OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
作者: Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Weikai Fang, Xianyu, Yu Cao, Haotian Xu, Yiming Liu
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-05-20 (更新: 2025-10-09)
备注: update template
🔗 代码/项目: GITHUB
💡 一句话要点
OpenRLHF:一个易用、可扩展、高性能的RLHF框架,加速LLM对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RLHF 大型语言模型 强化学习 人类反馈 模型对齐
📋 核心要点
- 现有RLHF框架面临推理瓶颈和复杂性壁垒等挑战,限制了其在研究和实践中的应用。
- OpenRLHF基于Ray等框架,简化设计、优化代码结构,降低了RLHF的学习和使用门槛。
- 实验表明,OpenRLHF在训练效率上优于现有框架,代码量更少,已被多个机构采用。
📝 摘要(中文)
本文提出了OpenRLHF,一个用户友好、可扩展且易于学习的开源RLHF框架,它构建于Ray、vLLM、DeepSpeed和HuggingFace Transformers之上。该框架具有简化的设计、清晰的代码结构和全面的文档,旨在降低研究人员和从业者进入RLHF领域的门槛。实验结果表明,与最先进的框架相比,OpenRLHF在不同模型规模上实现了更高的训练效率,速度提升范围为1.22倍至1.68倍。此外,OpenRLHF所需的实现代码行数也显著减少。OpenRLHF已在GitHub上公开发布,并已被领先机构采用,以加速RLHF的研究和学习。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)框架,在微调大型语言模型(LLM)时,存在推理瓶颈和复杂性障碍,使得研究人员和从业者难以有效利用RLHF技术来提升LLM的对齐效果,尤其是在需要大量推理和长上下文的CoT任务中。
核心思路:OpenRLHF的核心思路是构建一个易于使用、可扩展且高性能的RLHF框架,通过简化设计、清晰代码结构和完善文档,降低RLHF的学习和使用门槛,从而加速LLM的对齐过程。该框架旨在解决现有框架的复杂性和效率问题。
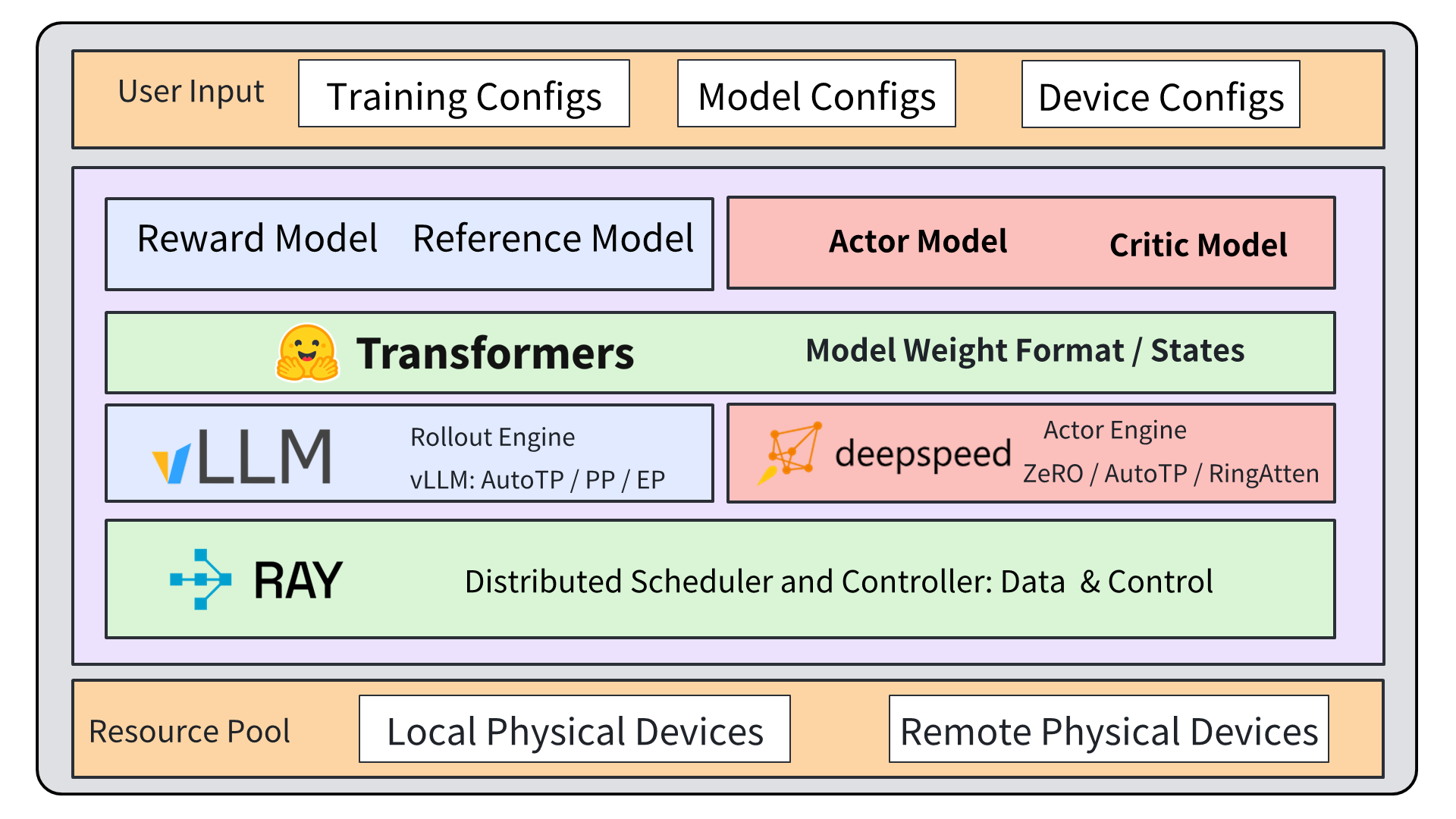
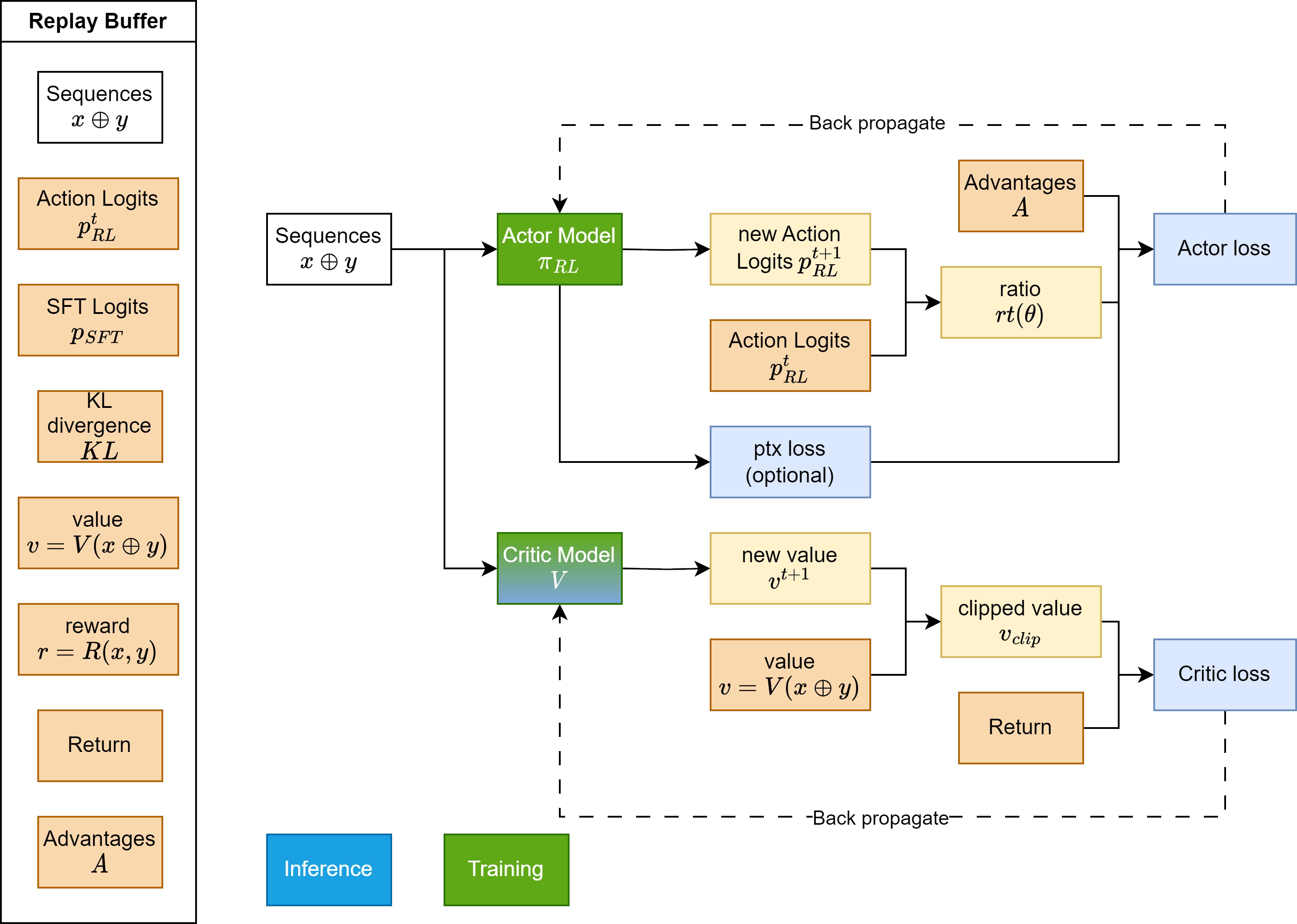
技术框架:OpenRLHF框架构建于Ray、vLLM、DeepSpeed和HuggingFace Transformers之上。Ray用于分布式计算,vLLM用于加速推理,DeepSpeed用于优化训练,HuggingFace Transformers提供预训练模型。整体流程包括奖励模型训练、策略模型训练和评估等阶段。
关键创新:OpenRLHF的关键创新在于其易用性和高性能。通过简化框架设计和提供清晰的代码结构,降低了RLHF的学习曲线。同时,利用vLLM等技术优化了推理效率,提高了训练速度。此外,OpenRLHF还提供了全面的文档,方便用户快速上手。
关键设计:OpenRLHF的关键设计包括:1) 简化的奖励模型训练流程,使用户能够轻松训练高质量的奖励模型;2) 高效的策略模型训练方法,利用vLLM加速推理,提高训练效率;3) 可扩展的架构,支持不同规模的模型和数据集;4) 详细的文档和示例,方便用户学习和使用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OpenRLHF在训练效率上优于现有框架,速度提升范围为1.22倍至1.68倍(具体模型大小未知,原文未明确给出)。此外,OpenRLHF所需的实现代码行数也显著减少,降低了开发成本。这些结果表明,OpenRLHF在易用性和性能方面都具有显著优势。
🎯 应用场景
OpenRLHF可广泛应用于各种需要人类对齐的大型语言模型微调任务,例如对话系统、文本生成、代码生成等。该框架能够帮助研究人员和开发者更高效地训练出符合人类价值观的AI模型,从而提升AI系统的安全性、可靠性和实用性。未来,OpenRLHF有望成为RLHF领域的重要工具,推动AI技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) fine-tuned via Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) significantly improve the alignment of human-AI values, further raising the upper bound of AI capabilities, particularly in reasoning-intensive, long-context Chain-of-Thought (CoT) tasks. However, existing frameworks commonly face challenges such as inference bottlenecks and complexity barriers, which restrict their accessibility to newcomers. To bridge this gap, we introduce \textbf{OpenRLHF}, a user-friendly, scalable, and easy-to-learn open-source RLHF framework built upon Ray, vLLM, DeepSpeed, and HuggingFace Transformers, featuring a simplified design, clear code structure, and comprehensive documentation to facilitate entry for researchers and practitioners. Experimental results show that OpenRLHF achieves superior training efficiency, with speedups ranging from 1.22x to 1.68x across different model sizes, compared to state-of-the-art frameworks. Additionally, it requires significantly fewer lines of code for implementation. OpenRLHF is publicly available at https://github.com/OpenRLHF/OpenRLHF, and has already been adopted by leading institutions to accelerate RLHF research and learning.