ENOVA: Autoscaling towards Cost-effective and Stable Serverless LLM Serving
作者: Tao Huang, Pengfei Chen, Kyoka Gong, Jocky Hawk, Zachary Bright, Wenxin Xie, Kecheng Huang, Zhi Ji
分类: cs.DC, cs.AI
发布日期: 2024-05-17
💡 一句话要点
ENOVA:面向高性价比和稳定性的Serverless LLM服务自动扩缩容方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Serverless LLM服务 自动扩缩容 多GPU集群 性能优化 资源调度
📋 核心要点
- 多GPU集群中LLM服务部署面临应用多样性和共址带来的服务质量和GPU利用率挑战。
- ENOVA通过解构LLM执行过程,实现配置推荐和性能检测,从而进行自动部署和扩缩容。
- 实验结果表明,ENOVA显著优于现有方法,适合大规模在线系统部署,提升服务性能。
📝 摘要(中文)
随着大型语言模型(LLM)后端系统日益普及,在多GPU集群上部署具有自动扩缩容功能的稳定serverless LLM服务变得常见且必要。然而,多GPU集群中应用的多样性和共址会导致服务质量和GPU利用率降低。为了解决这些问题,我们构建了ENOVA,一个面向serverless LLM服务的部署、监控和自动扩缩容服务。ENOVA全面解构了LLM服务的执行过程,在此基础上,ENOVA设计了一个配置推荐模块,用于在任何GPU集群上自动部署,以及一个性能检测模块,用于自动扩缩容。在此之上,ENOVA实现了一个用于多GPU集群调度的部署执行引擎。实验结果表明,ENOVA显著优于其他最先进的方法,适用于大型在线系统中的广泛部署。
🔬 方法详解
问题定义:论文旨在解决在多GPU集群上部署serverless LLM服务时,由于应用多样性和共址带来的服务质量下降和GPU利用率低下的问题。现有的方法难以在保证服务质量的同时,充分利用GPU资源,并且缺乏自动化的部署和扩缩容机制。
核心思路:ENOVA的核心思路是通过全面解构LLM服务的执行过程,深入理解其性能瓶颈,从而设计出能够根据集群状态和负载情况进行智能配置推荐和自动扩缩容的机制。通过这种方式,ENOVA能够最大化GPU利用率,同时保证LLM服务的稳定性和服务质量。
技术框架:ENOVA包含三个主要模块:配置推荐模块、性能检测模块和部署执行引擎。配置推荐模块负责根据GPU集群的硬件配置和LLM服务的需求,自动生成最佳的部署配置。性能检测模块实时监控LLM服务的性能指标,如延迟、吞吐量和GPU利用率。部署执行引擎负责根据配置推荐和性能检测的结果,在多GPU集群上调度和部署LLM服务,并进行自动扩缩容。
关键创新:ENOVA的关键创新在于其对LLM服务执行过程的全面解构,以及基于此的配置推荐和性能检测机制。与现有方法相比,ENOVA能够更精确地预测LLM服务的性能,并根据实际负载情况进行动态调整,从而实现更高的GPU利用率和更好的服务质量。
关键设计:ENOVA的配置推荐模块可能采用了机器学习模型,根据历史数据和集群状态预测最佳配置。性能检测模块可能使用了细粒度的性能监控工具,实时收集LLM服务的各项指标。部署执行引擎可能采用了基于容器的调度技术,实现快速部署和扩缩容。具体的参数设置、损失函数和网络结构等细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片
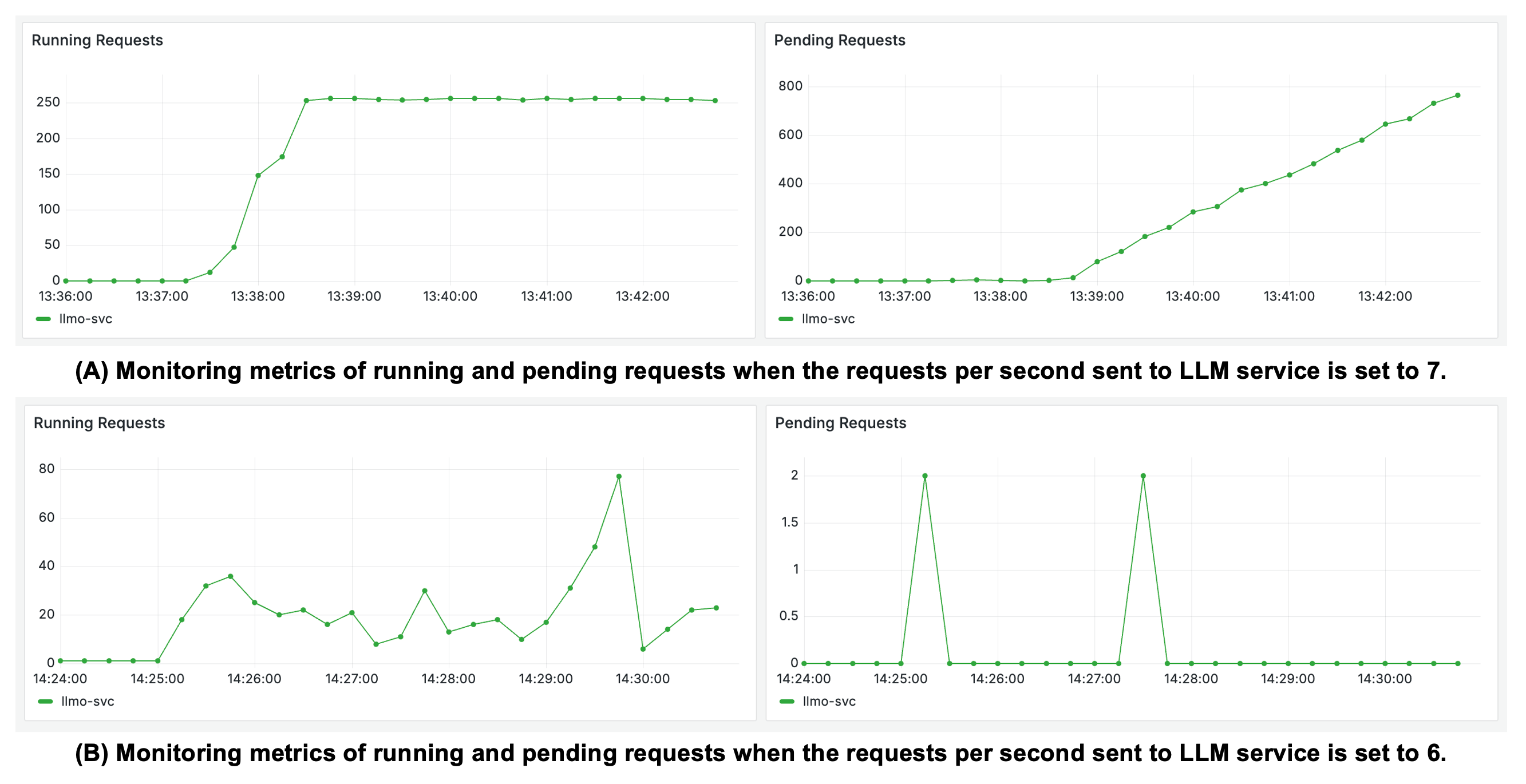
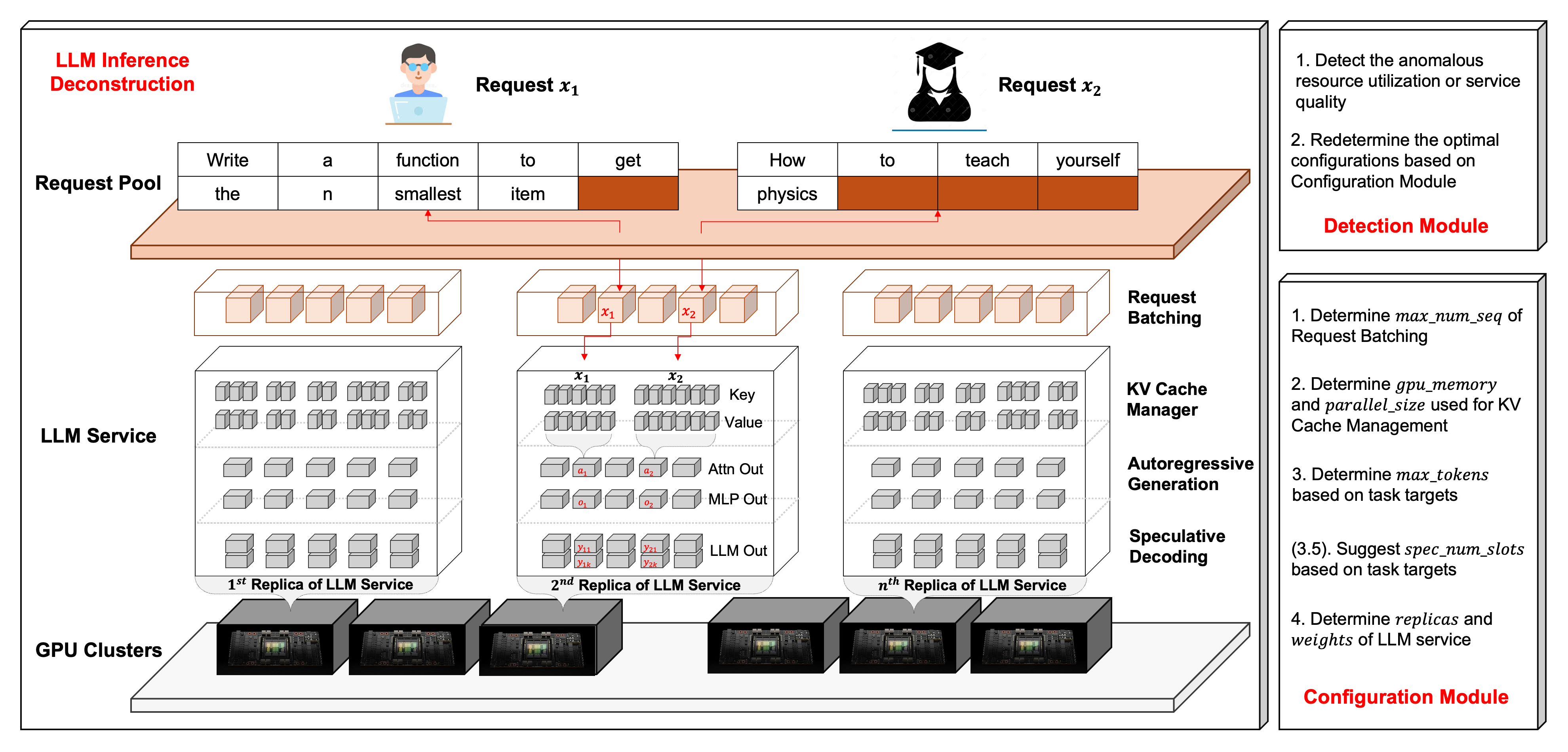
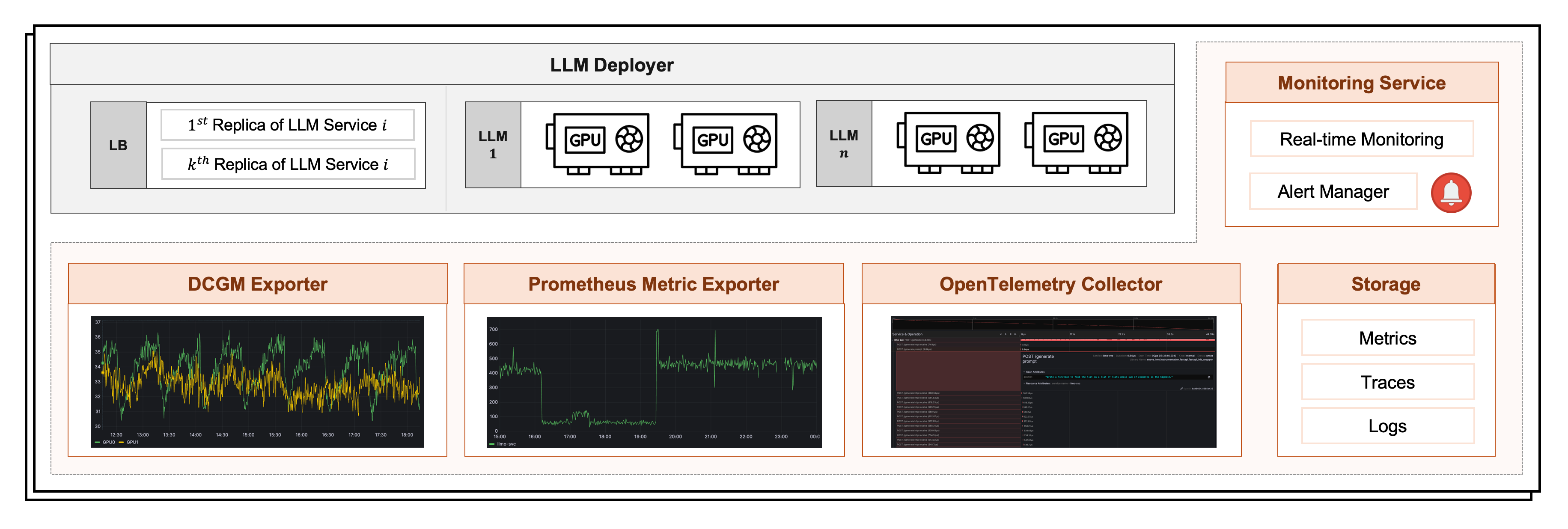
📊 实验亮点
论文实验结果表明,ENOVA在多GPU集群上部署LLM服务时,显著优于其他现有方法。具体的性能提升数据(例如延迟降低百分比、吞吐量提升百分比、GPU利用率提升百分比)需要在论文中查找。ENOVA的优势在于其自动化的部署和扩缩容机制,以及对LLM服务性能的精确预测和优化。
🎯 应用场景
ENOVA适用于需要大规模部署LLM服务的各种场景,例如在线问答系统、智能客服、文本生成等。通过ENOVA,企业可以更高效地利用GPU资源,降低运营成本,并提供更稳定、更高质量的LLM服务。该研究的成果有助于推动LLM技术在各行业的广泛应用。
📄 摘要(原文)
Since the increasing popularity of large language model (LLM) backend systems, it is common and necessary to deploy stable serverless serving of LLM on multi-GPU clusters with autoscaling. However, there exist challenges because the diversity and co-location of applications in multi-GPU clusters will lead to low service quality and GPU utilization. To address them, we build ENOVA, a deployment, monitoring and autoscaling service towards serverless LLM serving. ENOVA deconstructs the execution process of LLM service comprehensively, based on which ENOVA designs a configuration recommendation module for automatic deployment on any GPU clusters and a performance detection module for autoscaling. On top of them, ENOVA implements a deployment execution engine for multi-GPU cluster scheduling. The experiment results show that ENOVA significantly outperforms other state-of-the-art methods and is suitable for wide deployment in large online systems.