Benchmarking Educational Program Repair
作者: Charles Koutcheme, Nicola Dainese, Sami Sarsa, Juho Leinonen, Arto Hellas, Paul Denny
分类: cs.SE, cs.AI, cs.CL, cs.CY
发布日期: 2024-05-08
备注: 15 pages, 2 figures, 3 tables. Non-archival report presented at the NeurIPS'23 Workshop on Generative AI for Education (GAIED)
💡 一句话要点
提出教育程序修复基准,促进LLM在编程教育中的公平比较。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序修复 编程教育 大型语言模型 基准测试 教育技术
📋 核心要点
- 现有编程教育研究使用定制数据集和评估指标,缺乏统一标准,难以公平比较不同LLM程序修复方法。
- 论文提出新的教育程序修复基准,包含高质量数据集和统一评估程序,使用rouge@k指标评估修复质量。
- 通过对五个最新模型进行评估,建立了基线性能,为未来研究提供参考,促进该领域发展。
📝 摘要(中文)
大型语言模型(LLMs)的出现因其在各种教育任务中的潜在应用而引起了极大的兴趣。例如,编程教育领域的最新研究已使用LLMs来生成学习资源、改进错误消息并提供代码反馈。然而,该领域进展的一个限制因素是,大量研究使用定制数据集和不同的评估指标,使得结果之间的直接比较不可靠。因此,迫切需要标准化和基准,以促进竞争方法之间的公平比较。程序修复是LLMs展现出巨大前景的一项任务,可用于为学生提供调试支持和下一步提示。在本文中,我们提出了一个新的教育程序修复基准。我们整理了两个高质量的公开编程数据集,提出了一个统一的评估程序,引入了一种新的评估指标rouge@k来近似修复的质量,并评估了一组最新的模型以建立基线性能。
🔬 方法详解
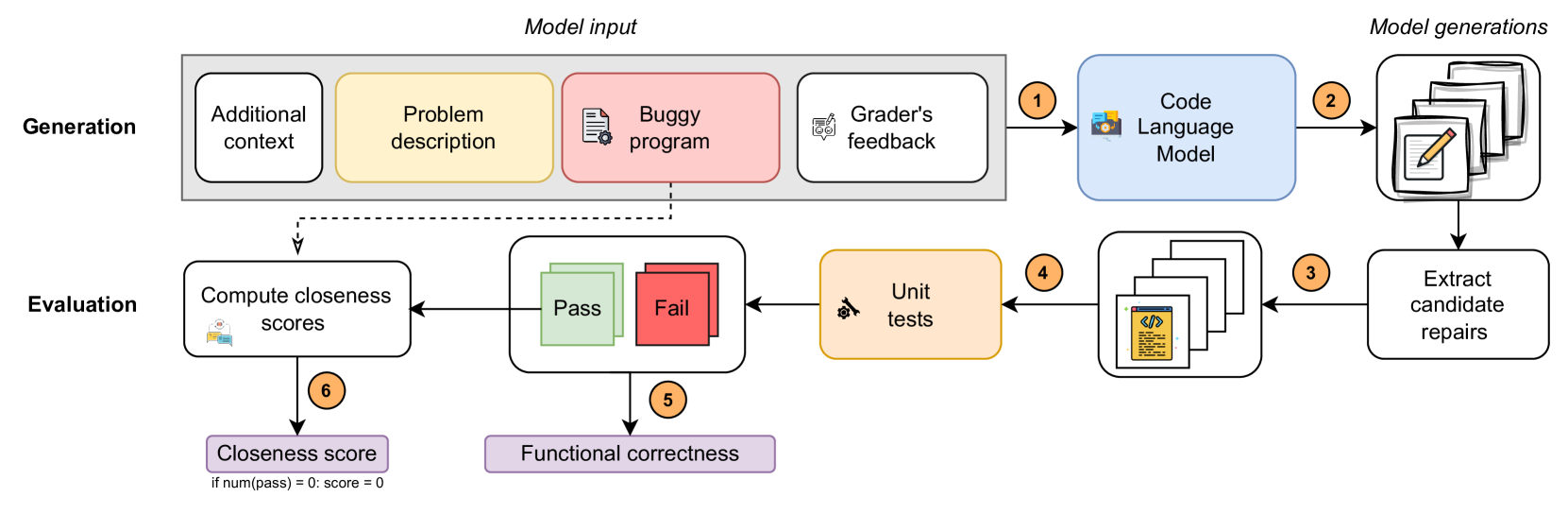
问题定义:论文旨在解决编程教育中LLM程序修复任务缺乏统一基准的问题。现有研究使用的数据集和评估指标各不相同,导致不同方法之间难以进行公平的比较和评估。这阻碍了该领域的发展,也使得研究人员难以判断哪种方法更有效。
核心思路:论文的核心思路是构建一个标准化的教育程序修复基准,包括高质量的公开数据集、统一的评估程序和合适的评估指标。通过提供一个共同的平台,研究人员可以更容易地比较不同方法的性能,从而促进该领域的发展。
技术框架:该基准主要包含以下几个部分:1) 数据集:选择两个高质量的公开编程数据集,确保数据的多样性和代表性。2) 评估程序:设计一个统一的评估程序,包括数据预处理、模型训练和测试等步骤,确保评估过程的一致性。3) 评估指标:引入一种新的评估指标rouge@k,用于近似修复的质量。该指标考虑了修复代码与正确代码之间的相似度,能够更准确地反映修复的有效性。4) 基线模型:选择一组最新的LLM模型作为基线,评估其在基准上的性能,为未来的研究提供参考。
关键创新:论文的关键创新在于提出了一个完整的教育程序修复基准,包括数据集、评估程序和评估指标。特别是,rouge@k指标的引入,能够更准确地评估修复的质量,弥补了现有评估指标的不足。此外,该基准的公开性和标准化,使得不同方法之间的比较更加公平和可靠。
关键设计:关于rouge@k指标,具体计算方式未知,但其核心思想是衡量修复后代码与正确代码之间的相似度,可能基于编辑距离或token overlap等方法。数据集的选择标准未知,但强调了高质量和公开性。基线模型的选择标准也未知,但选择了“一组最新的LLM模型”。
🖼️ 关键图片
📊 实验亮点
论文构建了教育程序修复基准,并使用rouge@k指标评估了五个最新LLM模型。虽然没有给出具体的性能数据和提升幅度,但该基准的建立为后续研究提供了统一的评估平台,使得不同方法之间的比较成为可能。通过基线模型的评估,为未来的研究提供了参考。
🎯 应用场景
该研究成果可广泛应用于编程教育领域,例如自动代码调试、智能编程辅导、个性化学习资源推荐等。通过利用LLM的程序修复能力,可以为学生提供及时的错误提示和修复建议,帮助他们更好地学习编程。此外,该基准的建立,将促进LLM在编程教育领域的进一步发展,推动教育技术的创新。
📄 摘要(原文)
The emergence of large language models (LLMs) has sparked enormous interest due to their potential application across a range of educational tasks. For example, recent work in programming education has used LLMs to generate learning resources, improve error messages, and provide feedback on code. However, one factor that limits progress within the field is that much of the research uses bespoke datasets and different evaluation metrics, making direct comparisons between results unreliable. Thus, there is a pressing need for standardization and benchmarks that facilitate the equitable comparison of competing approaches. One task where LLMs show great promise is program repair, which can be used to provide debugging support and next-step hints to students. In this article, we propose a novel educational program repair benchmark. We curate two high-quality publicly available programming datasets, present a unified evaluation procedure introducing a novel evaluation metric rouge@k for approximating the quality of repairs, and evaluate a set of five recent models to establish baseline performance.