Investigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learning
作者: Alain Riou, Stefan Lattner, Gaëtan Hadjeres, Geoffroy Peeters
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2024-05-14
备注: Self-supervision in Audio, Speech and Beyond workshop, IEEE International Conference on Acoustics, Speech, and Signal Processing, 2024
💡 一句话要点
探索JEPA框架下音频表征学习的设计选择,揭示图像与音频模态差异
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 音频表征学习 自监督学习 联合嵌入预测架构 梅尔频谱图 音频分类
📋 核心要点
- 现有自监督音频表征学习方法在不同模态间迁移时效果不佳,需要针对音频特性进行优化。
- 本文探索了JEPA框架在音频表征学习中的应用,通过预测目标表征来学习音频的通用表征。
- 实验表明,上下文和目标的选择对模型性能有显著影响,图像领域有效的设计在音频领域表现不佳。
📝 摘要(中文)
本文研究了自监督通用音频表征学习问题。我们探索了联合嵌入预测架构(JEPA)在该任务中的应用,该架构将输入梅尔频谱图分成两部分(上下文和目标),计算各自的神经表征,并训练神经网络以根据上下文表征预测目标表征。我们研究了该框架内的几个设计选择,并通过在各种音频分类基准(包括环境声音、语音和音乐下游任务)上评估我们的模型来研究它们的影响。我们特别关注输入数据的哪一部分用作上下文或目标,并通过实验表明它会显着影响模型的质量。特别地,我们注意到图像领域中一些有效的设计选择会导致音频的性能不佳,从而突出了这两种模态之间的主要差异。
🔬 方法详解
问题定义:论文旨在解决自监督通用音频表征学习问题。现有方法在图像领域表现良好,但直接应用于音频领域效果不佳,表明音频数据特性与图像数据存在显著差异。因此,需要探索适用于音频数据的自监督学习方法,并研究不同设计选择对模型性能的影响。
核心思路:论文的核心思路是利用联合嵌入预测架构(JEPA)学习音频的通用表征。JEPA通过将输入音频数据分割成上下文和目标两部分,并训练模型根据上下文预测目标表征,从而学习到音频数据的内在结构和特征。通过改变上下文和目标的选择,可以探索不同的学习策略,并找到最适合音频数据的设计。
技术框架:整体框架包括以下几个主要步骤:1) 输入音频数据预处理,提取梅尔频谱图;2) 将梅尔频谱图分割成上下文和目标两部分;3) 分别使用神经网络计算上下文和目标的表征;4) 使用预测模块根据上下文表征预测目标表征;5) 使用损失函数衡量预测表征和真实目标表征之间的差异,并更新模型参数。
关键创新:论文的关键创新在于对JEPA框架在音频领域的适用性进行了深入研究,并发现图像领域有效的上下文-目标选择策略在音频领域表现不佳。这表明音频和图像数据在结构和特征上存在显著差异,需要针对音频数据设计特定的学习策略。
关键设计:论文的关键设计包括:1) 上下文和目标的选择策略,例如选择不同的时间片段或频率范围作为上下文和目标;2) 神经网络的结构,例如使用卷积神经网络或Transformer网络;3) 损失函数的选择,例如使用均方误差或对比损失;4) 训练参数的设置,例如学习率、batch size等。
🖼️ 关键图片

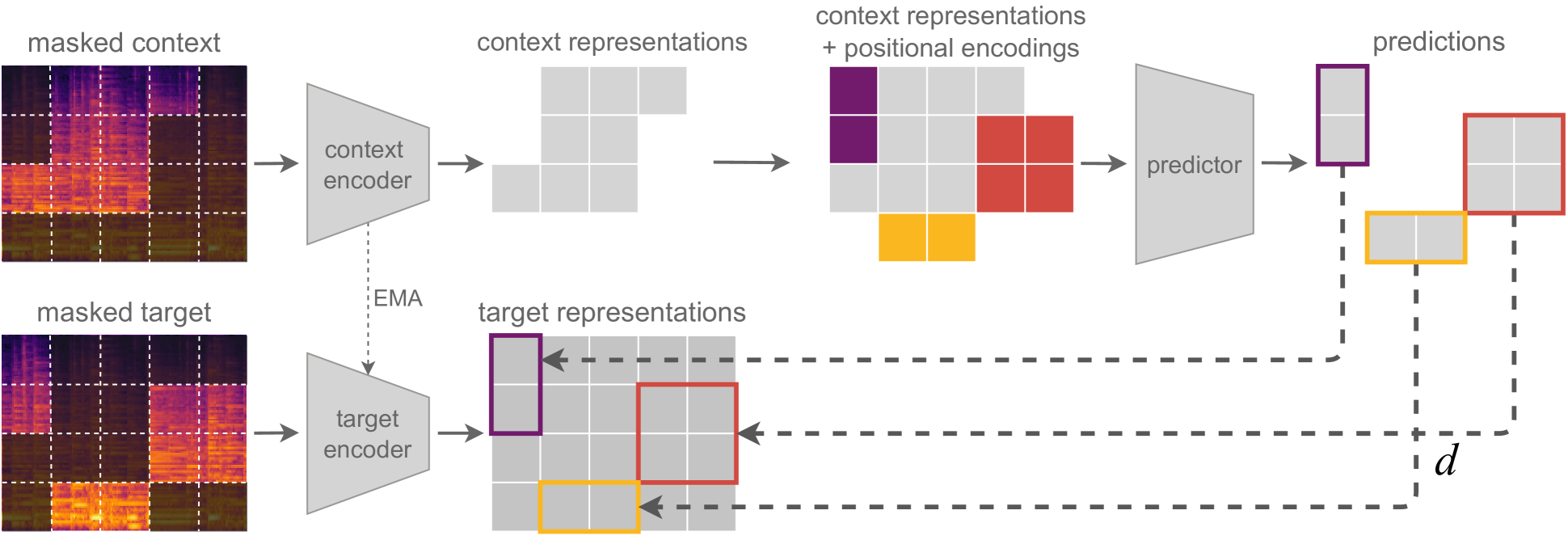
📊 实验亮点
实验结果表明,上下文和目标的选择对模型性能有显著影响。在图像领域有效的策略,如预测相邻区域,在音频领域表现不佳。针对音频数据特性设计的策略,如预测未来的时间片段,可以获得更好的性能。通过在多个音频分类基准上进行评估,验证了所提出方法的有效性。
🎯 应用场景
该研究成果可应用于各种音频分析任务,如环境声音识别、语音识别、音乐分类等。通过学习通用的音频表征,可以减少对标注数据的依赖,提高模型在不同任务上的泛化能力。此外,该研究还可以促进跨模态学习的研究,例如将音频和视频信息结合起来进行分析。
📄 摘要(原文)
This paper addresses the problem of self-supervised general-purpose audio representation learning. We explore the use of Joint-Embedding Predictive Architectures (JEPA) for this task, which consists of splitting an input mel-spectrogram into two parts (context and target), computing neural representations for each, and training the neural network to predict the target representations from the context representations. We investigate several design choices within this framework and study their influence through extensive experiments by evaluating our models on various audio classification benchmarks, including environmental sounds, speech and music downstream tasks. We focus notably on which part of the input data is used as context or target and show experimentally that it significantly impacts the model's quality. In particular, we notice that some effective design choices in the image domain lead to poor performance on audio, thus highlighting major differences between these two modalities.