Query Performance Prediction using Relevance Judgments Generated by Large Language Models
作者: Chuan Meng, Negar Arabzadeh, Arian Askari, Mohammad Aliannejadi, Maarten de Rijke
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2024-04-01 (更新: 2025-05-26)
备注: Accepted by ACM Transactions on Information Systems (TOIS)
DOI: 10.1145/3736402
💡 一句话要点
提出QPP-GenRE框架以解决查询性能预测中的相关性判断问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 查询性能预测 相关性判断 信息检索 大型语言模型 深度学习 伪标签 性能优化
📋 核心要点
- 现有的QPP方法通常只返回单一的标量值,无法有效表示不同的IR评估指标,导致解释性不足。
- 本文提出的QPP-GenRE框架通过将QPP分解为独立的子任务,利用自动生成的相关性判断来预测任意IR评估指标。
- 在TREC 2019至2022深度学习轨道和CAsT-19、20数据集上的实验表明,QPP-GenRE在QPP质量上达到了最先进水平。
📝 摘要(中文)
查询性能预测(QPP)旨在在没有人工相关性判断的情况下估计搜索系统对查询的检索质量。现有QPP方法通常返回单一标量值,无法准确表示不同的信息检索(IR)评估指标,导致解释性不足。为了解决这些问题,本文提出了一种使用自动生成的相关性判断的QPP框架(QPP-GenRE),将QPP分解为独立的子任务,从而能够使用生成的相关性判断作为伪标签预测任意IR评估指标。通过使用开源的大型语言模型(LLMs)来预测项目的相关性,确保了科学的可重复性。实验结果表明,QPP-GenRE在词汇和神经排序器上均实现了最先进的QPP质量。
🔬 方法详解
问题定义:本文旨在解决现有QPP方法无法有效表示不同IR评估指标的问题,尤其是单一标量值的局限性,导致解释性不足和准确性下降。
核心思路:提出QPP-GenRE框架,通过将QPP分解为独立的子任务,利用自动生成的相关性判断作为伪标签,从而能够预测任意IR评估指标,并提高结果的可解释性。
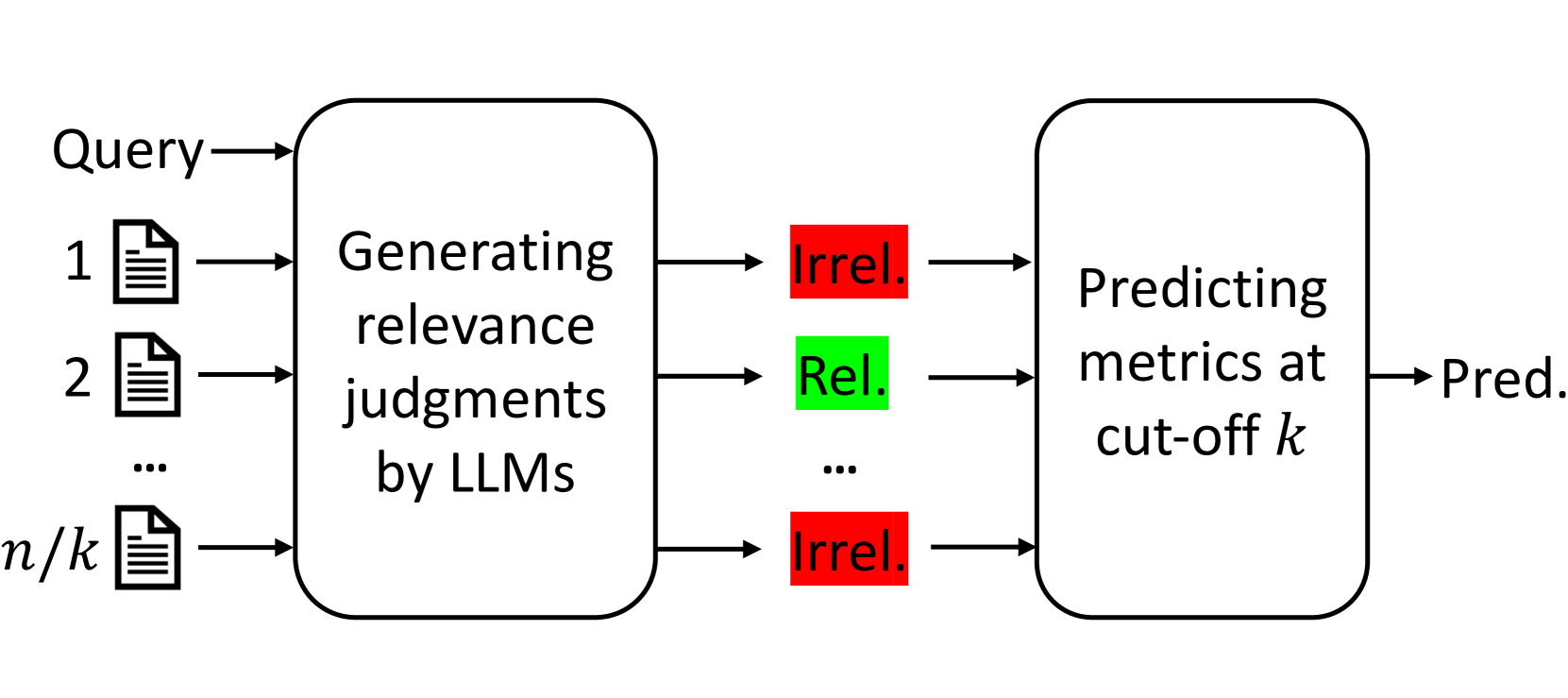
技术框架:整体架构包括生成相关性判断的模块、预测相关性和评估IR指标的模块。首先使用开源LLMs生成相关性判断,然后基于这些判断进行IR评估指标的预测。
关键创新:最重要的创新在于将QPP问题分解为多个子任务,并使用生成的相关性判断作为伪标签,这与传统方法的单一标量预测方式有本质区别。
关键设计:在模型设计中,采用了开源LLMs进行相关性判断的生成,并通过人类标注的相关性判断对模型进行微调,以解决在零样本/少样本情况下的性能限制。
🖼️ 关键图片

📊 实验亮点
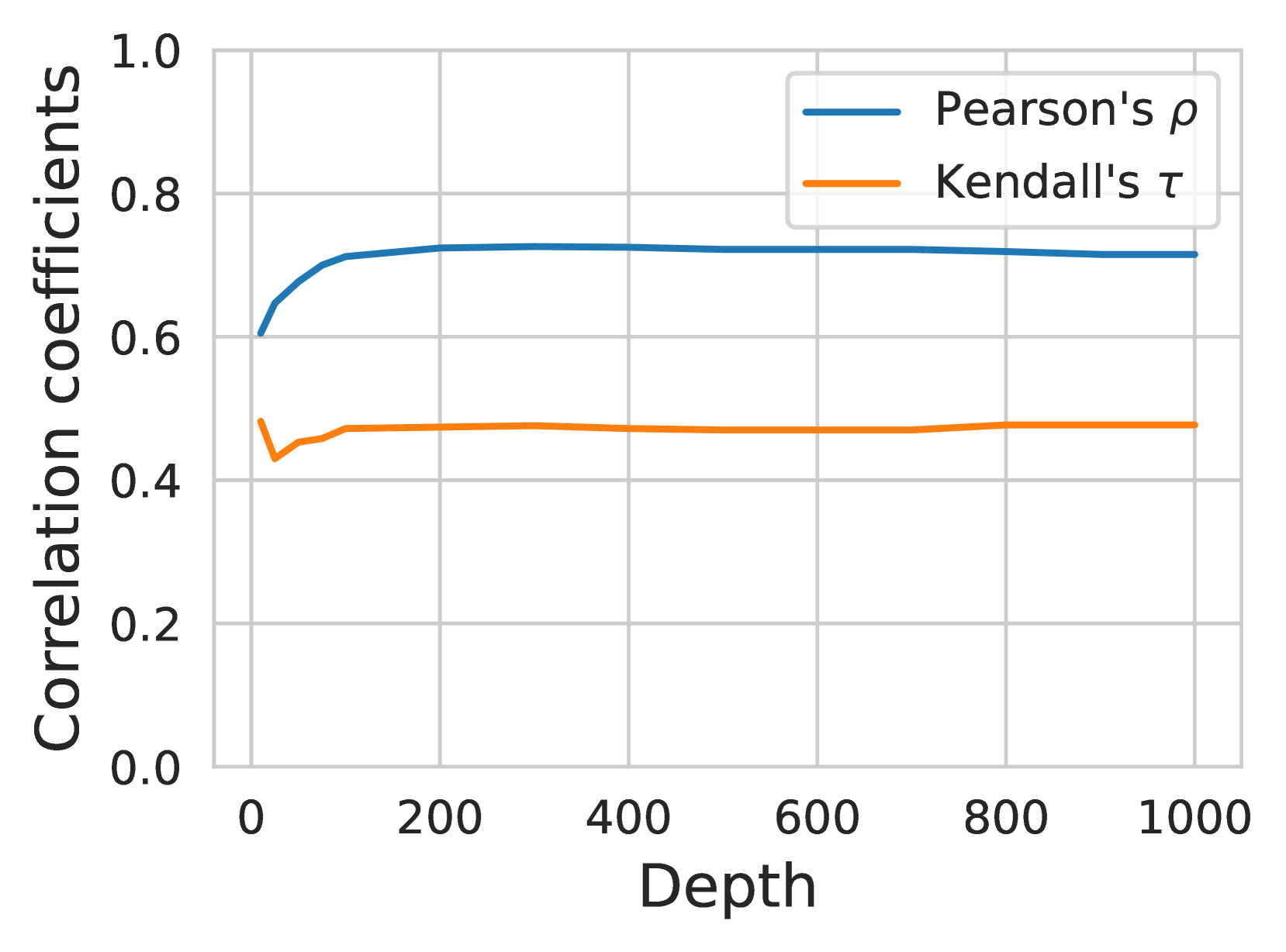
实验结果显示,QPP-GenRE在TREC 2019至2022深度学习轨道和CAsT-19、20数据集上达到了最先进的QPP质量,相较于基线方法有显著提升,具体性能数据未提供,但提升幅度显著。
🎯 应用场景
该研究的潜在应用领域包括信息检索系统的性能优化、搜索引擎的相关性评估以及推荐系统的效果提升。通过提供更准确的查询性能预测,能够显著改善用户体验和系统效率,未来可能在商业搜索和学术研究中发挥重要作用。
📄 摘要(原文)
Query performance prediction (QPP) aims to estimate the retrieval quality of a search system for a query without human relevance judgments. Previous QPP methods typically return a single scalar value and do not require the predicted values to approximate a specific information retrieval (IR) evaluation measure, leading to certain drawbacks: (i) a single scalar is insufficient to accurately represent different IR evaluation measures, especially when metrics do not highly correlate, and (ii) a single scalar limits the interpretability of QPP methods because solely using a scalar is insufficient to explain QPP results. To address these issues, we propose a QPP framework using automatically generated relevance judgments (QPP-GenRE), which decomposes QPP into independent subtasks of predicting the relevance of each item in a ranked list to a given query. This allows us to predict any IR evaluation measure using the generated relevance judgments as pseudo-labels. This also allows us to interpret predicted IR evaluation measures, and identify, track and rectify errors in generated relevance judgments to improve QPP quality. We predict an item's relevance by using open-source large language models (LLMs) to ensure scientific reproducibility. We face two main challenges: (i) excessive computational costs of judging an entire corpus for predicting a metric considering recall, and (ii) limited performance in prompting open-source LLMs in a zero-/few-shot manner. To solve the challenges, we devise an approximation strategy to predict an IR measure considering recall and propose to fine-tune open-source LLMs using human-labeled relevance judgments. Experiments on the TREC 2019 to 2022 deep learning tracks and CAsT-19 and 20 datasets show that QPP-GenRE achieves state-of-the-art QPP quality for both lexical and neural rankers.