Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
作者: Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
分类: cs.AI, cs.CL, cs.CV, cs.MM
发布日期: 2024-05-18
备注: 22 pages, 13 figures. Project Website: https://uni-moe.github.io/. Working in progress
🔗 代码/项目: GITHUB
💡 一句话要点
Uni-MoE:通过混合专家模型扩展统一多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 混合专家模型 大语言模型 跨模态对齐 统一模型 模型扩展 指令微调
📋 核心要点
- 现有多模态大语言模型扩展性不足,计算成本高昂,且难以有效处理多种模态的混合数据。
- Uni-MoE采用混合专家架构,通过模态特定编码器和连接器实现统一的多模态表示,并使用渐进式训练策略。
- 实验表明,Uni-MoE显著降低了混合多模态数据集的性能偏差,并提升了多专家协作和泛化能力。
📝 摘要(中文)
多模态大语言模型(MLLM)的最新进展强调了可扩展模型和数据对于提升性能的重要性,但这通常会带来巨大的计算成本。虽然混合专家(MoE)架构已被用于有效地扩展大型语言和图像-文本模型,但这些尝试通常涉及较少的专家和有限的模态。为了解决这个问题,我们的工作首次尝试开发一个具有MoE架构的统一MLLM,名为Uni-MoE,它可以处理各种模态。具体来说,它具有模态特定的编码器和连接器,用于统一的多模态表示。我们还在LLM中实现了一个稀疏MoE架构,通过模态级数据并行和专家级模型并行来实现高效的训练和推理。为了增强多专家协作和泛化能力,我们提出了一种渐进式训练策略:1)使用具有不同跨模态数据的各种连接器进行跨模态对齐,2)使用跨模态指令数据训练模态特定的专家以激活专家的偏好,3)利用低秩适应(LoRA)在混合多模态指令数据上调整Uni-MoE框架。我们在全面的多模态数据集上评估了指令调整后的Uni-MoE。大量的实验结果表明,Uni-MoE的主要优势在于显著减少了处理混合多模态数据集时的性能偏差,同时提高了多专家协作和泛化能力。我们的研究结果突出了MoE框架在推进MLLM方面的巨大潜力,代码可在https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs上找到。
🔬 方法详解
问题定义:现有的大型多模态语言模型在扩展性和处理多种模态混合数据时面临挑战。传统的模型扩展方法往往需要大量的计算资源,并且在处理不同模态的数据时容易出现性能偏差,难以充分利用不同模态之间的互补信息。
核心思路:Uni-MoE的核心思路是利用混合专家(MoE)架构,将模型分解为多个模态特定的专家,每个专家负责处理特定模态的数据。通过这种方式,模型可以更有效地利用参数,并在处理混合模态数据时减少性能偏差。同时,采用渐进式训练策略,逐步提升多专家之间的协作和泛化能力。
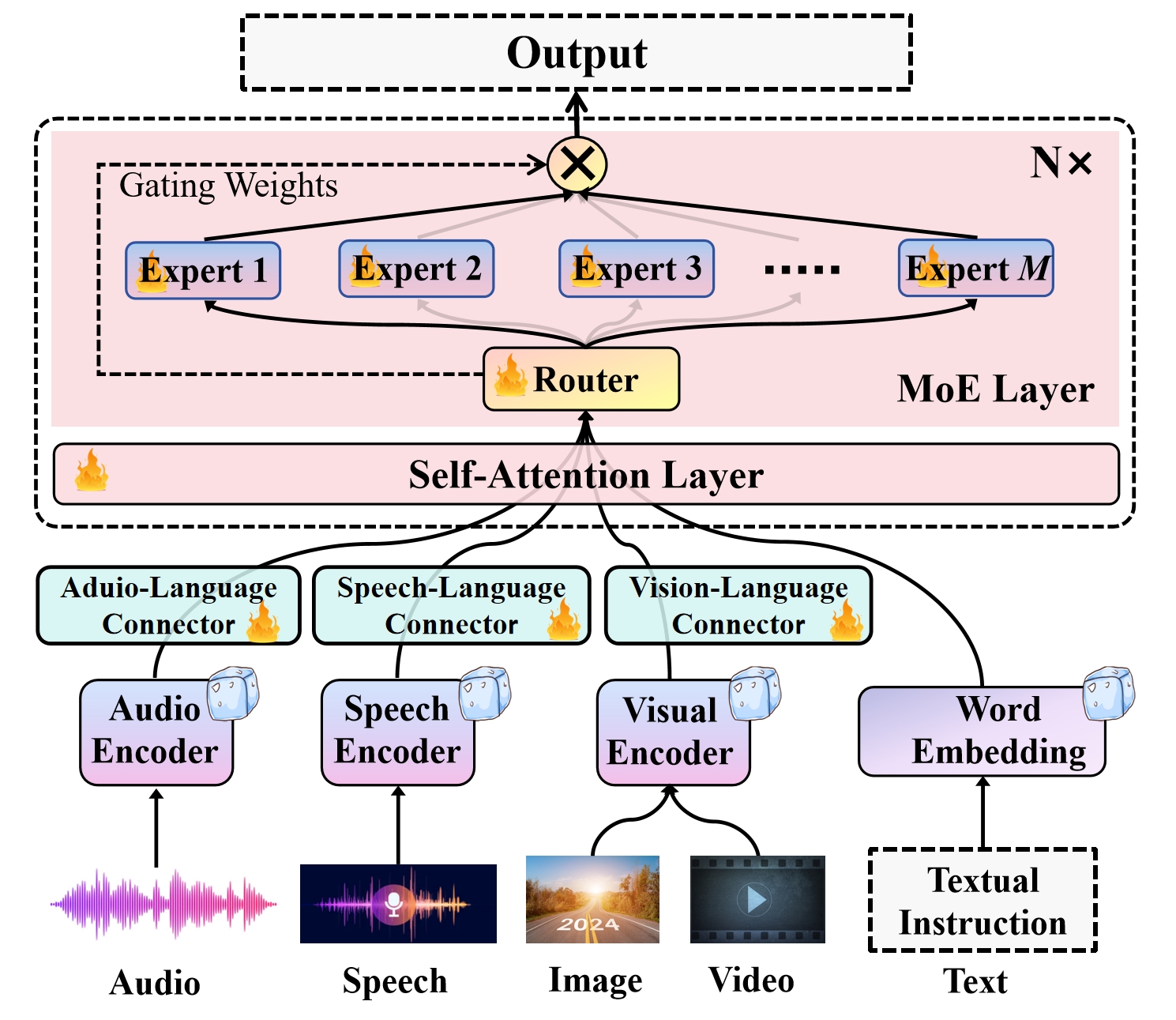
技术框架:Uni-MoE的整体架构包括模态特定的编码器、连接器和LLM。模态特定的编码器负责将不同模态的数据转换为统一的表示。连接器用于跨模态对齐,将不同模态的表示融合在一起。LLM则利用MoE架构,包含多个专家,每个专家负责处理特定模态或模态组合的数据。训练过程采用渐进式策略,包括跨模态对齐、模态特定专家训练和Uni-MoE框架微调三个阶段。
关键创新:Uni-MoE的关键创新在于首次将MoE架构应用于统一的多模态大语言模型,并提出了渐进式训练策略。与传统的单体模型相比,Uni-MoE能够更有效地利用参数,并在处理混合模态数据时减少性能偏差。渐进式训练策略则有助于提升多专家之间的协作和泛化能力。
关键设计:Uni-MoE的关键设计包括模态特定编码器的选择、连接器的设计、MoE架构的配置和渐进式训练策略的实现。模态特定编码器可以根据不同模态的特点选择合适的网络结构。连接器可以采用不同的跨模态融合方法,如注意力机制或线性变换。MoE架构的配置包括专家数量、路由策略等。渐进式训练策略则需要仔细设计每个阶段的训练目标和数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Uni-MoE在处理混合多模态数据集时,显著降低了性能偏差,并提高了多专家协作和泛化能力。具体而言,Uni-MoE在多个多模态数据集上取得了优于现有模型的性能,证明了MoE框架在推进MLLM方面的巨大潜力。代码已开源,方便研究人员进行进一步研究和应用。
🎯 应用场景
Uni-MoE具有广泛的应用前景,例如智能问答、多模态内容生成、跨模态检索等。它可以应用于需要处理多种模态数据的场景,例如医疗诊断、自动驾驶、智能客服等。通过有效融合不同模态的信息,Uni-MoE可以提供更准确、更全面的服务,提升用户体验。
📄 摘要(原文)
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.