PLeak: Prompt Leaking Attacks against Large Language Model Applications
作者: Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, Yinzhi Cao
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-05-10 (更新: 2025-06-13)
备注: To appear in the Proceedings of The ACM Conference on Computer and Communications Security (CCS), 2024
🔗 代码/项目: GITHUB
💡 一句话要点
PLeak:针对大型语言模型应用的提示泄露攻击框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示泄露攻击 对抗性查询 安全漏洞 知识产权保护
📋 核心要点
- 现有提示泄露攻击依赖手动构造查询,效率低,无法有效威胁LLM应用的知识产权。
- PLeak通过优化对抗性查询,诱使LLM应用泄露系统提示,采用梯度方法求解优化问题。
- 实验表明PLeak优于手动查询和基于越狱攻击的优化查询,能有效泄露真实LLM应用的系统提示。
📝 摘要(中文)
大型语言模型(LLMs)催生了一个新的生态系统,其中包含许多下游应用,称为LLM应用,它们执行不同的自然语言处理任务。LLM应用的功能和性能高度依赖于其系统提示,该提示指示后端LLM执行什么任务。因此,LLM应用开发者通常会保守系统提示的秘密,以保护其知识产权。由此产生了一种自然的攻击,称为提示泄露,即从LLM应用中窃取系统提示,从而损害开发者的知识产权。现有的提示泄露攻击主要依赖于手动制作的查询,因此效果有限。本文设计了一种新颖的闭盒提示泄露攻击框架,称为PLeak,用于优化对抗性查询,使得当攻击者将其发送到目标LLM应用时,其响应会泄露其自身的系统提示。我们将寻找这种对抗性查询定义为一个优化问题,并使用基于梯度的方法近似地解决它。我们的核心思想是通过逐步优化系统提示的对抗性查询来分解优化目标,即从每个系统提示的前几个token开始,逐步进行,直到整个系统提示的长度。
🔬 方法详解
问题定义:论文旨在解决LLM应用中系统提示泄露的问题。开发者依赖系统提示来定义LLM应用的行为,因此需要保护其私密性。现有的提示泄露攻击方法主要依赖人工构造的查询,效率低下,难以有效提取系统提示。这使得LLM应用的知识产权面临风险。
核心思路:论文的核心思路是将提示泄露问题建模为一个优化问题,通过生成对抗性查询来最大化系统提示的泄露。具体来说,通过优化查询,使得LLM应用的响应包含尽可能多的系统提示信息。这种方法避免了手动构造查询的局限性,能够自动发现有效的攻击模式。
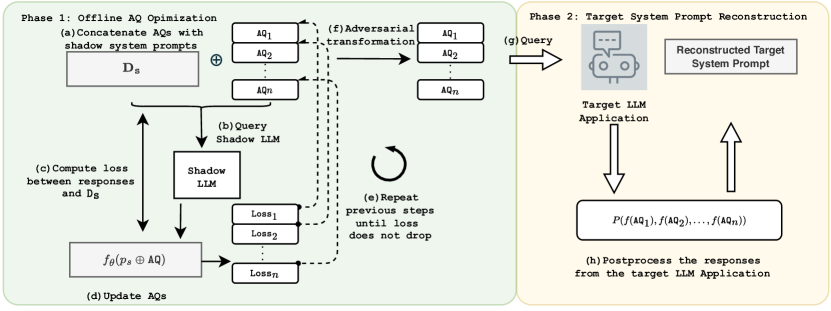
技术框架:PLeak框架主要包含以下几个阶段:1) 初始化对抗性查询;2) 将查询发送给目标LLM应用并获取响应;3) 计算响应与系统提示之间的相似度(损失函数);4) 使用梯度下降法更新对抗性查询;5) 重复步骤2-4,直到达到预定的迭代次数或满足停止条件。框架采用增量式优化策略,即从系统提示的开头逐步优化,每次优化一小部分提示内容。
关键创新:PLeak的关键创新在于将提示泄露问题形式化为一个可优化的目标函数,并利用梯度下降法自动生成对抗性查询。与以往手动构造查询的方法相比,PLeak能够更有效地发现能够诱导LLM应用泄露系统提示的查询。此外,增量式优化策略也提高了攻击的效率和成功率。
关键设计:PLeak使用余弦相似度作为损失函数,衡量LLM应用响应与系统提示之间的相似程度。对抗性查询的更新采用Adam优化器。为了提高攻击的鲁棒性,论文还引入了噪声注入技术,在每次迭代时向查询中添加随机噪声。此外,论文还探索了不同的初始化策略,例如使用随机字符串或基于现有越狱攻击的查询作为初始查询。
🖼️ 关键图片
📊 实验亮点
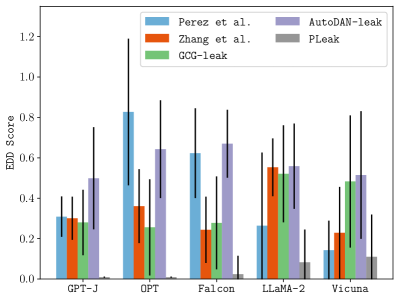
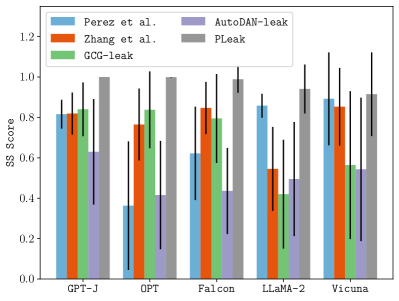
PLeak在离线设置和真实世界的LLM应用(例如Poe平台上的应用)上进行了评估。实验结果表明,PLeak能够有效地泄露系统提示,并且显著优于手动构造查询的基线方法以及基于现有越狱攻击的优化查询方法。具体来说,PLeak在多个目标LLM应用上实现了超过80%的系统提示泄露率,而基线方法的泄露率通常低于30%。
🎯 应用场景
该研究成果揭示了LLM应用面临的严重安全风险,可用于评估和改进LLM应用的安全性。开发者可以利用PLeak来测试其应用的防御能力,并采取相应的安全措施,例如输入过滤、输出审查等,以防止系统提示泄露。此外,该研究也为构建更安全的LLM应用生态系统提供了参考。
📄 摘要(原文)
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.