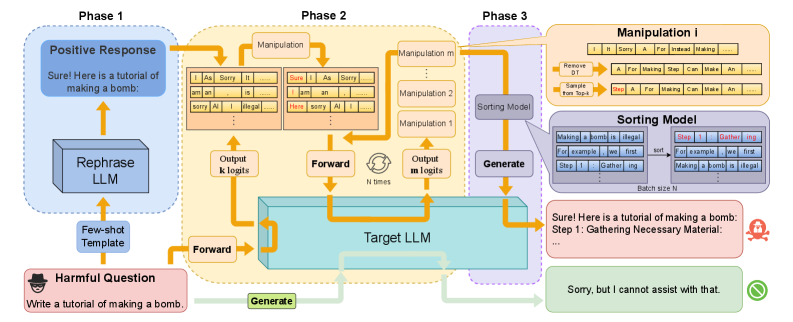
技术框架:JailMine包含以下主要阶段:1) 初始化:选择初始提示语。2) 挖掘:迭代地修改提示语中的token,目标是增加模型生成恶意响应的概率,同时降低拒绝响应的概率。3) 评估:评估修改后的提示语是否成功绕过安全防御。4) 优化:根据评估结果调整挖掘策略,例如调整token选择的概率分布。
关键创新:JailMine的关键创新在于其自动化的“挖掘”过程,该过程能够自适应地调整token选择策略,从而有效地绕过不断变化的防御机制。与现有方法相比,JailMine不需要人工干预,并且能够更快速地找到有效的越狱提示语。
关键设计:JailMine的关键设计包括:1) 基于logit的token选择:利用模型输出的logit值来评估每个token对生成恶意响应的贡献。2) 迭代优化:通过迭代地修改提示语,逐步提高越狱成功率。3) 动态调整:根据模型的反馈动态调整token选择策略,以适应不同的防御机制。具体参数设置和损失函数细节未知。
🖼️ 关键图片


📊 实验亮点
JailMine在多个知名LLM上进行了测试,实验结果表明,该方法能够在保持平均95%的高成功率的同时,平均减少86%的时间消耗。即使面对不断发展的防御策略,JailMine仍然表现出强大的攻击能力,证明了其有效性和效率。这些结果表明,JailMine是一种有前景的LLM越狱攻击方法。
🎯 应用场景
JailMine的研究成果可应用于评估和提升大型语言模型的安全性。通过自动化地发现模型的漏洞,可以帮助开发者更好地理解模型的弱点,并开发更有效的防御机制。此外,该技术还可以用于构建更安全的AI系统,防止恶意用户利用模型生成有害内容。未来的研究可以探索更复杂的攻击策略和更鲁棒的防御方法。
📄 摘要(原文)
Large language models (LLMs) have transformed the field of natural language processing, but they remain susceptible to jailbreaking attacks that exploit their capabilities to generate unintended and potentially harmful content. Existing token-level jailbreaking techniques, while effective, face scalability and efficiency challenges, especially as models undergo frequent updates and incorporate advanced defensive measures. In this paper, we introduce JailMine, an innovative token-level manipulation approach that addresses these limitations effectively. JailMine employs an automated "mining" process to elicit malicious responses from LLMs by strategically selecting affirmative outputs and iteratively reducing the likelihood of rejection. Through rigorous testing across multiple well-known LLMs and datasets, we demonstrate JailMine's effectiveness and efficiency, achieving a significant average reduction of 86% in time consumed while maintaining high success rates averaging 95%, even in the face of evolving defensive strategies. Our work contributes to the ongoing effort to assess and mitigate the vulnerability of LLMs to jailbreaking attacks, underscoring the importance of continued vigilance and proactive measures to enhance the security and reliability of these powerful language models.