RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
作者: Detai Xin, Xu Tan, Kai Shen, Zeqian Ju, Dongchao Yang, Yuancheng Wang, Shinnosuke Takamichi, Hiroshi Saruwatari, Shujie Liu, Jinyu Li, Sheng Zhao
分类: eess.AS, cs.AI, cs.CL, cs.LG, cs.SD
发布日期: 2024-04-04 (更新: 2024-05-19)
💡 一句话要点
提出RALL-E以解决文本到语音合成中的鲁棒性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到语音合成 链式思维 鲁棒性 大型语言模型 自注意力机制
📋 核心要点
- 现有基于大型语言模型的文本到语音合成方法在鲁棒性方面存在不足,表现为音调和节奏不稳定以及较高的词错误率。
- RALL-E通过链式思维提示,将任务分解为简单步骤,首先预测音调和持续时间特征,再利用这些特征生成语音令牌。
- 实验结果显示,RALL-E在零-shot TTS的词错误率上显著优于基线方法VALL-E,错误率从5.6%降至2.5%。
📝 摘要(中文)
我们提出了RALL-E,一种用于文本到语音(TTS)合成的鲁棒语言建模方法。尽管基于大型语言模型(LLMs)的先前工作在零-shot TTS上表现出色,但这些方法往往存在鲁棒性差的问题,如音调和节奏不稳定以及较高的词错误率(WER)。RALL-E的核心思想是链式思维(CoT)提示,将任务分解为更简单的步骤,以增强基于LLM的TTS的鲁棒性。通过预测输入文本的音调和持续时间等特征,RALL-E能够更好地生成语音令牌。综合评估结果表明,与强基线方法VALL-E相比,RALL-E显著降低了零-shot TTS的WER。
🔬 方法详解
问题定义:论文旨在解决现有文本到语音合成方法在鲁棒性方面的不足,特别是音调和节奏的不稳定性以及较高的词错误率(WER)。现有方法的自回归预测风格导致了这些问题。
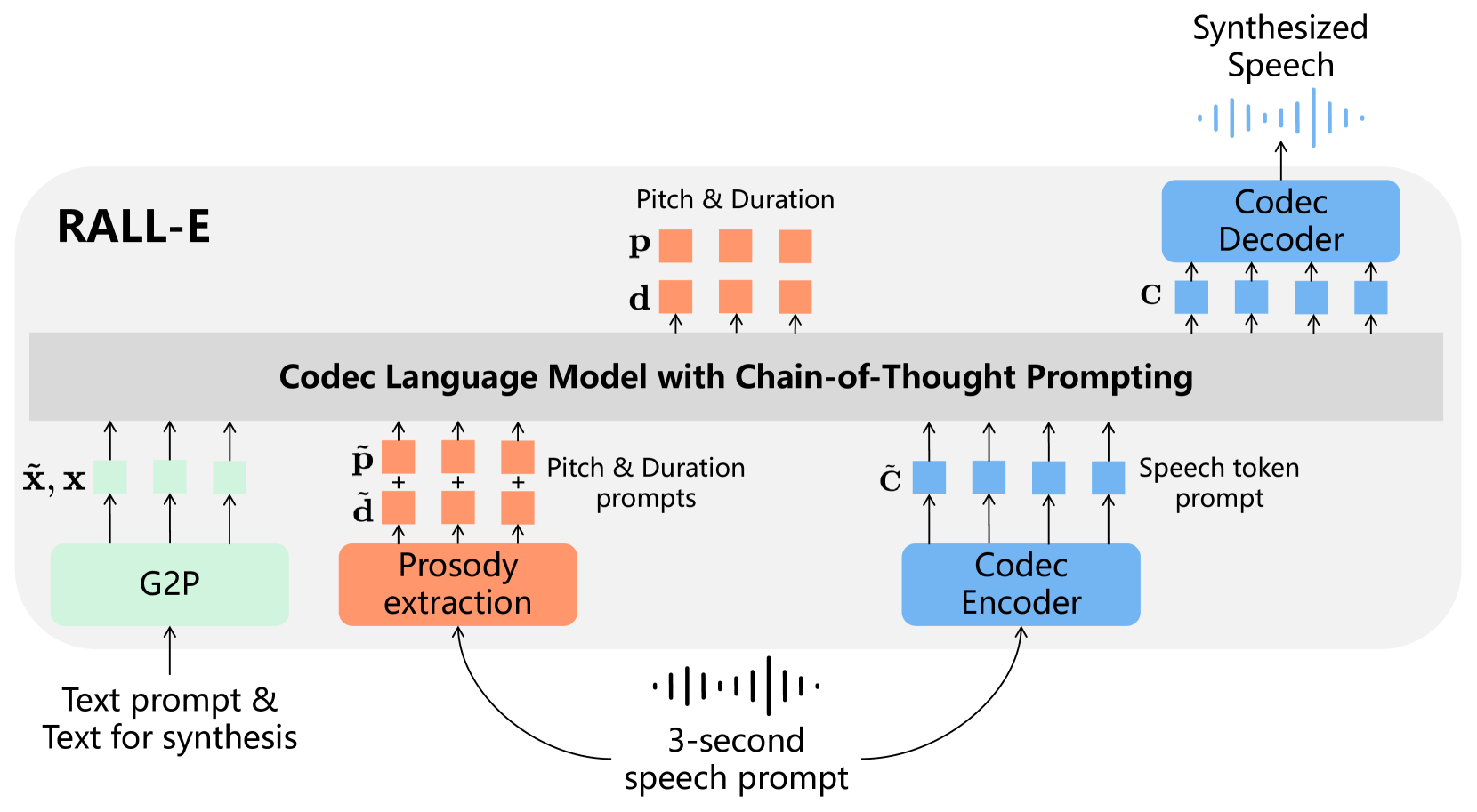
核心思路:RALL-E的核心思路是链式思维(CoT)提示,通过将复杂任务分解为更简单的步骤,增强基于大型语言模型的TTS的鲁棒性。具体而言,RALL-E首先预测输入文本的音调和持续时间特征,然后利用这些特征作为中间条件生成语音令牌。
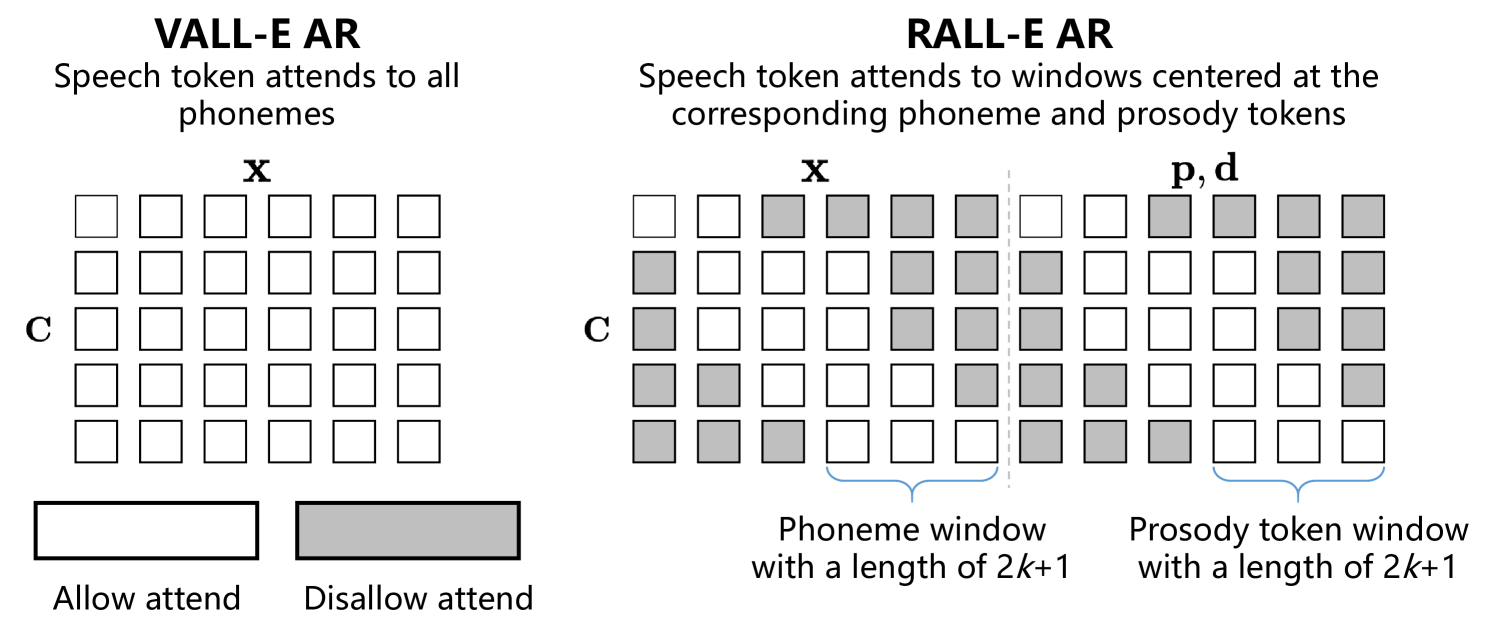
技术框架:RALL-E的整体架构包括两个主要阶段:首先是音调和持续时间特征的预测,接着是基于这些特征生成语音令牌的过程。在生成过程中,RALL-E利用预测的持续时间提示来指导Transformer中的自注意力权重计算,确保模型关注相应的音素和音调特征。
关键创新:RALL-E的主要创新在于引入链式思维提示,显著改善了文本到语音合成的鲁棒性。这一方法与传统的自回归预测方式形成了本质区别,通过分解任务来降低复杂性和提高准确性。
关键设计:在设计上,RALL-E使用了特定的损失函数来优化音调和持续时间的预测,并在Transformer架构中调整了自注意力机制,以便更好地聚焦于相关的音素和音调特征。
🖼️ 关键图片
📊 实验亮点
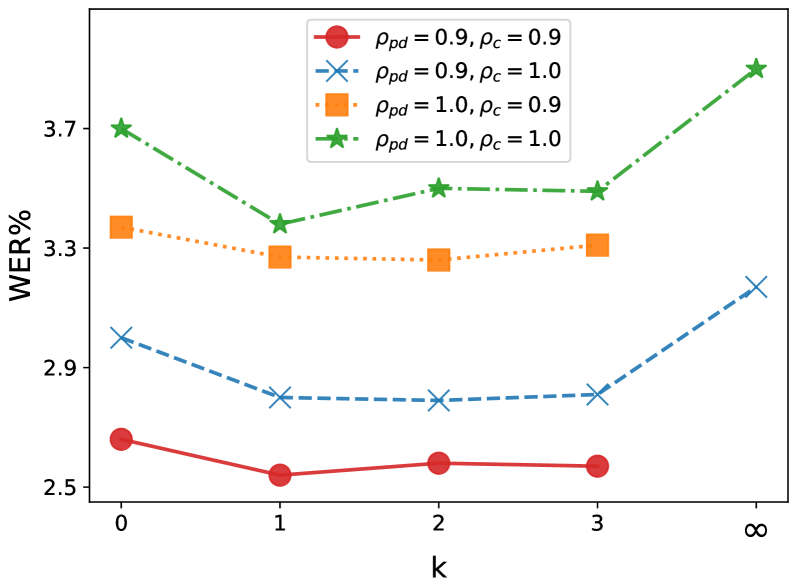
实验结果表明,RALL-E在零-shot TTS的词错误率上显著优于基线方法VALL-E,错误率从5.6%(无重排)降至2.5%(有重排),并且在处理复杂句子时,错误率从68%降至4%。
🎯 应用场景
RALL-E的研究成果在多个领域具有潜在应用价值,包括语音助手、自动配音、以及无障碍技术等。通过提高文本到语音合成的鲁棒性,该技术能够为用户提供更自然、更流畅的语音体验,尤其是在复杂或多变的语言环境中。未来,RALL-E可能会推动更广泛的语音合成应用,提升人机交互的质量。
📄 摘要(原文)
We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $5.6\%$ (without reranking) and $1.7\%$ (with reranking) to $2.5\%$ and $1.0\%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68\%$ to $4\%$.