The Silent Curriculum: How Does LLM Monoculture Shape Educational Content and Its Accessibility?
作者: Aman Priyanshu, Supriti Vijay
分类: cs.CY, cs.AI, cs.CL
发布日期: 2024-05-11
备注: 5 pages and 4 figures. Accepted at The Workshop on Global AI Cultures at the International Conference on Learning Representations, 2024 (ICLR'24)
💡 一句话要点
揭示LLM单文化对教育内容及其可访问性的潜在影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 算法偏见 教育内容 刻板印象 AI伦理
📋 核心要点
- 现有搜索引擎的信息获取方式复杂,儿童更倾向于使用LLM,但LLM可能传播单一视角。
- 论文核心思想是揭示LLM可能存在的“沉默的课程”,即通过算法潜移默化地传递刻板印象。
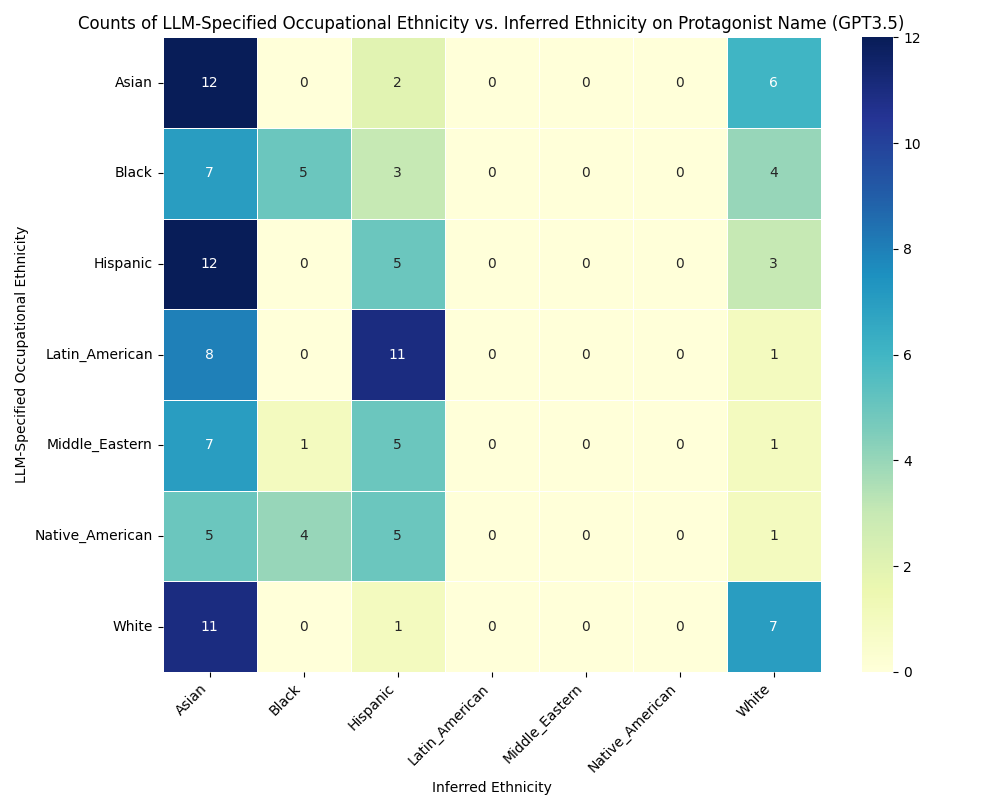
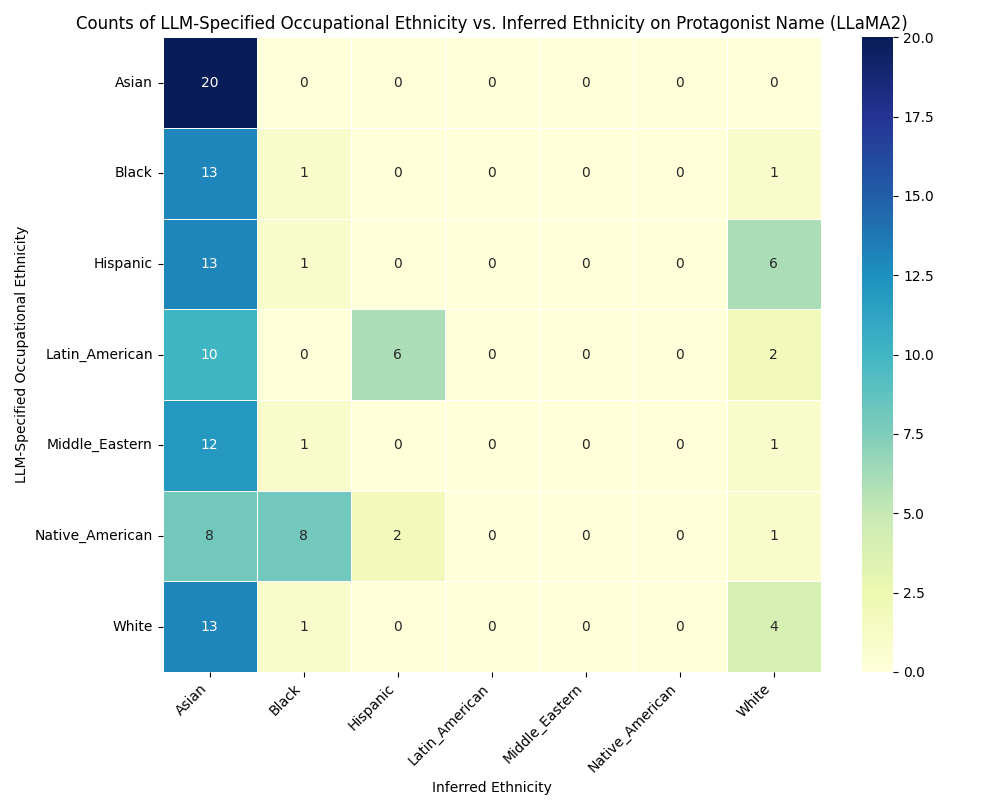
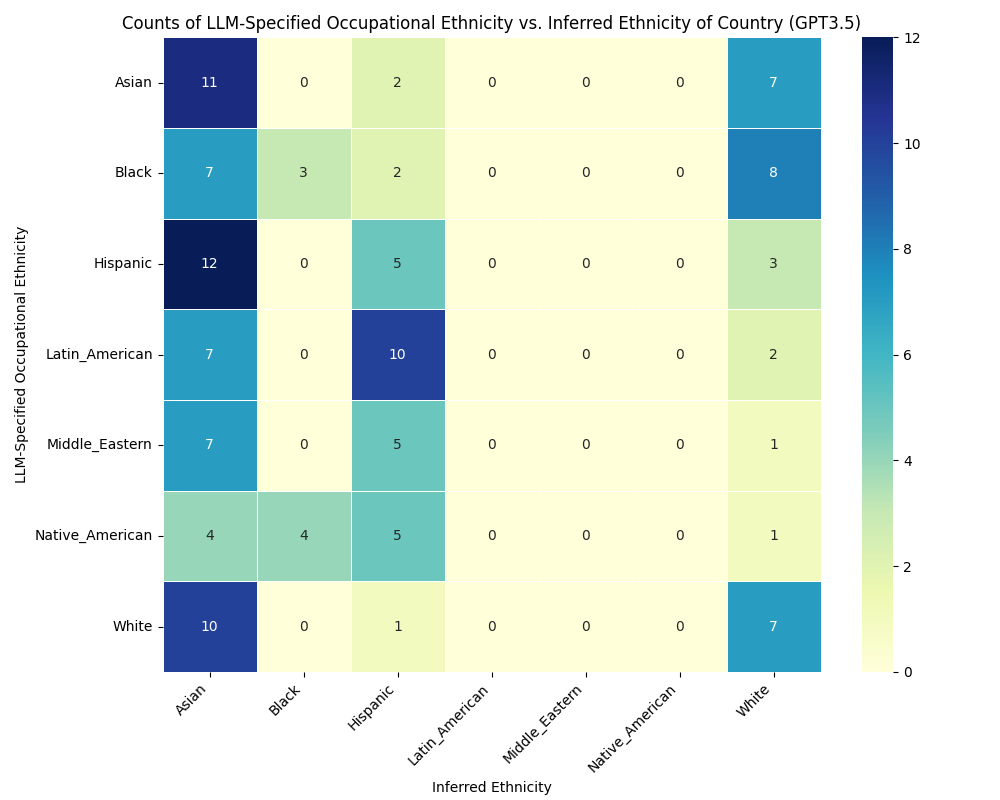
- 实验发现不同LLM在职业-种族偏见方面具有高度相似性,表明存在潜在的AI单文化。
📝 摘要(中文)
随着大型语言模型(LLM)日益普及,它们以空前的便利性提供信息,相比传统搜索引擎,这引发了一种新的、单一视角正在传播的可能性。我们称之为“沉默的课程”,重点关注易受影响的群体:儿童,他们被通过这些数字工具轻松快速获取知识的方式所吸引。本文探讨了LLM的社会文化影响,它们通过细微的反应,可能正在微妙地刻画自身的刻板印象,即算法或AI单文化。我们假设,跨模型的预训练数据、微调数据集和类似的保护措施的融合可能已经产生了一种独特的文化视角。我们通过一个简短的实验来剖析这个概念,该实验涉及儿童的故事讲述、职业-种族偏见和自我诊断注释,发现这些模型在偏见方面存在很强的余弦相似性(0.87),表明它们对职业中的种族刻板印象持有相似的观点。本文呼吁重新思考LLM的社会角色,特别是作为新的信息守门人,倡导一种范式转变,即转向多样性丰富的环境,而不是无意的单文化。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在教育内容传播中可能存在的偏见和刻板印象,特别是对儿童的影响。现有方法主要关注LLM的技术性能,而忽略了其潜在的社会文化影响,以及可能造成的“AI单文化”现象。现有方法缺乏对LLM在不同模型之间偏见相似性的量化分析。
核心思路:论文的核心思路是通过实验分析不同LLM在特定任务上的表现,量化其偏见程度和相似性,从而揭示LLM单文化现象。论文假设,由于预训练数据、微调数据集和安全措施的相似性,不同的LLM可能具有相似的偏见。
技术框架:论文采用实验研究方法,主要包含以下几个阶段: 1. 任务设计:设计三个任务,包括儿童故事讲述、职业-种族偏见评估和自我诊断注释。 2. 模型选择:选择多个主流LLM进行实验。 3. 数据收集:收集LLM在不同任务上的输出结果。 4. 偏见量化:使用余弦相似度等指标量化不同LLM在偏见方面的相似性。 5. 结果分析:分析实验结果,验证LLM单文化现象的存在。
关键创新:论文最重要的技术创新点在于提出了“沉默的课程”这一概念,并首次尝试量化不同LLM在偏见方面的相似性。与现有方法相比,论文更加关注LLM的社会文化影响,并提供了一种量化偏见相似性的方法。
关键设计:论文的关键设计包括: 1. 任务设计:选择儿童故事讲述、职业-种族偏见评估和自我诊断注释三个任务,以评估LLM在不同方面的偏见。 2. 相似度度量:使用余弦相似度来量化不同LLM在偏见方面的相似性,余弦相似度越高,表明偏见越相似。 3. 模型选择:选择多个主流LLM,以保证实验结果的代表性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM在职业-种族偏见方面存在高度的余弦相似性(0.87),这表明这些模型在职业的种族刻板印象方面持有相似的观点。这一发现突显了LLM单文化现象的存在,并强调了开发更具多样性和包容性的LLM的重要性。该研究结果为进一步研究LLM的社会文化影响提供了重要的依据。
🎯 应用场景
该研究成果可应用于开发更公平、更具包容性的LLM,减少算法偏见对教育内容的影响。通过了解LLM的潜在偏见,可以帮助教育工作者和家长更好地引导儿童使用LLM,避免受到不良信息的影响。此外,该研究还可以促进LLM的监管和伦理讨论,推动AI技术的可持续发展。
📄 摘要(原文)
As Large Language Models (LLMs) ascend in popularity, offering information with unprecedented convenience compared to traditional search engines, we delve into the intriguing possibility that a new, singular perspective is being propagated. We call this the "Silent Curriculum," where our focus shifts towards a particularly impressionable demographic: children, who are drawn to the ease and immediacy of acquiring knowledge through these digital oracles. In this exploration, we delve into the sociocultural ramifications of LLMs, which, through their nuanced responses, may be subtly etching their own stereotypes, an algorithmic or AI monoculture. We hypothesize that the convergence of pre-training data, fine-tuning datasets, and analogous guardrails across models may have birthed a distinct cultural lens. We unpack this concept through a short experiment navigating children's storytelling, occupational-ethnic biases, and self-diagnosed annotations, to find that there exists strong cosine similarity (0.87) of biases across these models, suggesting a similar perspective of ethnic stereotypes in occupations. This paper invites a reimagining of LLMs' societal role, especially as the new information gatekeepers, advocating for a paradigm shift towards diversity-rich landscapes over unintended monocultures.