CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
作者: Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2024-04-04 (更新: 2025-04-08)
💡 一句话要点
提出CodeEditorBench以评估大型语言模型的代码编辑能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码编辑 大型语言模型 评估框架 软件开发 调试 翻译 润色 需求切换
📋 核心要点
- 现有方法主要集中在代码生成,缺乏对代码编辑能力的全面评估,导致无法真实反映模型在实际开发中的表现。
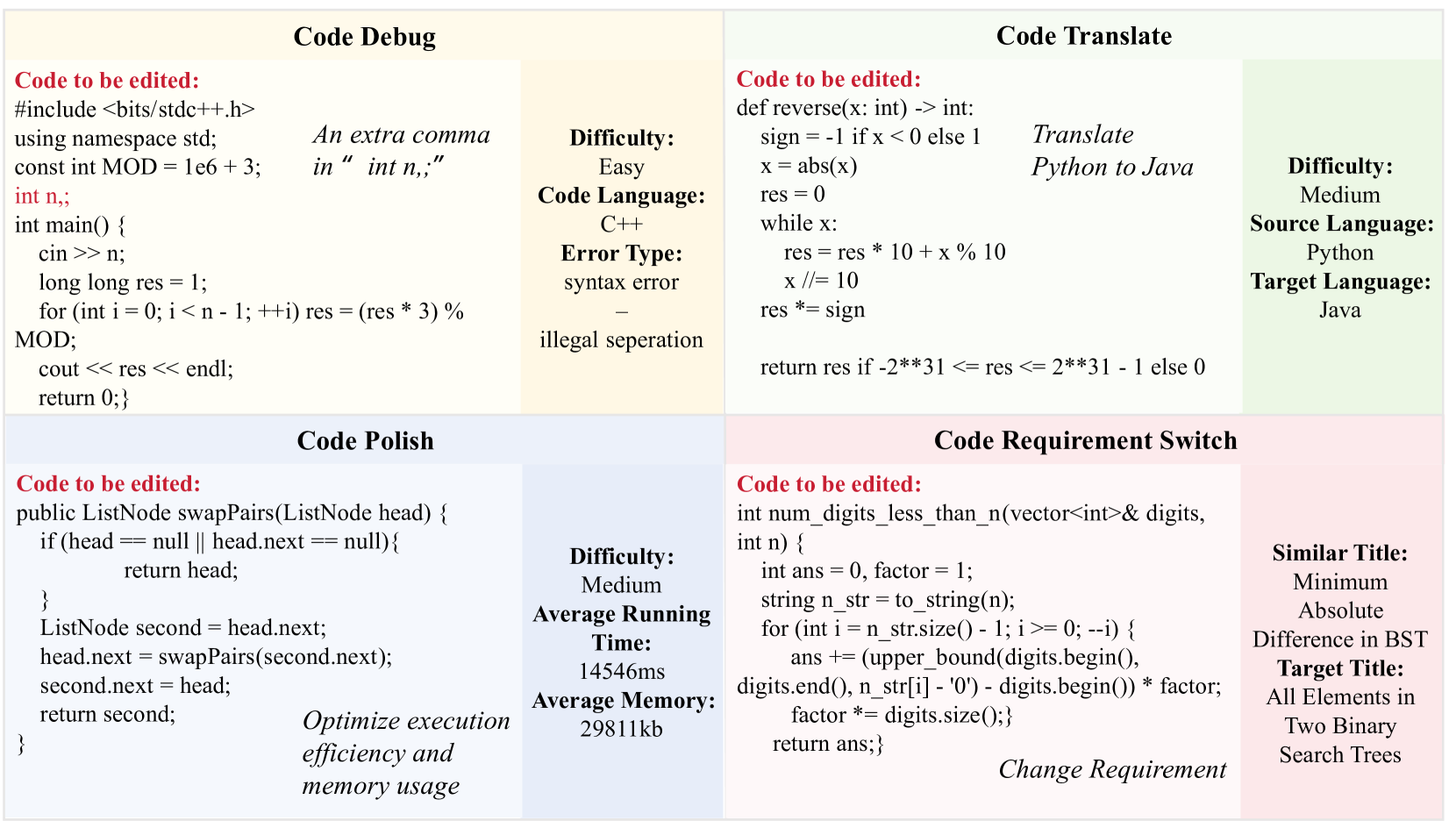
- 论文提出CodeEditorBench评估框架,专注于代码编辑任务,涵盖调试、翻译、润色等多种场景,强调真实世界的应用。
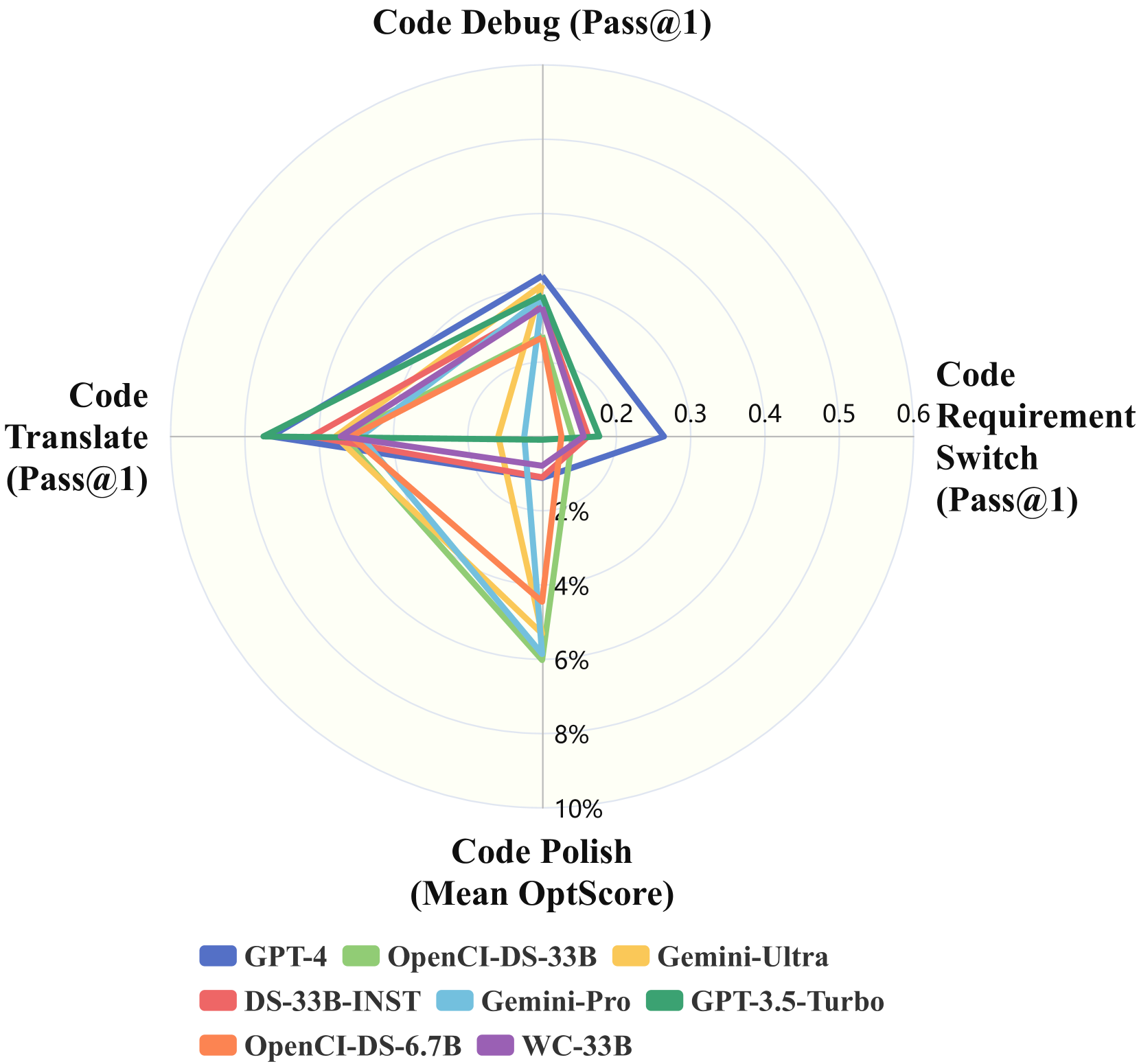
- 实验结果显示,闭源模型在CodeEditorBench中的表现优于开源模型,尤其在不同问题类型和提示敏感性方面存在显著差异。
📝 摘要(中文)
大型语言模型(LLMs)在代码处理方面迅速发展,代码编辑能力成为关键能力之一。我们提出了CodeEditorBench,一个评估框架,旨在严格评估LLMs在代码编辑任务中的表现,包括调试、翻译、润色和需求切换。与现有仅关注代码生成的基准不同,CodeEditorBench强调真实场景和软件开发的实际方面。我们从五个来源策划了多样的编码挑战和场景,涵盖多种编程语言、复杂性水平和编辑任务。对19个LLMs的评估显示,闭源模型(特别是Gemini-Ultra和GPT-4)在CodeEditorBench中表现优于开源模型,突显了模型性能在问题类型和提示敏感性上的差异。CodeEditorBench旨在通过提供一个强大的平台来促进LLMs在代码编辑能力方面的进步,并将发布所有提示和数据集,以便社区扩展数据集和基准测试新兴LLMs。
🔬 方法详解
问题定义:本论文旨在解决现有评估框架对大型语言模型在代码编辑能力评估不足的问题。现有方法多集中于代码生成,未能全面反映模型在实际开发中的应用能力。
核心思路:提出CodeEditorBench评估框架,专注于多种代码编辑任务,强调真实场景的应用,以更好地评估LLMs的实际表现。
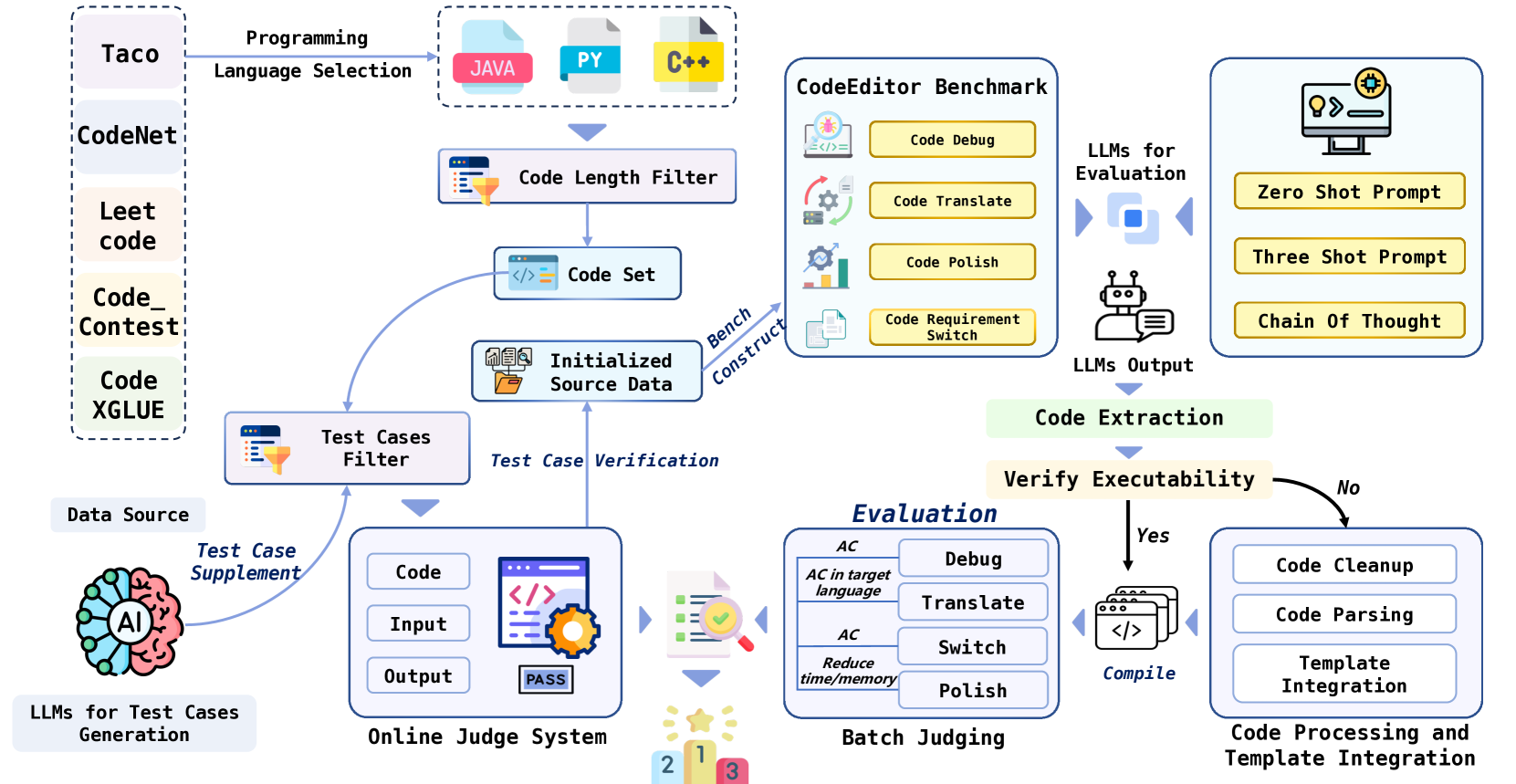
技术框架:整体架构包括任务设计、数据集构建和模型评估三个主要模块。任务设计涵盖调试、翻译、润色等多种编辑任务,数据集则从多个来源收集,确保多样性和代表性。
关键创新:最重要的创新在于将代码编辑能力的评估与真实世界的开发场景相结合,提供了一个全面的评估平台,区别于以往仅关注代码生成的基准。
关键设计:在数据集构建中,精心策划了多样的编码挑战,涵盖不同编程语言和复杂性水平,确保评估的全面性和有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,闭源模型在CodeEditorBench中的表现显著优于开源模型,尤其是Gemini-Ultra和GPT-4在多项任务中均展现出更高的准确性和效率。这一发现强调了模型性能在不同问题类型和提示敏感性上的差异,为未来的模型改进提供了重要参考。
🎯 应用场景
该研究的潜在应用领域包括软件开发、自动化测试和教育等。通过提供一个标准化的评估框架,CodeEditorBench能够帮助研究人员和开发者更好地理解和提升大型语言模型在代码编辑方面的能力,推动相关技术的进步与应用。
📄 摘要(原文)
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.