Human-centric Reward Optimization for Reinforcement Learning-based Automated Driving using Large Language Models
作者: Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Yangfan He, Boyue Wang, Tianyu Shi, Alaa Khamis
分类: cs.AI
发布日期: 2024-05-07 (更新: 2024-12-26)
备注: 9 pages, 6 figures, 34 references
💡 一句话要点
提出基于大语言模型的人本奖励优化方法,提升强化学习自动驾驶拟人化程度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 大型语言模型 奖励函数优化 人本设计
📋 核心要点
- 现有基于强化学习的自动驾驶智能体难以兼顾灵活性、精确性和拟人化行为,且成本较高。
- 利用大语言模型理解人类驾驶意图,并将其转化为强化学习的奖励函数,引导智能体学习。
- 实验表明,该方法能有效提升自动驾驶智能体的拟人化程度和整体性能,具有实际应用价值。
📝 摘要(中文)
本文提出了一种创新方法,利用大型语言模型(LLM)以直观有效的方式优化基于强化学习(RL)的自动驾驶(AD)智能体的奖励函数,使其更具人本性。该框架将指令和动态环境描述输入到LLM中,LLM利用这些信息辅助生成奖励,从而引导RL智能体的行为更接近人类驾驶模式。实验结果表明,该方法不仅使RL智能体更具拟人化特征,而且实现了更好的性能。此外,还研究了各种奖励代理和奖励塑造策略,揭示了提示设计对塑造AD车辆行为的显著影响。这些发现为开发更先进、更像人类的自动驾驶系统提供了一个有希望的方向。实验数据和源代码已公开。
🔬 方法详解
问题定义:现有基于强化学习的自动驾驶系统,其奖励函数设计复杂且难以捕捉人类驾驶的细微之处,导致车辆行为不够自然流畅,缺乏拟人化特征。此外,手动调整奖励函数耗时耗力,难以适应复杂多变的交通环境。
核心思路:利用大型语言模型(LLM)的强大理解和生成能力,将人类驾驶行为的描述性指令和动态环境信息转化为强化学习的奖励信号。通过LLM理解人类驾驶意图,并将其融入奖励函数中,从而引导智能体学习更符合人类习惯的驾驶策略。
技术框架:该框架包含以下几个主要模块:1) 环境感知模块:负责获取车辆周围的动态环境信息,例如其他车辆的位置、速度等。2) 指令输入模块:接收人类驾驶行为的描述性指令,例如“保持安全距离”、“平稳变道”等。3) LLM奖励生成模块:将环境信息和指令输入LLM,LLM根据这些信息生成实时的奖励信号。4) 强化学习智能体:基于生成的奖励信号,学习最优的驾驶策略。5) 策略执行模块:将学习到的驾驶策略应用于实际的自动驾驶控制。
关键创新:该方法的核心创新在于利用LLM自动生成奖励函数,避免了手动设计奖励函数的繁琐过程,并能够更好地捕捉人类驾驶的意图和偏好。与传统的基于规则或人工设计的奖励函数相比,基于LLM的奖励函数更具灵活性和适应性,能够更好地应对复杂多变的交通环境。
关键设计:关键设计包括:1) Prompt设计:精心设计的Prompt能够引导LLM生成更准确、更有效的奖励信号。Prompt需要包含清晰的指令和详细的环境描述。2) 奖励塑造:采用合适的奖励塑造策略,例如奖励代理和奖励塑造,可以加速强化学习的收敛速度,并提高智能体的性能。3) LLM选择:选择合适的LLM对于生成高质量的奖励信号至关重要。需要根据具体的应用场景和任务需求选择合适的LLM。
🖼️ 关键图片


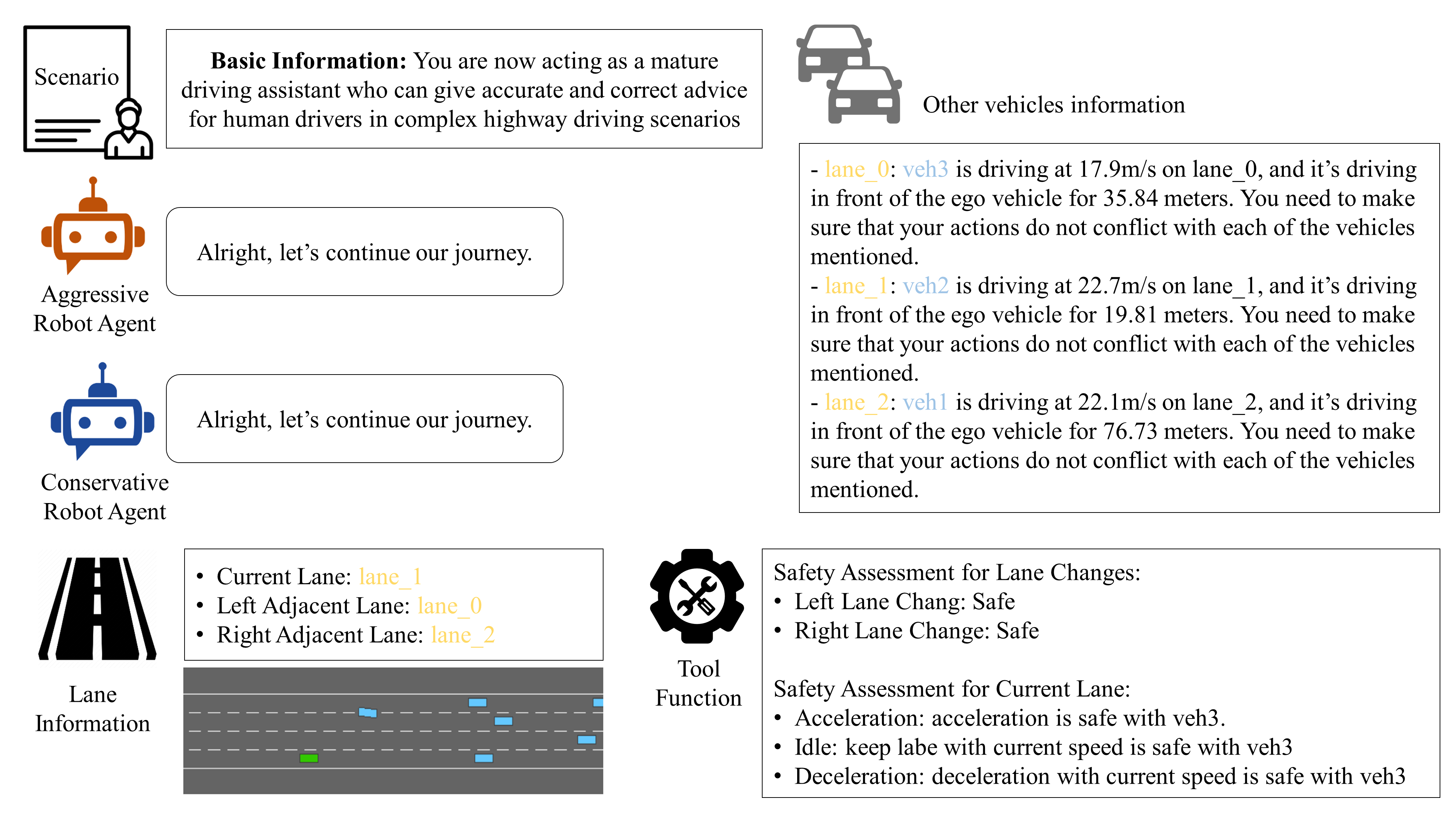
📊 实验亮点
实验结果表明,基于LLM的奖励优化方法能够显著提升自动驾驶智能体的拟人化程度和整体性能。与传统的基于规则的奖励函数相比,该方法能够使智能体学习到更自然、更流畅的驾驶策略。具体性能提升数据和对比基线信息未知,需查阅论文原文。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,例如城市道路自动驾驶、高速公路自动驾驶等。通过提升自动驾驶车辆的拟人化程度,可以提高乘客的舒适度和信任感,并减少交通事故的发生。此外,该方法还可以应用于其他机器人控制领域,例如无人机控制、机器人导航等。
📄 摘要(原文)
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach that uses large language models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also achieves better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced, human-like automated driving systems. Our experimental data and source code can be found here