An Investigation of Incorporating Mamba for Speech Enhancement
作者: Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, Yu Tsao
分类: cs.SD, cs.AI, eess.AS
发布日期: 2024-05-10 (更新: 2025-10-07)
备注: Accepted to IEEE SLT 2024
💡 一句话要点
探索Mamba在语音增强中的应用,实现高效且具竞争力的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音增强 Mamba模型 状态空间模型 长序列建模 计算效率 自动语音识别 VoiceBank-DEMAND
📋 核心要点
- 现有语音增强方法计算成本高昂,尤其是在处理长序列时,限制了其在资源受限设备上的应用。
- 本研究探索使用Mamba模型进行语音增强,Mamba是一种新型状态空间模型,具有高效的计算效率和长序列建模能力。
- 实验结果表明,基于Mamba的语音增强模型在性能上具有竞争力,并且在计算效率上优于基于Transformer的模型。
📝 摘要(中文)
本研究旨在探索一种新兴的、无注意力机制且可扩展的状态空间模型(SSM)——Mamba,在语音增强(SE)任务中的应用。具体而言,我们利用Mamba部署了不同的基于回归的语音增强模型(SEMamba),并采用了不同的配置,包括基本型、高级型、因果型和非因果型。此外,还考虑了基于信号级距离或面向度量的损失函数。实验结果表明,采用高级非因果配置的SEMamba在VoiceBank-DEMAND数据集上获得了具有竞争力的PESQ评分3.55。当SEMamba与感知对比度拉伸(PCS)相结合时,PESQ评分达到了新的state-of-the-art,为3.69。与基于Transformer的等效语音增强解决方案相比,高级非因果配置的FLOPs减少了高达约12%。最后,SEMamba可以用作自动语音识别(ASR)之前的预处理步骤,展现出与最新语音增强解决方案相媲美的性能。
🔬 方法详解
问题定义:语音增强旨在从噪声环境中提取清晰的语音信号。现有方法,特别是基于Transformer的模型,在处理长语音序列时计算复杂度高,需要大量的计算资源和时间。这限制了它们在实时应用和资源受限设备上的部署。
核心思路:本研究的核心思路是利用Mamba模型替代Transformer模型进行语音增强。Mamba是一种状态空间模型,通过选择性状态空间机制,能够高效地处理长序列数据,降低计算复杂度,同时保持甚至提升语音增强的性能。
技术框架:该研究构建了SEMamba模型,即基于Mamba的语音增强模型。该模型采用编码器-解码器结构,其中编码器和解码器均由Mamba块组成。研究中探索了不同的SEMamba配置,包括基本型、高级型、因果型和非因果型,以适应不同的应用场景。同时,研究还考虑了不同的损失函数,包括基于信号级距离的损失函数和面向度量的损失函数。
关键创新:该研究的关键创新在于将Mamba模型引入到语音增强任务中。Mamba模型通过选择性状态空间机制,能够动态地选择和更新状态,从而更好地捕捉语音信号的时序依赖关系,并降低计算复杂度。与传统的基于Transformer的模型相比,Mamba模型在处理长序列数据时具有更高的效率。
关键设计:研究中探索了不同的Mamba块配置,包括基本型和高级型。高级型Mamba块采用了更复杂的结构,能够更好地捕捉语音信号的特征。此外,研究还考虑了因果和非因果两种配置。因果配置适用于实时语音增强,而非因果配置则可以利用整个语音序列的信息,从而获得更好的性能。研究中还使用了不同的损失函数,包括L1损失、L2损失和感知损失,以优化模型的性能。
🖼️ 关键图片


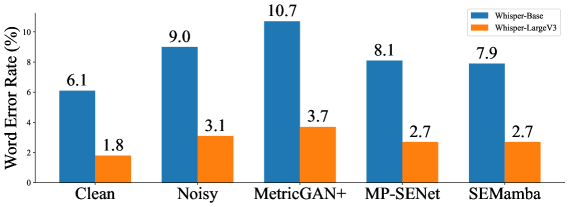
📊 实验亮点
实验结果表明,基于Mamba的语音增强模型(SEMamba)在VoiceBank-DEMAND数据集上取得了具有竞争力的性能。采用高级非因果配置的SEMamba获得了3.55的PESQ评分,与感知对比度拉伸(PCS)相结合时,PESQ评分达到了新的state-of-the-art,为3.69。此外,与基于Transformer的等效语音增强解决方案相比,高级非因果配置的FLOPs减少了高达约12%。
🎯 应用场景
该研究成果可应用于各种语音增强场景,例如移动通信、语音助手、助听器等。通过使用Mamba模型,可以在计算资源有限的设备上实现高效的语音增强,提高语音通信质量和语音识别准确率。此外,该研究还可以作为自动语音识别(ASR)的预处理步骤,提高ASR系统的鲁棒性。
📄 摘要(原文)
This work aims to investigate the use of a recently proposed, attention-free, scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. In particular, we employ Mamba to deploy different regression-based SE models (SEMamba) with different configurations, namely basic, advanced, causal, and non-causal. Furthermore, loss functions either based on signal-level distances or metric-oriented are considered. Experimental evidence shows that SEMamba attains a competitive PESQ of 3.55 on the VoiceBank-DEMAND dataset with the advanced, non-causal configuration. A new state-of-the-art PESQ of 3.69 is also reported when SEMamba is combined with Perceptual Contrast Stretching (PCS). Compared against Transformed-based equivalent SE solutions, a noticeable FLOPs reduction up to ~12% is observed with the advanced non-causal configurations. Finally, SEMamba can be used as a pre-processing step before automatic speech recognition (ASR), showing competitive performance against recent SE solutions.